Умная Квантизация: Новый Подход к Оптимизации Трансформеров
![Предложенная методика QuEPT калибрует матрицу компенсации низкого ранга [latex]\bm{R}[/latex] и параметры обрезки весов [latex]\bm{\alpha}[/latex] и [latex]\bm{\beta}[/latex] при блочной реконструкции, сохраняя веса [latex]\bm{W}[/latex] и масштаб квантования [latex]\bm{S}[/latex] фиксированными, при этом процесс реконструкции состоит из двух этапов: объединения многобитных признаков из разных групп с помощью Multi-Bit Token Merging (MB-ToMe) и оптимизации многобитной квантованной ошибки посредством Multi-Bit Cascaded Low-Rank Adapters (MB-CLoRA).](https://arxiv.org/html/2602.12609v1/x1.png)
Исследователи представили QuEPT — инновационную методику квантизации, позволяющую значительно повысить эффективность и снизить вычислительные затраты моделей искусственного интеллекта.
Исследователи представили QuEPT — инновационную методику квантизации, позволяющую значительно повысить эффективность и снизить вычислительные затраты моделей искусственного интеллекта.
Новый подход, вдохновленный квантовой прогулкой, позволяет оптимизировать сжатие изображений в формате JPEG, повышая качество без увеличения вычислительной сложности.
![Обучение модели NBF с варьирующимися параметрами отбора [latex]n_{select}[/latex] и количества сэмплов [latex]n_{sample}[/latex] позволило получить отсортированные вероятностные амплитуды, сопоставимые с точным решением методом Монте-Карло для молекулы N₂ в базисе STO-3G и с использованием каноничных HF-орбиталей, содержащих в общей сложности 14 400 конфигураций.](https://arxiv.org/html/2602.12993v1/figure1.png)
Исследование демонстрирует, что комбинация нейронных квантовых состояний и метода выбранного взаимодействия конфигураций превосходит традиционные методы вариационного Монте-Карло в задачах квантовой химии.
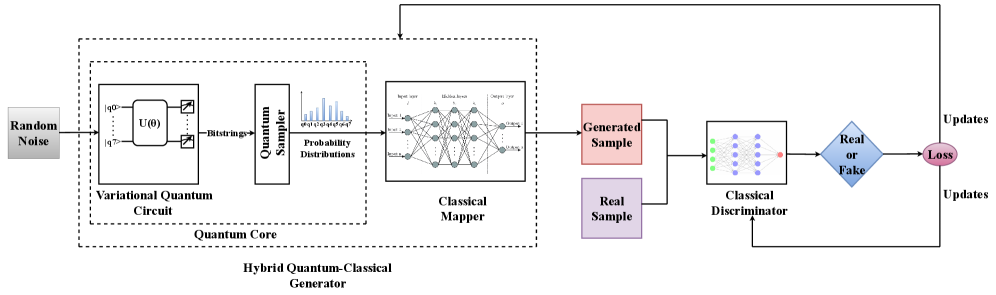
Исследователи представили QTabGAN — гибридную квантово-классическую модель, способную генерировать синтетические данные, превосходящие существующие методы по качеству и реалистичности.
![В двухуровневой системе, нерезонансное геометрическое управление, характеризующееся наклоном статического магнитного поля [latex]\vartheta[/latex] к плоскости управляющих полей и фазой [latex]\phi_{y}=-\pi/2[/latex], индуцирует колебания Раби, демонстрируя полное инвертирование популяции возбужденных состояний как вблизи резонанса [latex]\omega_{d}=\omega_{L}[/latex], так и в режиме [latex]\omega_{d} \gg \omega_{L}[/latex], с зависимостью амплитуды колебаний, обратно пропорциональной частоте Лармора [latex]\sim 1/\omega_{L}[/latex].](https://arxiv.org/html/2602.11979v1/x1.png)
Исследователи представили метод нерезонансного управления квантовыми состояниями, основанный на использовании геометрических фаз и позволяющий индуцировать полные колебания Раби без необходимости точного нацеливания на резонансные частоты.

Новый подход к построению аппаратных ускорителей глубокого обучения обеспечивает высокую производительность и энергоэффективность за счет трехмерной организации данных и оптимизации доступа к памяти.
