Автор: Денис Аветисян
Исследователи представили LLaDA2.0 — семейство крупных языковых моделей, использующих диффузионный подход и демонстрирующих высокую эффективность и масштабируемость.
Работа посвящена разработке и обучению диффузионных языковых моделей на 16 и 100 миллиардов параметров с применением непрерывного предобучения и оптимизированных методов тренировки и инференса.
Масштабирование больших языковых моделей сопряжено с вычислительными сложностями и потребностью в инновационных подходах. В данной работе, представленной под названием ‘LLaDA2.0: Scaling Up Diffusion Language Models to 100B’, предлагается новая парадигма, основанная на преобразовании авторегрессионных моделей в диффузионные языковые модели (dLLM) с количеством параметров до 100 миллиардов. Разработанный трехфазный метод обучения, включающий прогрессивное увеличение размера блоков и адаптацию к задачам, обеспечивает высокую эффективность и производительность при параллельном декодировании. Сможет ли подобный подход стать основой для создания еще более мощных и доступных языковых моделей будущего?
Авторегрессия в тупике: Ограничения традиционных моделей
Традиционные авторегрессионные языковые модели, несмотря на свою эффективность в генерации последовательностей текста, сталкиваются с существенными ограничениями при работе с долгосрочными зависимостями и возможностями параллельной обработки. В процессе генерации, каждая новая единица текста формируется на основе предыдущих, что создает последовательную цепочку вычислений. Это, в свою очередь, затрудняет улавливание связей между элементами, расположенными на значительном расстоянии друг от друга в последовательности, поскольку информация о них может быть ослаблена или потеряна по мере прохождения через множество промежуточных шагов. Более того, последовательный характер вычислений препятствует эффективной параллелизации, ограничивая возможности масштабирования и замедляя как обучение, так и процесс генерации текста, особенно при работе с большими объемами данных и сложными задачами.
Последовательный характер традиционных авторегрессионных языковых моделей создает существенные препятствия как на этапе обучения, так и при практическом применении. Каждый новый элемент последовательности генерируется только после завершения обработки предыдущего, что исключает возможность параллельных вычислений и значительно замедляет процесс. Эта особенность становится критичной при работе с большими объемами данных и сложными задачами, где требуется обработка длинных последовательностей. В результате, масштабирование таких моделей сталкивается с ограничениями, поскольку время обучения и инференса растет линейно с увеличением длины последовательности, делая их неэффективными для ресурсоемких приложений, таких как перевод, анализ текста и генерация контента в реальном времени. Более того, последовательная обработка ограничивает возможность одновременного анализа всей входной информации, что снижает качество моделирования и ее способность к пониманию контекста.
Увеличение масштаба авторегрессионных моделей выявляет существенные ограничения в способности улавливать двунаправленный контекст, что критически важно для глубокого понимания языка. Традиционные авторегрессионные модели, генерируя последовательности пошагово, учитывают только предшествующий контекст, игнорируя информацию, содержащуюся в последующих элементах. Это приводит к неполному пониманию смысла, особенно в случаях, когда значение слова или фразы определяется как предшествующим, так и последующим контекстом. Исследования показывают, что модели, способные учитывать двунаправленный контекст, демонстрируют значительно лучшую производительность в задачах, требующих нюансированного понимания, таких как разрешение неоднозначности, определение взаимосвязей между предложениями и генерация более связных и логичных текстов. В результате, при масштабировании, ограничения в улавливании двунаправленного контекста становятся все более заметными, подчеркивая необходимость разработки новых архитектур, способных эффективно использовать информацию из обоих направлений последовательности для достижения более глубокого понимания языка.
Диффузия как спасение: Новый подход к генерации последовательностей
Дискретные маскированные диффузионные языковые модели (DMLM) отличаются от традиционных авторегрессионных (AR) моделей принципом генерации последовательностей. Вместо последовательного предсказания следующего токена, DMLM работают путем маскирования части входной последовательности и последующей реконструкции замаскированных участков. Этот подход позволяет распараллеливать процесс восстановления, так как каждый замаскированный токен может быть предсказан независимо от других, что значительно увеличивает скорость генерации по сравнению с AR-моделями, требующими последовательной обработки.
