Искры интеллекта: Стратегическое исследование в обучении агентов

Новый подход к обучению с подкреплением позволяет агентам более эффективно осваивать сложные долгосрочные задачи, используя динамическое ветвление стратегий исследования.
Новый подход к обучению с подкреплением позволяет агентам более эффективно осваивать сложные долгосрочные задачи, используя динамическое ветвление стратегий исследования.
В данной статье рассматривается перспектива объединения достижений нейронауки и искусственного интеллекта для создания более эффективных, надежных и адаптивных систем.
![В архитектуре GDCNet модуль gated мультимодального объединения и классификации интегрирует признаки несоответствия [latex]FDF_{D}[/latex], текста [latex]FTF_{T}[/latex] и изображения [latex]FIF_{I}[/latex] для формирования объединенного представления [latex]FfusedF_{\text{fused}}[/latex].](https://arxiv.org/html/2601.20618v1/x2.png)
Новая модель GDCNet использует возможности больших языковых моделей для выявления скрытого сарказма, анализируя расхождения между текстом и изображениями.
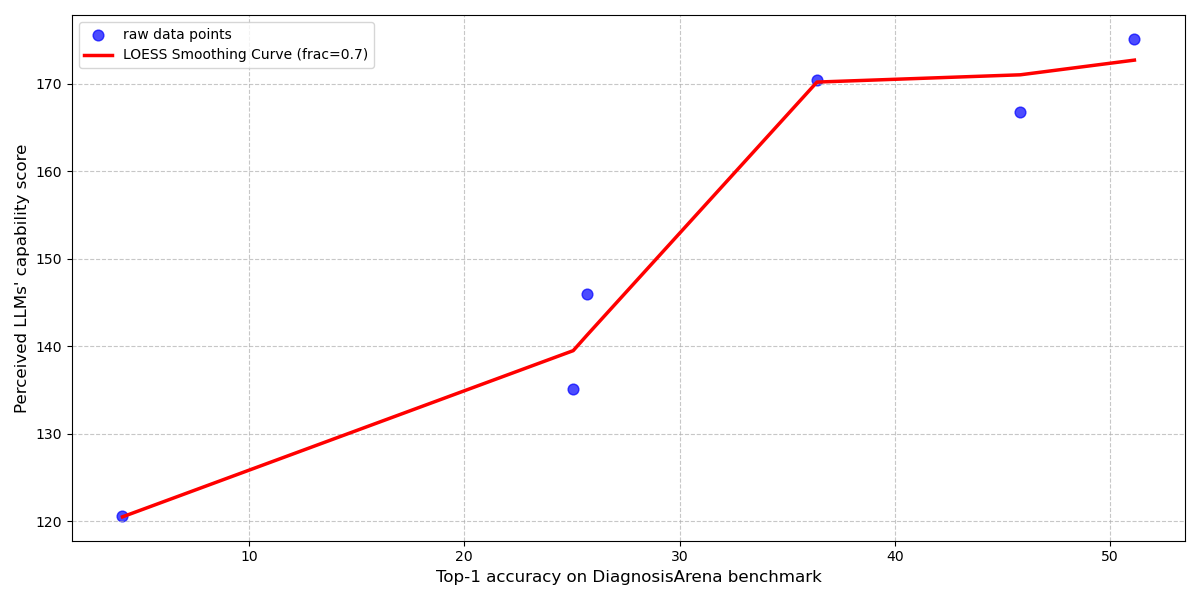
Новое исследование показывает, что восприятие врачами возможностей больших языковых моделей играет ключевую роль в эффективности совместной работы и принятии клинических решений.

Новый подход к непрерывному обучению позволяет моделям сохранять знания, приобретенные на предыдущих этапах, при освоении новых задач.

