Искусственный интеллект: Нелинейный разум
Новое исследование ставит под сомнение традиционные представления о развитии искусственного интеллекта, предсказывая появление принципиально отличных от человеческого форм разума.
Новое исследование ставит под сомнение традиционные представления о развитии искусственного интеллекта, предсказывая появление принципиально отличных от человеческого форм разума.

Исследователи разработали метод, позволяющий значительно ускорить процесс создания трехмерных моделей из обычных фотографий.
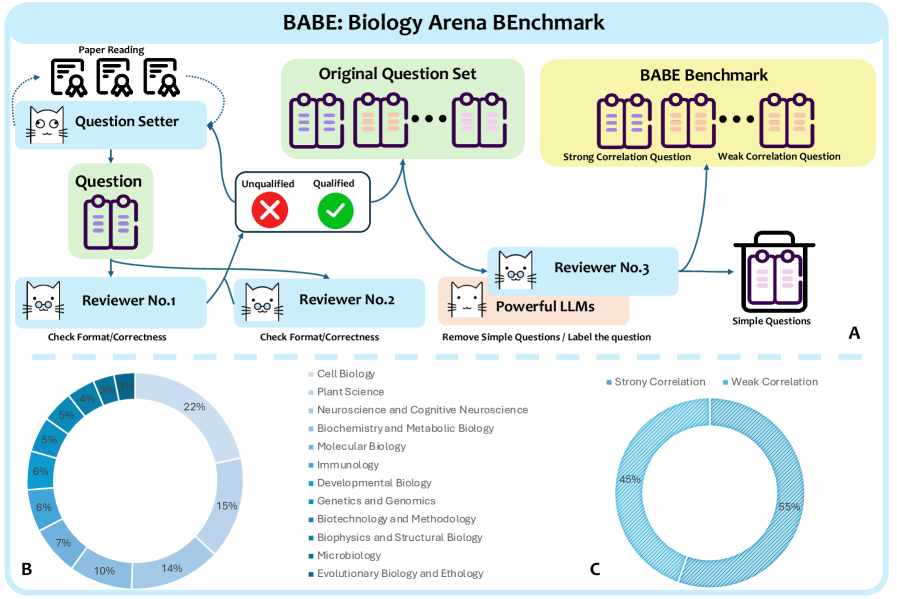
Ученые представили BABE — комплексный тест, позволяющий оценить способность искусственного интеллекта к логическому мышлению и анализу биологических данных.
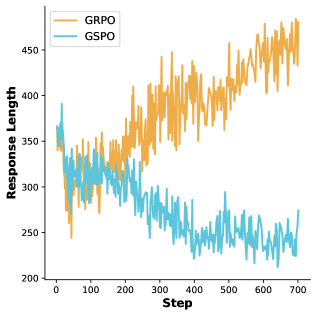
Новый алгоритм LUSPO позволяет снизить зависимость от длины генерируемых текстов, повышая стабильность и эффективность обучения больших языковых моделей.
Новое исследование выявляет слабые места современных ИИ-систем в самостоятельном поиске информации и проверке достоверности данных в интернете.
Новое исследование показывает, что современные модели, обрабатывающие изображения и текст, часто нарушают контекстную целостность и раскрывают конфиденциальную информацию о местоположении.
Исследователи предлагают набор сложных математических задач, разработанных для оценки способности ИИ решать проблемы на уровне передовых научных исследований.
