Поиск неисправностей в коде: новый подход на основе причинно-следственных связей

Исследователи разработали метод, использующий анализ графов причинно-следственных связей для более точной локализации проблем в больших кодовых базах.
Исследователи разработали метод, использующий анализ графов причинно-следственных связей для более точной локализации проблем в больших кодовых базах.

Представлен HiSciBench — комплексный инструмент для оценки способности искусственного интеллекта понимать, анализировать и синтезировать научные знания в различных областях.
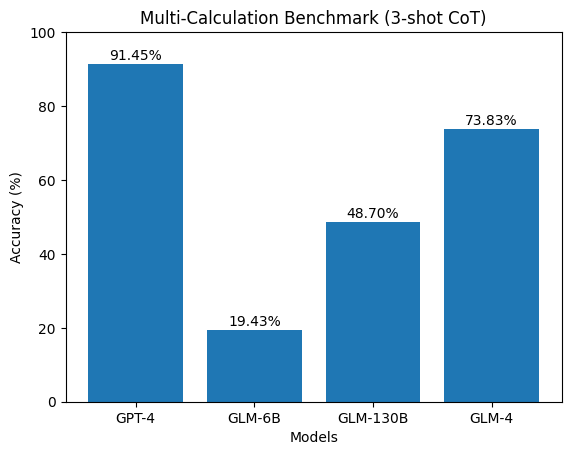
Новое исследование показывает, что большие языковые модели испытывают трудности с решением сложных бухгалтерских задач, несмотря на общие навыки рассуждения.
Новая система, основанная на анализе научной литературы, позволяет автоматически выявлять микроорганизмы, участвующие в производстве ценных нутрицевтических соединений.
Новая модель DreamOmni3 позволяет пользователям управлять процессом создания и редактирования изображений, используя простые наброски и текстовые подсказки.
Статья предлагает новый подход к оценке эмоционального интеллекта в искусственном интеллекте, выходящий за рамки простых рейтингов и ориентированный на этическую безопасность.

Новая разработка позволяет обучать хирургических роботов сложным манипуляциям, используя синтетические данные и моделирование реального мира.

Новая система AI4Reading использует возможности искусственного интеллекта для автоматической генерации интерпретативных аудиокниг, открывая новые горизонты в создании и распространении контента.

Исследователи представили комплексную платформу для оценки способности ИИ-агентов проводить глубокий анализ видеоконтента в интернете и использовать полученные знания для решения сложных задач.

Новая система ResearchPlanGen способна автоматически генерировать обоснованные планы научных исследований, используя самообучение и оценку по заданным критериям.