Автор: Денис Аветисян
Новая методика позволяет научить нейросети не просто поддерживать разговор, а выстраивать его с учетом долгосрочных целей и стратегических задач.

Представлен фреймворк GameTalk, использующий обучение с подкреплением и анализ поведенческих сигналов для улучшения качества стратегических многоходовых диалогов.
Несмотря на успехи больших языковых моделей (LLM) в решении отдельных задач, стратегическое взаимодействие в многоагентных средах, требующее координации и переговоров в развернутом диалоге, остается сложной проблемой. В настоящей работе, представленной под названием ‘GameTalk: Training LLMs for Strategic Conversation’, предложен фреймворк, использующий обучение с подкреплением для тренировки LLM в ведении стратегических многоходовых бесед. Показано, что применение методов тонкой настройки, адаптированных для учета вознаграждения, зависящего от всего взаимодействия, существенно улучшает результаты, особенно при использовании DPO. Возможно ли, используя подобные подходы, создать LLM, способные эффективно взаимодействовать и достигать целей в сложных интерактивных средах?
Искусственный интеллект и шахматы: когда теория встречает практику
Современные большие языковые модели (LLM) зачастую демонстрируют ограниченную стратегическую глубину в многоходовых диалогах, испытывая трудности с нюансированными взаимодействиями. Неспособность учитывать долгосрочные последствия своих реплик и предвидеть развитие беседы приводит к тому, что ответы LLM могут казаться поверхностными или нерелевантными в контексте развернутого обсуждения. В отличие от человека, способного строить сложные планы и адаптировать свою тактику в зависимости от реакции собеседника, LLM, как правило, оперируют ближайшим контекстом, что ограничивает их возможности в решении задач, требующих стратегического мышления и планирования на несколько шагов вперед. Эта особенность особенно заметна в ситуациях, требующих убеждения, ведения переговоров или решения сложных проблем, где важно не только понимать текущую ситуацию, но и предвидеть возможные сценарии развития событий.
Для достижения успеха в переговорах и рассуждениях, агенты искусственного интеллекта должны уметь моделировать убеждения оппонента и предвидеть будущие состояния взаимодействия. Однако, стандартные языковые модели (LLM) зачастую испытывают трудности с этим, поскольку они ориентированы на статистическое сопоставление шаблонов, а не на глубокое понимание намерений и стратегий. Способность к прогнозированию, то есть к построению вероятностных сценариев развития беседы с учетом возможных реакций оппонента, критически важна для принятия обоснованных решений. Таким образом, для создания действительно эффективных переговорщиков требуется принципиально новый подход к разработке ИИ, основанный на моделировании когнитивных процессов, позволяющих предвидеть и учитывать мотивацию и ожидания другой стороны.

GameTalk: Игровая площадка для стратегического ИИ
Фреймворк GameTalk использует структуру игр для создания надежной среды обучения для стратегического диалога. В основе подхода лежит идея, что итеративное участие в игровых сценариях, таких как «Камень, ножницы, бумага» и «Торг размерами», позволяет языковым моделям (LLM) развивать способность предвидеть действия оппонента и формулировать эффективные стратегии. Игровые сценарии предоставляют четко определенные правила и цели, что позволяет оценить и улучшить способность LLM к планированию, адаптации и принятию решений в условиях неполной информации. В отличие от традиционных методов обучения, основанных на больших объемах неструктурированного текста, GameTalk предлагает контролируемую и измеримую среду для развития стратегического мышления у LLM.
Обучение больших языковых моделей (LLM) в рамках GameTalk осуществляется путем многократного участия в игровых сценариях, таких как «Камень, ножницы, бумага» и «Торг за приз». Этот подход позволяет моделям осваивать предвидение действий оппонента и разработку эффективных стратегий, основанных на анализе предыдущих ходов и вероятностной оценке дальнейших действий. Повторяющиеся взаимодействия в контролируемой игровой среде способствуют укреплению способности модели к планированию и принятию оптимальных решений в условиях неопределенности, что приводит к улучшению стратегического мышления и повышению результативности в различных игровых ситуациях.
