Роботы, которые понимают время: Новый подход к управлению манипуляторами

Исследователи разработали модель VLA-4D, позволяющую роботам более эффективно планировать и выполнять сложные манипуляции, учитывая не только пространство, но и время.
Исследователи разработали модель VLA-4D, позволяющую роботам более эффективно планировать и выполнять сложные манипуляции, учитывая не только пространство, но и время.

В статье представлена архитектура MirrorMind, призванная расширить возможности ИИ в области научных исследований и открытий.

Новая система WorldGen позволяет преобразовывать текстовые описания в детализированные и проходимые трехмерные миры, открывая новые горизонты для игровых движков и виртуальной реальности.
Статья исследует новаторский подход к обучению искусственному интеллекту в музыке, акцентируя внимание на критическом осмыслении и творческом эксперименте.
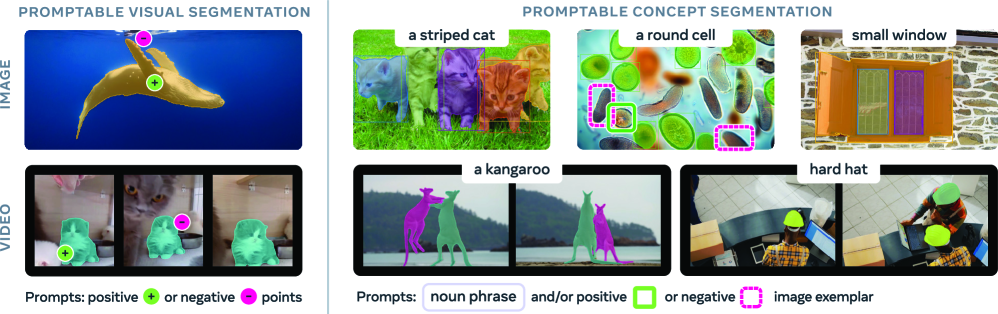
Новая модель SAM 3 и бенчмарк SA-Co открывают возможности для точной сегментации изображений и видео, основываясь на концептуальных запросах.
Новое поколение ИИ-систем требует интеграции принципов многоагентных систем для достижения истинной ответственности и предсказуемости.

В статье представлена концепция комплексной системы, объединяющей возможности искусственного интеллекта и традиционную научную инфраструктуру для совершения открытий и проведения экспериментов.

Исследователи предлагают инновационный метод динамической регуляции энтропии в процессе обучения больших языковых моделей, обеспечивающий более стабильные и предсказуемые результаты.
Новый подход к обеспечению надежности и энергоэффективности сложных технических систем в условиях онлайн-обучения и изменяющихся условий.

Исследователи разработали метод, позволяющий роботам использовать опыт успешного выполнения задач для более эффективного обучения и улучшения навыков.