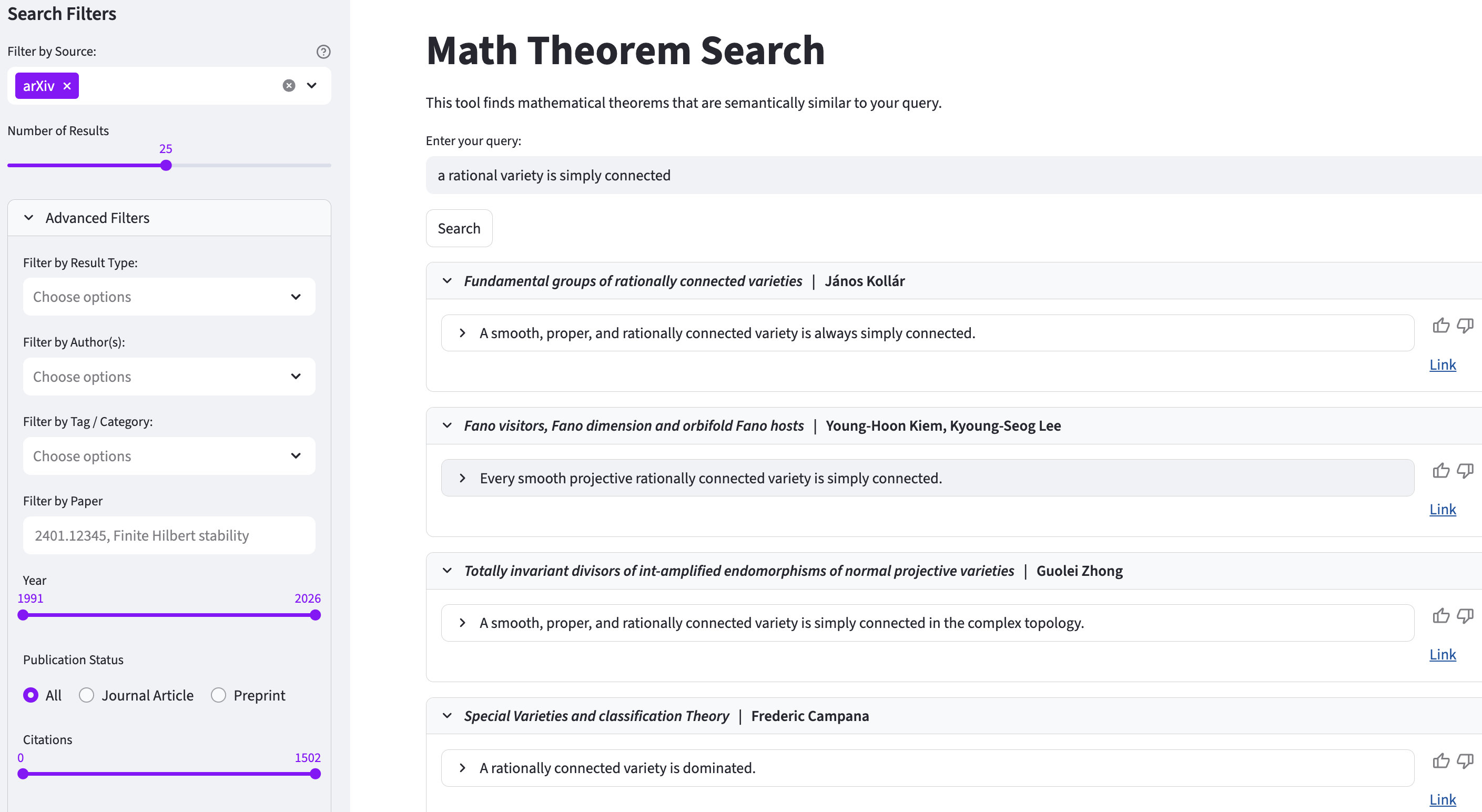
Новая система позволяет находить математические теоремы, опираясь на смысл их формулировок, а не только на ключевые слова.
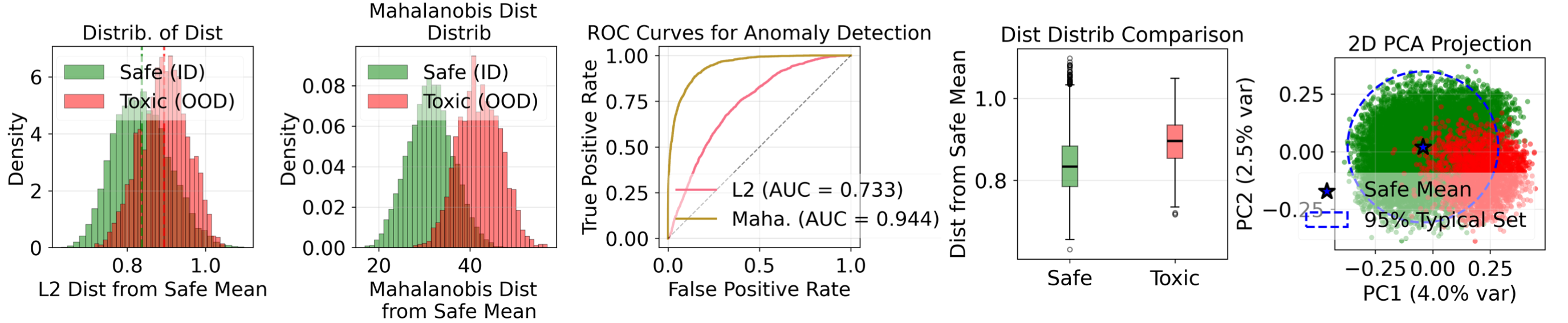
Исследователи предлагают перейти от реактивного поиска вредоносных шаблонов к проактивному выявлению статистически атипичных данных для повышения безопасности больших языковых моделей.
Новая система искусственного интеллекта позволяет ученым создавать и редактировать молекулярные структуры, используя обычный язык.