В ходе тестирования фреймворка GameTalk было зафиксировано улучшение показателей производительности во всех протестированных играх. В частности, LLM, обученные с использованием GameTalk, продемонстрировали превосходство над базовыми моделями по ключевым метрикам, включая точность предсказания действий оппонента, эффективность стратегии и общую результативность в игровом процессе. Количественные данные показывают, что прирост производительности варьируется в зависимости от конкретной игры, но во всех случаях наблюдается статистически значимое превышение базового уровня, что подтверждает эффективность подхода GameTalk к обучению стратегическому взаимодействию.
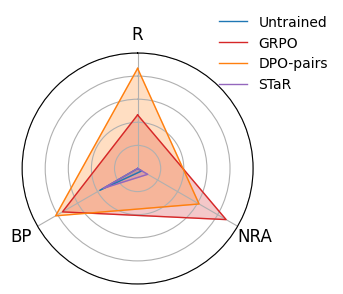
Измеряя стратегическую проницательность: ключевые метрики
Для количественной оценки способности агента рассуждать о убеждениях оппонента и предсказывать его действия используются метрики StateRelativePerformance и InternalStateEvaluation. StateRelativePerformance измеряет эффективность агента в оценке текущего состояния игры относительно ожиданий оппонента, выявляя его способность к построению модели сознания другого игрока. InternalStateEvaluation, в свою очередь, оценивает внутреннюю модель агента о состоянии игры и его уверенность в прогнозах относительно действий оппонента. Высокие значения этих метрик свидетельствуют о развитой способности агента к стратегическому мышлению и прогнозированию поведения противника, что позволяет ему принимать более обоснованные решения в динамичной игровой среде.
Метрика LeverageOpportunity используется для оценки способности агента влиять на поведение оппонента и достигать благоприятных результатов. Она измеряет, насколько успешно агент использует доступную информацию и свои действия для изменения стратегии оппонента в свою пользу. Высокие значения LeverageOpportunity указывают на то, что агент эффективно манипулирует ситуацией, вынуждая оппонента действовать в соответствии с его планом и, как следствие, увеличивая свои собственные выгоды. Оценка проводится на основе анализа действий агента и реакции оппонента, позволяя количественно определить степень влияния агента на принятие решений оппонентом.
В условиях модели Бертрана, обученные агенты продемонстрировали нормализованную прибыль выше 0.5. Этот показатель свидетельствует о способности агентов превосходить случайные стратегии и базовый уровень производительности. Нормализованная прибыль рассчитывается как отношение прибыли агента к максимальной возможной прибыли в данной ситуации, что позволяет оценить эффективность стратегии агента относительно оптимального результата. Значение выше 0.5 указывает на то, что агент стабильно получает более половины от потенциальной максимальной прибыли, подтверждая его способность к стратегическому взаимодействию и конкуренции в условиях модели Бертрана.
В сценариях торга о разделе выигрыша (Size-Prize Bargaining) обученные агенты продемонстрировали повышенную способность к ведению переговоров, что отразилось в значениях, приближающихся к 1. Данный показатель свидетельствует об эффективном использовании переговорной силы и способности агента добиться благоприятных условий распределения выигрыша. Значения, близкие к 1, указывают на то, что агент последовательно добивается максимальной доли выигрыша в ходе переговоров, демонстрируя превосходство над оппонентом и умение влиять на исход торга.
Традиционные показатели, такие как процент побед, не отражают нюансы стратегического мастерства. Предлагаемые метрики — StateRelativePerformance, InternalStateEvaluation, LeverageOpportunity, Normalized Earnings и значения, полученные в Size-Prize Bargaining — позволяют оценить способность агента рассуждать о убеждениях оппонента, предсказывать его действия и эффективно влиять на его поведение. Эти показатели обеспечивают детализированное понимание стратегической компетентности, выходящее за рамки простого определения победителя и проигравшего, и позволяют оценить качество принимаемых решений и эффективность стратегий даже в ситуациях, не приводящих к немедленной победе.
