Автор: Денис Аветисян

Все давно устали от того, что оценка социально-экономического положения городов – долгий, дорогой и не всегда точный процесс, особенно когда речь заходит о сравнении разных регионов и оперативном реагировании на изменения. Но что, если вместо бесконечных таблиц и опросов, можно было бы «научить» компьютер видеть город глазами эксперта? Именно эту задачу ставит перед собой работа “CityRiSE: Reasoning Urban Socio-Economic Status in Vision-Language Models via Reinforcement Learning”, предлагая использовать мощь больших языковых моделей и обучение с подкреплением. Но действительно ли можно доверить анализ сложной городской жизни алгоритму, который, по сути, лишь «смотрит» на картинки и пытается угадать, что происходит, не превратившись в очередной «черный ящик», выдающий цифры без объяснений?
Городская Мозаика: Когда Данные Кричат, а Мы Молчим
Оценка социально-экономического положения городов – краеугольный камень эффективного градостроительства. Но давайте будем честны: традиционные методы сбора данных – это медленно, дорого, и, главное, они дают картинку в масштабе, который уже не соответствует реальности. Словно пытаешься собрать мозаику из фотографий, сделанных с вертолета, когда нужно видеть трещины на асфальте. И вот, как обычно, всё сводится к попыткам выжать максимум из ограниченных ресурсов.
Существующие подходы, мягко говоря, не блещут способностью к обобщению. Перенесли модель из одного города в другой – и всё, привет, ошибка. Как будто каждый город – это отдельный вид, требующий уникального алгоритма. А попытки предсказать один показатель, а потом применить ту же модель к другому? Забудьте. И вот уже начинается игра в перекладывание ответственности: «Это данные плохие», «Модель не настроена», «Нужно больше ресурсов». Старая песня, знаете ли.
И тут на сцену выходит визуальный контент, в частности, изображения с уличных камер. Звучит многообещающе, масштабируемо, дешево. Но, разумеется, дьявол кроется в деталях. Просто смотреть на картинки недостаточно. Нужны инструменты, которые смогут извлечь из этого потока информации что-то полезное, что-то, что можно использовать для принятия решений. И вот тут начинаются танцы с шаманами и нейронными сетями.
В итоге, мы получаем очередную «революционную» технологию, которая на самом деле является просто переупаковкой старых идей. Документация, как всегда, врёт, обещая золотые горы, а на практике приходится бороться с техническим долгом, который накапливается быстрее, чем успеваешь его исправлять. И, конечно, кто-то обязательно назовёт это AI и получит инвестиции. А потом окажется, что всё это время мы просто изобретали велосипед, который, к тому же, сломан.
Впрочем, ладно. Давайте посмотрим, что у нас там в логах. Наверное, опять кто-то что-то сломал.
CityRiSE: Иллюзия Масштабируемости или Реальный Шаг Вперёд?
В последнее время наблюдается нездоровый культ «масштабируемости». Кажется, что каждый новый алгоритм, каждая новая архитектура, разрабатываются с расчётом на некий абстрактный, никогда не наступающий «масштаб». Однако, в реальной жизни, в реальных проектах, рано или поздно всё упирается в простые вещи: надёжность, точность, и, да, хоть это и прозвучит старомодно, – простота. Исследователи, представленные в данной работе, предлагают подход к пониманию городской среды, который, на первый взгляд, может показаться сложным, но, если присмотреться, базируется на вполне понятных принципах.
CityRiSE – это система, построенная на базе большой языковой модели, способной обрабатывать и интерпретировать визуальную информацию из уличных изображений. Идея не нова, но реализация заслуживает внимания. Вместо того, чтобы пытаться изобрести очередную, «революционную» архитектуру, авторы взяли за основу существующую, проверенную временем модель, и научили её видеть то, что действительно важно для понимания социально-экономической ситуации в городе.
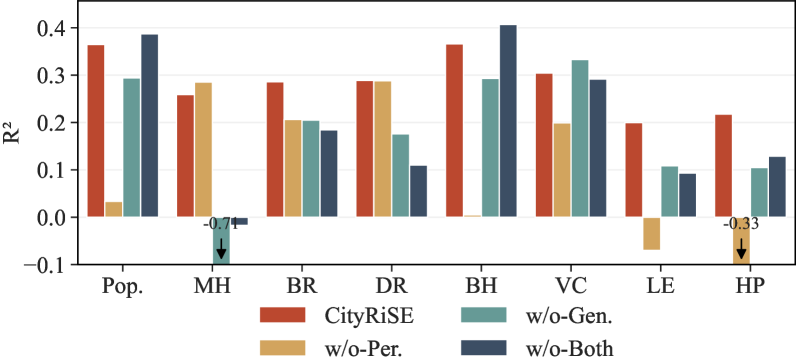
Ключевым элементом подхода является использование обучения с подкреплением. Авторы не просто «скармливают» модели данные, а учат её, направляют, подталкивают к правильному ответу с помощью системы вознаграждений. И здесь, надо признать, они поступили умно. Вместо того, чтобы изобретать сложные и абстрактные функции вознаграждения, они сосредоточились на простом и понятном принципе: минимизация ошибки предсказания.