Исследователи представляют Youtu-VL, модель, которая демонстрирует впечатляющие результаты благодаря переходу от текстового до визуального контроля в процессе обучения.
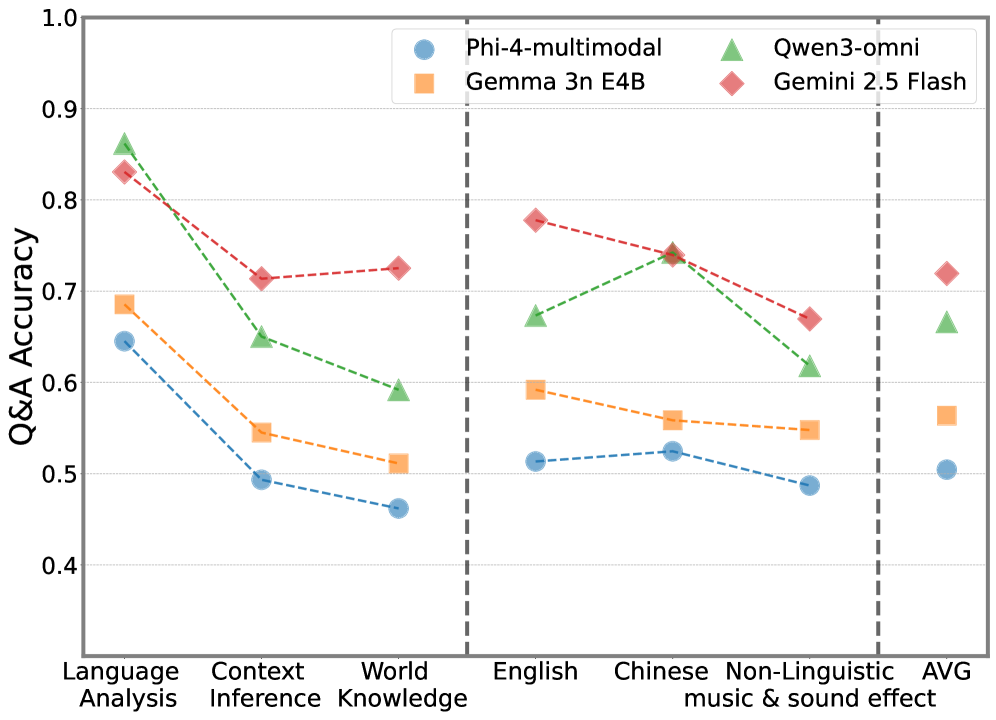
Новый тест AVMeme Exam демонстрирует, что современные модели искусственного интеллекта испытывают трудности с пониманием юмора и культурного контекста в многоязычных аудиовизуальных мемах.
Новое исследование показывает, что современные мультимодальные модели способны к точному определению границ объектов на изображениях, используя простой подход к предсказанию ключевых точек.
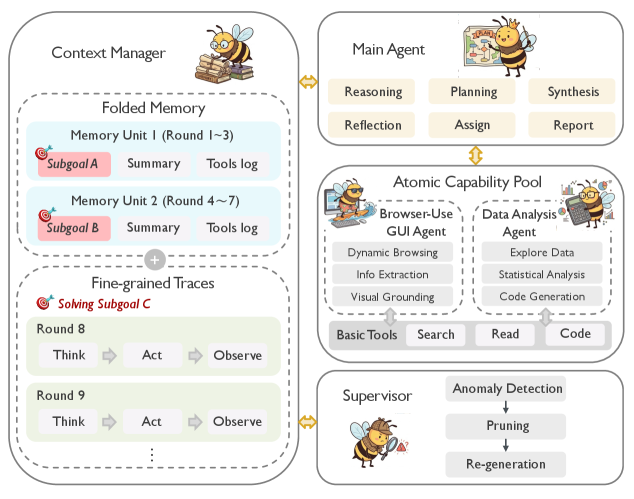
В статье представлена новая иерархическая платформа для организации и проведения глубоких исследований, способная эффективно решать долгосрочные и многогранные задачи.
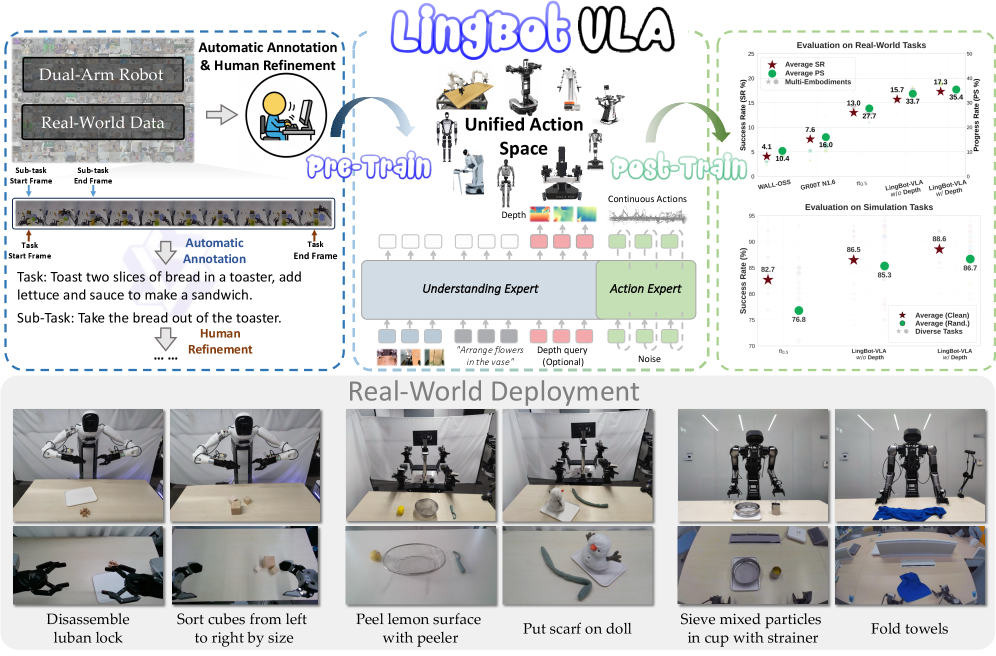
Представлена LingBot-VLA — модель, объединяющая зрение, язык и действия, обученная на огромном массиве реальных данных и демонстрирующая впечатляющую обобщающую способность.