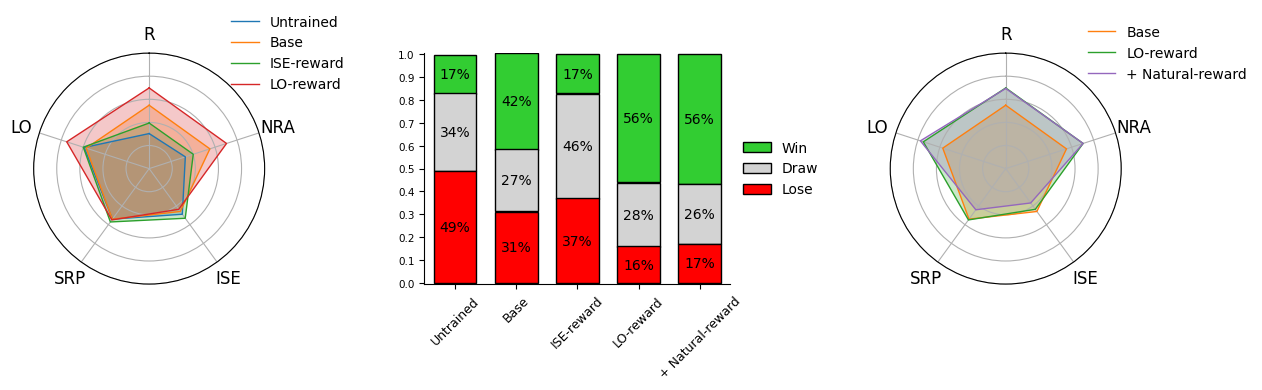
Совершенствуя стратегическое поведение: алгоритмы и техники
В GameTalk для совершенствования стратегической политики языковой модели используются методы обучения с подкреплением (Reinforcement Learning), в частности, алгоритмы GRPO (Generalized Reward-shaping Policy Optimization) и DPO (Direct Preference Optimization). GRPO оптимизирует политику, используя обобщенные сигналы вознаграждения для более эффективного обучения, в то время как DPO напрямую оптимизирует политику на основе предпочтений, полученных от сравнения различных ответов. Комбинация этих алгоритмов позволяет модели адаптировать свою стратегию в диалоге, максимизируя вероятность достижения желаемого результата в рамках игрового сценария.
Метод STaR (Self-Taught Reasoning) интегрирован для улучшения способности модели к рассуждениям путем генерации и последующего использования следов рассуждений (reasoning traces). Этот подход предполагает создание последовательности шагов, демонстрирующих процесс логического вывода, которые затем используются для обучения модели. В процессе обучения модель не только изучает конечный результат, но и анализирует сам процесс рассуждения, что позволяет ей генерировать более обоснованные и последовательные ответы. Использование следов рассуждений в качестве обучающих данных позволяет модели «самостоятельно» улучшать свои навыки рассуждения без необходимости в ручной аннотации или экспертных оценках.
В ходе экспериментов, применение целенаправленного формирования вознаграждения (reward shaping) при обучении языковых моделей продемонстрировало значительное улучшение результатов во всех протестированных играх. Эффективность была подтверждена использованием дополнительных сигналов, таких как ISE (Intrinsic Signal Enhancement), SRP (Strategic Reward Propagation) и LO (Long-term Outcome), которые позволили оптимизировать стратегическое поведение модели. В частности, ISE способствует генерации более осмысленных действий, SRP — распространению вознаграждения за стратегически важные шаги, а LO — учету долгосрочных последствий принимаемых решений. Результаты свидетельствуют о том, что комбинирование этих вспомогательных сигналов позволяет эффективно обучать языковые модели для достижения успеха в стратегических взаимодействиях.
Комбинация используемых методов, включающая обучение с подкреплением (Reinforcement Learning) и алгоритмы, такие как GRPO и DPO, в сочетании с интеграцией STaR (Self-Taught Reasoning) и целенаправленным формированием вознаграждений (ISE, SRP, LO), обеспечивает эффективную тонкую настройку больших языковых моделей (LLM) для стратегического взаимодействия. Такой подход позволяет значительно улучшить качество диалогов, требующих продуманных стратегий и последовательного рассуждения, за счет оптимизации политики модели и использования вспомогательных сигналов для усиления обучения. Результаты показывают, что данный комплексный метод обеспечивает существенный прирост производительности во всех тестируемых играх, демонстрируя его практическую применимость и эффективность.