В отличие от авторегрессионных моделей, которые генерируют последовательности последовательно, модели диффузии, осуществляющие реконструкцию замаскированных входных данных, способны использовать двунаправленный контекст. Это означает, что при прогнозировании каждого элемента последовательности модель учитывает как предшествующие, так и последующие элементы. Такой подход позволяет более полно понимать взаимосвязи в данных и, как следствие, улучшает качество генерируемого текста, поскольку модель получает более широкую картину контекста, необходимую для точного прогнозирования и создания когерентных последовательностей. Использование двунаправленного контекста особенно эффективно при решении задач, требующих глубокого понимания смысла и связей между элементами последовательности, например, в задачах машинного перевода или суммаризации текста.
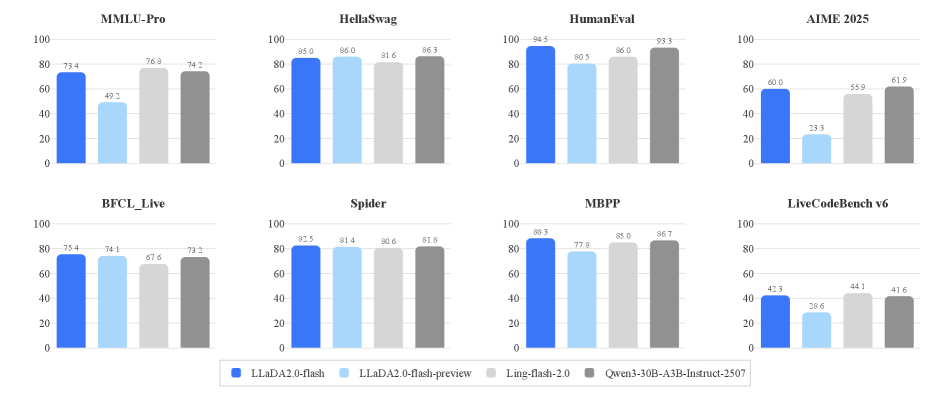
LLaDA2.0 является конкретной реализацией подхода диффузионных языковых моделей, представляющей собой модель с 100 миллиардами параметров. В ходе сравнительного тестирования LLaDA2.0 демонстрирует сопоставимую производительность с авторегрессионными моделями, такими как Qwen3-30B-A3B-Instruct-2507, по различным метрикам оценки качества генерируемого текста. Данное сравнение подтверждает эффективность нового подхода к генерации последовательностей и возможность достижения конкурентоспособных результатов при использовании диффузионных моделей в задачах обработки естественного языка.
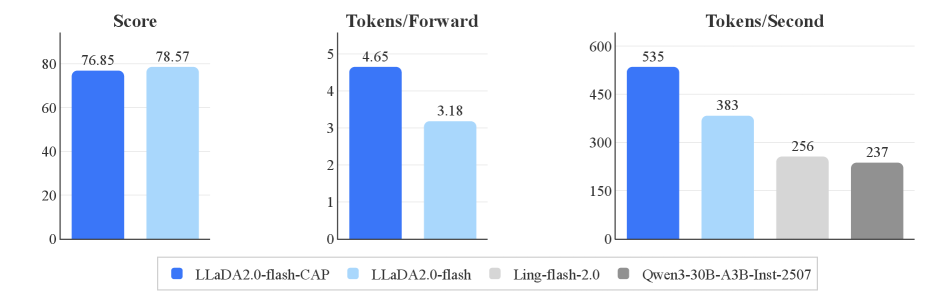
Модель LLaDA2.0 демонстрирует значительное увеличение скорости генерации текста, достигая пропускной способности в 535 токенов в секунду. Это превосходит показатели сравнимых авторегрессионных (AR) моделей, у которых зафиксирована пропускная способность 256 и 237 токенов в секунду соответственно. Таким образом, LLaDA2.0 обеспечивает ускорение до 2.1x по сравнению с AR-базовыми моделями при проведении инференса.
