Умный дом: Искусственный интеллект на службе энергоэффективности
![Разработана концептуальная основа для создания человеко-ориентированного агента искусственного интеллекта для системы управления энергопотреблением зданий, использующего большие языковые модели [latex]LLM[/latex].](https://arxiv.org/html/2512.25055v1/x1.png)
Новый подход к управлению энергопотреблением в зданиях использует возможности больших языковых моделей для создания адаптивных и удобных систем.
Новый подход к управлению энергопотреблением в зданиях использует возможности больших языковых моделей для создания адаптивных и удобных систем.

Ученые разработали метод, позволяющий создавать более правдоподобные видеоролики по текстовому описанию, учитывая законы физики.

Новая система CASCADE позволяет агентам на базе больших языковых моделей не просто использовать инструменты, а самостоятельно приобретать и совершенствовать научные навыки, приближая автоматизацию исследовательского процесса.
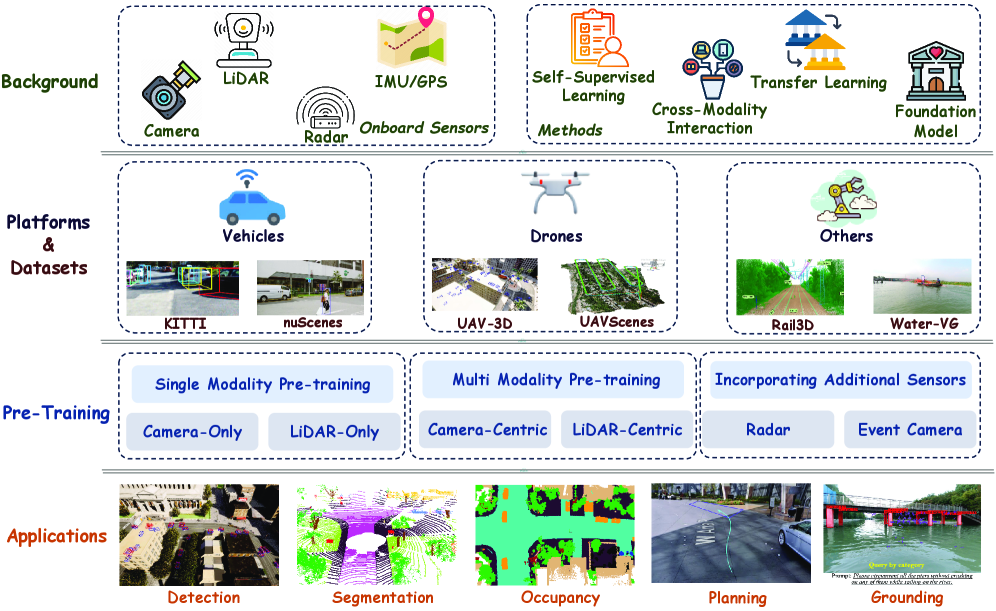
Обзор современных методов мультимодального предварительного обучения, открывающих новые возможности для создания надежных автономных систем.
Обзор посвящен стремительному развитию методов искусственного интеллекта, автоматизирующих подготовку геометрии и построение сеток для инженерных симуляций.

Исследователи предлагают инновационную систему, объединяющую визуальное конструирование и языковые модели для улучшения логического мышления и решения математических задач.

Новое исследование показывает, что внутренние представления сложных моделей прогноза погоды можно интерпретировать, раскрывая, как они ‘видят’ физические процессы.
![В исследовании продемонстрировано, что внутренняя навигация позволяет эффективно устранять выбросы, возникающие при использовании недостаточно обученных моделей диффузии шумоподавления, и ускорять сходимость обучения, превосходя по эффективности существующие методы, такие как REPA[yu2024representation], в экспериментах SiT-B/2.](https://arxiv.org/html/2512.24176v1/x4.png)
Исследователи предлагают эффективный метод улучшения качества и скорости генерации изображений с помощью Diffusion Transformers, используя внутренние сигналы самой модели.

В статье рассматривается переход от создания правдоподобных результатов к проектированию автономных систем с гарантированной надежностью, устойчивостью и безопасностью благодаря интеграции принципов операционных исследований и генеративного ИИ.

Новая система GR-Dexter объединяет продвинутую роботизированную руку, модели обработки зрения и языка, и данные, полученные от операторов-людей, для выполнения сложных задач манипулирования.