Будущее разговорного ИИ: стратегическая глубина и за ее пределами
Оснащение больших языковых моделей (LLM) способностями к стратегическому мышлению открывает принципиально новые перспективы в таких областях, как переговоры, дипломатия и разрешение конфликтов. Вместо простого реагирования на запросы, эти модели способны разрабатывать долгосрочные планы, предвидеть действия оппонентов и адаптировать свою стратегию для достижения оптимальных результатов. Исследования показывают, что LLM, обученные на моделях сложных игр и сценариев, демонстрируют удивительную способность к убеждению, компромиссу и даже манипулированию, что делает их потенциально ценными инструментами для посредничества в международных отношениях или ведения коммерческих переговоров. Такой подход позволяет создавать виртуальных переговорщиков, способных анализировать большие объемы данных, выявлять скрытые интересы и предлагать взаимовыгодные решения, что значительно повышает эффективность процесса принятия решений.
Наблюдается переход к новым поколениям разговорного искусственного интеллекта, способных не просто реагировать на запросы, но и проявлять инициативу в сложных социальных взаимодействиях. Данный подход позволяет создавать системы, адаптирующиеся к меняющимся обстоятельствам и прогнозирующие действия собеседника, что открывает возможности для применения в сферах, требующих тонкого понимания человеческих взаимоотношений и умения находить компромиссы. Вместо пассивного выполнения команд, такие ИИ способны выстраивать стратегию диалога, учитывать долгосрочные цели и эффективно разрешать конфликты, приближая их к уровню человеческого взаимодействия.
В будущем исследования в области развития стратегических агентов на базе больших языковых моделей будут направлены на значительное расширение спектра используемых для обучения игр и сценариев. Это позволит не только повысить устойчивость и надежность этих агентов в различных ситуациях, но и существенно улучшить их способность к обобщению полученных знаний. Увеличение разнообразия обучающих данных, включающих в себя как простые, так и сложные интерактивные среды, позволит агентам осваивать более тонкие нюансы социального взаимодействия и успешно применять стратегическое мышление в широком круге задач, от деловых переговоров до разрешения конфликтов. Такой подход предполагает создание более адаптивных и прогностических систем, способных эффективно функционировать в условиях неопределенности и изменчивости.
Обучение больших языковых моделей — процесс, напоминающий попытку удержать ежа в перчатках. Теория игр в GameTalk пытается предсказать ходы оппонента, но на практике, как показывает опыт, продакшен всегда находит способ обойти даже самые продуманные стратегии. В рамках данной работы, акцент на reward shaping — это лишь временная передышка, попытка хоть как-то направить непредсказуемость модели в нужное русло. Как метко заметил Джон Маккарти: «Наилучший способ предсказать будущее — создать его». Создавать будущее разговорного ИИ, конечно, пытаются, но будущее, как известно, имеет привычку удивлять, особенно когда речь идет о системах, которые учатся говорить.
Куда Поведёт Нас Эта Игра?
Представленный фреймворк GameTalk, безусловно, демонстрирует способность обучать языковые модели ведению стратегических диалогов. Однако, не стоит обольщаться. Каждая «интеллектуальная» система рано или поздно сталкивается с реальностью, где пользователи предсказуемо иррациональны. Пока модель играет в шахматы с самой собой, реальный оппонент, скорее всего, попытается вывести её из равновесия, используя не логику, а, скажем, сарказм или бессмысленные вопросы. И тогда все эти тщательно выверенные функции вознаграждения превратятся в пыль.
Следующим шагом, вероятно, станет попытка моделирования не только стратегии, но и непредсказуемости оппонента. Попытки создать «универсального» игрока, способного адаптироваться к любому стилю общения, обречены на провал. Ведь даже в самой тщательно продуманной системе всегда найдётся лазейка, баг, который эксплуатирует злоумышленник или просто случайный пользователь. Тесты — это, конечно, форма надежды, но никак не гарантия.
В конечном счёте, стоит признать, что обучение стратегическому диалогу — это бесконечная гонка вооружений. Каждый новый алгоритм будет взламываться, каждая новая стратегия — обходиться. И это, пожалуй, и есть самое интересное. Автоматизация, конечно, нас «спасёт», но только после того, как скрипт случайно удалит продакшен в очередной раз.
Оригинал статьи: https://arxiv.org/pdf/2601.16276.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Ранжирование с умом: новый подход к предсказанию кликов
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-26 17:45