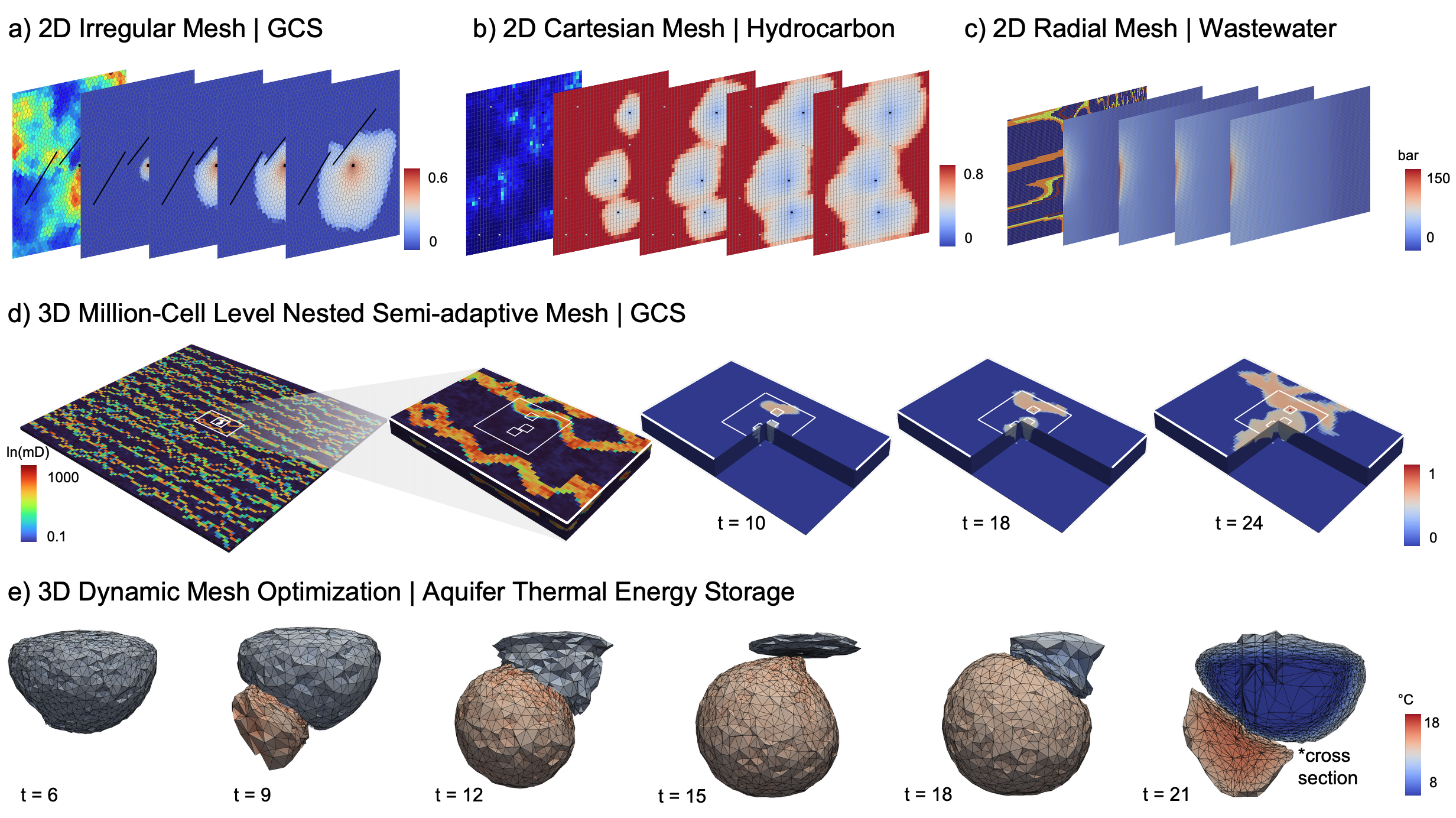
Ученые разработали инновационный подход к моделированию сложных процессов в недрах земли, позволяющий значительно повысить точность и скорость расчетов.
Исследование подтверждает, что значение параметра n в шестимерной супергравитации на пространстве AdS₃ × S³ строго ограничено числом 21, укрепляя связь с фундаментальными принципами строковой теории.
![Сравнительный анализ распределений выходных сигналов 20-го слоя модели Qwen3-30B-A3B демонстрирует различия в средних μ и дисперсиях [latex] \sigma^2 [/latex] между представлением с плавающей точкой (FP), прямым квантованием (Direct VQ) и разреженным квантованием с использованием Mixture-of-Experts (KBVQ-MoE), выявляя влияние методов квантования на статистические свойства внутренних представлений модели.](https://arxiv.org/html/2602.11184v1/img/fig-motivation_post_process.png)
Исследователи разработали метод, позволяющий значительно уменьшить размер моделей, состоящих из множества экспертов, практически не теряя при этом точности.
![Эффективность идентификации [latex]\tau\text{-лептонов}[/latex] в эксперименте, смоделированном для поиска распадов [latex]H \to \tau\tau[/latex] и сигналов новой физики [latex]Z'\to \tau\tau[/latex], демонстрирует зависимость от поперечного импульса [latex]p_T[/latex] и псевдо-быстроты η реконструированных кандидатов, при этом точность оценки ограничена статистикой доступных событий и шириной интервалов, а вклад неучтенных нейтрино влияет на наблюдаемую видимую энергию.](https://arxiv.org/html/2602.11359v1/x4.png)
В статье описывается усовершенствование системы высокоуровневых триггеров детектора CMS для более эффективной идентификации адронно распадающихся тау-лептонов.