В основе этого принципа лежит функция потерь Хабера (Huber Loss). Это, если позволите, старый добрый метод, который, в отличие от модных нововведений, действительно работает. Она позволяет снизить влияние выбросов и обеспечить устойчивость предсказаний, что особенно важно в условиях реальной городской среды, где данные далеко не всегда идеальны.
Впрочем, авторы не ограничились только минимизацией ошибки. Они также использовали систему ключевых слов, чтобы направить модель к более осмысленным и интерпретируемым предсказаниям. Это, если хотите, дополнительный фильтр, который позволяет отсеять шум и выделить главное. В конце концов, задача не просто предсказать какое-то число, а понять, что за этим числом стоит.
Конечно, всё это звучит красиво, но главное – это результат. И здесь авторы, надо признать, добились впечатляющих успехов. Система CityRiSE превосходит существующие аналоги по точности и устойчивости предсказаний. Она способна обобщать данные и адаптироваться к новым условиям. А самое главное – она способна объяснить свои предсказания. И это, в конечном счёте, самое важное.
В заключение, хочется отметить, что авторы предложили не просто очередную «революционную» технологию, а вполне практичный и эффективный инструмент для понимания городской среды. Инструмент, который может быть использован для решения реальных проблем и улучшения качества жизни в городах.
Уличные Камеры и «Виртуальный Социолог»: Когда Данные Говорят Сами За Себя?
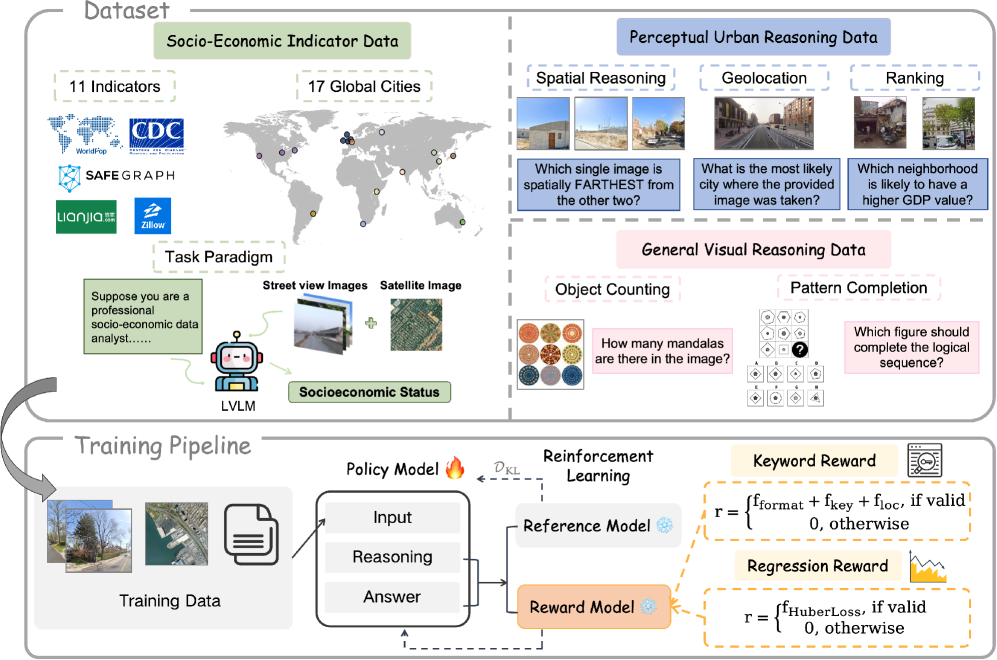
Исследователи в своей работе пошли дальше простого использования датасета CityLens, содержащего «истинные» социально-экономические показатели. Что бы это ни значило, конечно. Все эти красивые цифры – лишь отправная точка. Чтобы хоть как-то приблизиться к созданию модели, способной не просто предсказывать, но и понимать городскую среду, они дополнительно обучили CityRiSE на двух дополнительных источниках данных. И, надо сказать, не зря.
Первый из них – Perceptual Urban Reasoning Data. Звучит, конечно, как очередная модная фраза, но суть проста: задача – научить модель видеть не просто «здание», а «здание в контексте». Этот датасет включает в себя задачи вроде Socio-Economic Ranking (оценка районов по уровню жизни), Spatial Reasoning (определение местоположения объектов) и Geolocation (определение города по фотографии). Всё это, чтобы модель научилась понимать городскую среду, а не просто запоминать пиксели. Как будто этого достаточно, чтобы понять, почему одни районы процветают, а другие – нет.
Второй источник данных – General Visual Reasoning Data. Тут всё немного проще, но от этого не менее важно. Включены задачи вроде Object Counting (подсчёт объектов на изображении) и Pattern Completion (завершение закономерностей). Базовые навыки, скажете вы? Возможно. Но без них даже самая «умная» модель будет, как ребёнок, пытающийся собрать сложный конструктор без инструкции. Удивительно, как часто приходится напоминать о таких простых вещах.
В итоге, CityRiSE обучается не только на данных о социально-экономических показателях, но и на задачах, которые развивают её фундаментальные навыки восприятия и рассуждения. Что-то вроде комплексной программы развития для «виртуального социолога». Конечно, это не панацея. Но, по крайней мере, это шаг в правильном направлении. И, как показывает опыт, иногда даже небольшие улучшения могут иметь большое значение.
Городская Справедливость и «Магический Алгоритм»: Когда Надежды Опережают Реальность?
Итак, они утверждают, что их система, CityRiSE, умеет экстраполировать. Забавно слышать, как все эти «революционные» подходы внезапно оказываются способны работать не только на заранее подготовленных данных. Что ж, они говорят о хорошей кросс-городской обобщающей способности. То есть, система, обученная на одной группе городов, способна более-менее точно предсказывать социально-экономические показатели в тех, где она раньше не «видела» данных. Это, конечно, хорошо. Но я помню немало проектов, где «очень точные» прогнозы рушились, как только появлялись реальные данные. Тем не менее, звучит неплохо.
А ещё они утверждают, что система способна обобщать и по индикаторам. То есть, обучив её предсказывать одни показатели, она может попробовать предсказывать и другие, которые в процессе обучения не использовались. Это уже интереснее. По сути, они пытаются создать что-то вроде универсального предсказателя, способного адаптироваться к разным задачам. Это, конечно, амбициозно, но если им это удалось, это может быть полезно.
И вот где начинается самое интересное. Они говорят о возможности масштабируемой и точной оценки городского неравенства. То есть, их система может помочь выявить районы, нуждающиеся в особом внимании, и направить ресурсы туда, где они наиболее необходимы. В теории, это звучит прекрасно. Если это действительно работает, это может помочь создать более справедливые и равноправные города. Но, как обычно, дьявол кроется в деталях. Насколько точны эти оценки? Насколько хорошо они учитывают местные особенности? И, самое главное, кто будет принимать решения на основе этих оценок? Потому что, как мы все знаем, даже самые точные данные могут быть использованы для достижения самых разных целей.
В общем, они утверждают, что их система может помочь создать более справедливые города. Что ж, это звучит неплохо. Но я помню немало проектов, которые начинались с благих намерений и заканчивались полным провалом. Поэтому я буду ждать, пока они покажут реальные результаты. А пока я буду продолжать чинить продакшен. Потому что, как мы все знаем, система всё ещё жива.
Исследователи, конечно, воодушевлены возможностью обучения моделей предсказывать социально-экономический статус городов, используя лишь изображения и текстовые подсказки. Но давайте будем реалистами. Как говорил Дэвид Марр: “Любая система, которая может быть сломана, будет сломана.” CityRiSE, с его применением обучения с подкреплением, может и демонстрирует впечатляющие результаты обобщения, но стоит помнить, что продакшен всегда найдёт способ выявить скрытые зависимости и, мягко говоря, “удивительные” ошибки. Особенно учитывая, что обучение с подкреплением, как и любая сложная система, крайне чувствительно к дизайну вознаграждения. Всё это, в конечном итоге, сводится к тому, что элегантная теория рано или поздно столкнётся с суровой реальностью уличных видов и непредсказуемыми данными.
Что дальше?
Исследователи продемонстрировали, что большие языковые модели, подтолкнутые обучением с подкреплением, могут аппроксимировать понимание социально-экономического статуса в городских условиях. Почти как будто они действительно понимают. Однако, не стоит забывать: каждая «революция» в машинном обучении – это просто новый способ отложить решение старых проблем. В данном случае, CityRiSE, вероятно, прекрасно работает на тщательно подобранных данных, но что произойдет, когда модель столкнется с городом, где граффити — это признак не бедности, а искусства? Или где определенный тип автомобилей указывает на совершенно иную социальную группу?
Очевидно, что следующим шагом будет попытка сделать модель более устойчивой к таким нюансам. Но не стоит питать иллюзий относительно сложности этой задачи. Чем больше модель «понимает» контекст, тем больше параметров нужно настроить, и тем выше риск появления непредсказуемых ошибок. Более того, если код выглядит идеально – значит, его никто не деплоил. Так что, возможно, лучшим решением будет сосредоточиться на создании более простых и надежных моделей, которые выполняют ограниченный набор задач, а не пытаться создать универсальный искусственный интеллект для анализа городов.
В конечном итоге, CityRiSE – это интересный эксперимент, который демонстрирует потенциал обучения с подкреплением. Но прежде чем говорить о «революции», стоит помнить, что продакшн всегда найдёт способ сломать элегантную теорию. И этот факт, как правило, не зависит от количества параметров в модели.
Оригинал статьи: https://arxiv.org/pdf/2510.22282.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
2025-10-31 20:35