Обучение гиганта: Рецепты и инфраструктура для LLaDA2.0
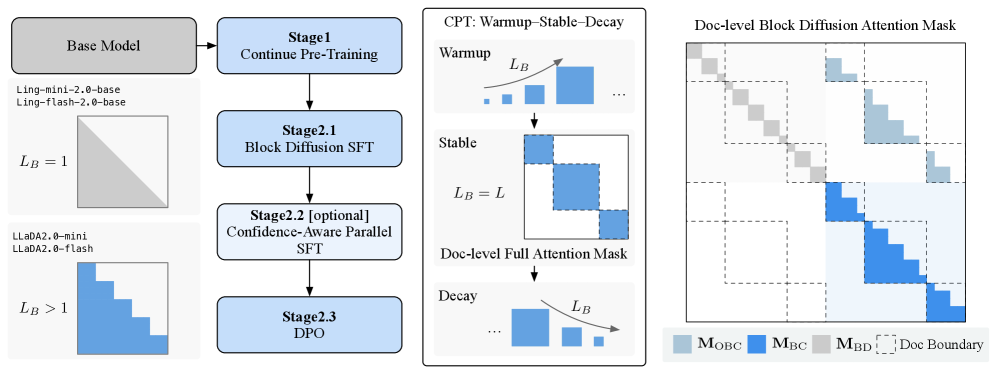
Непрерывное предварительное обучение (Continual Pre-Training) используется для адаптации авторегрессионных (AR) языковых моделей к архитектуре диффузионных языковых моделей. Этот подход позволяет сохранить лингвистические знания, накопленные в процессе обучения AR-модели, одновременно внедряя механизмы, необходимые для генерации данных с использованием принципов диффузии. Вместо обучения с нуля, предварительно обученная AR-модель служит отправной точкой, что существенно сокращает время и вычислительные ресурсы, необходимые для достижения сопоставимой производительности в задачах генерации текста. При этом, процесс непрерывного обучения позволяет модели постепенно адаптироваться к новой задаче, минимизируя потерю ранее приобретенных знаний и обеспечивая плавный переход к диффузионной генерации.
Стратегия Warmup-Stable-Decay является ключевым элементом преобразования авторегрессионных (AR) моделей в диффузионные. Данный подход предполагает постепенное увеличение размера блока (block size) в начале обучения (Warmup) для стабилизации процесса и предотвращения деградации производительности. Затем, на этапе Stable, размер блока поддерживается на оптимальном уровне. В заключение, размер блока постепенно уменьшается (Decay) к концу обучения для уточнения модели и сохранения ее способности к генерации. Точное управление размером блока на каждом этапе позволяет эффективно переносить лингвистические знания из AR модели в диффузионную, минимизируя потери в качестве генерируемого текста и обеспечивая стабильность обучения.
Обучение LLaDA2.0 использует передовые методы параллелизации, такие как параллелизм данных (Data Parallelism) и параллелизм экспертов (Expert Parallelism), для распределения вычислительной нагрузки между несколькими устройствами. Для реализации этих методов и оптимизации процесса обучения используются специализированные фреймворки, включая VeOmni и Megatron-LM. VeOmni обеспечивает гибкую инфраструктуру для распределенного обучения, в то время как Megatron-LM предоставляет оптимизированные реализации ключевых операций, необходимых для обучения больших языковых моделей, что позволяет эффективно масштабировать процесс обучения и сократить время, необходимое для достижения желаемых результатов. Сочетание этих техник и фреймворков обеспечивает возможность обучения LLaDA2.0 на больших объемах данных с высокой производительностью.
Для оптимизации процесса обучения в LLaDA2.0 применяются методы маскирования внимания на уровне документа и параллельного обучения с учетом достоверности. Маскирование внимания на уровне документа позволяет модели концентрироваться на релевантных частях длинных текстов, игнорируя несущественные фрагменты и снижая вычислительную нагрузку. Параллельное обучение с учетом достоверности предполагает динамическую регулировку весов при параллельном обучении на различных устройствах, отдавая приоритет данным с более высокой достоверностью, что способствует повышению точности и стабильности модели. Эти техники совместно позволяют эффективно использовать вычислительные ресурсы и улучшить качество генерируемого текста.
Влияние на индустрию: Ускорение инференса и выравнивание с человеческими предпочтениями
Архитектура LLaDA2.0 отличается повышенной эффективностью благодаря использованию оптимизированных движков инференса, таких как dInfer и SGLang. Эти инструменты специально разработаны для высокопроизводительного обслуживания языковых моделей, позволяя значительно ускорить процесс генерации ответов и снизить задержки. dInfer, в частности, использует передовые методы компиляции и оптимизации, чтобы максимально эффективно использовать ресурсы оборудования, а SGLang обеспечивает гибкость и масштабируемость при развертывании модели в различных средах. Благодаря этим технологиям LLaDA2.0 способна обрабатывать запросы быстрее и эффективнее, обеспечивая более плавный и отзывчивый пользовательский опыт, что критически важно для интерактивных приложений и задач реального времени.
Метод дополнительного маскирования данных демонстрирует значительное повышение эффективности обучения языковых моделей. В отличие от традиционных подходов, где случайные части входных данных скрываются, данный метод стратегически выбирает сегменты для маскировки, основываясь на их взаимодополняемости. Это позволяет модели более эффективно извлекать информацию из каждого обучающего примера, поскольку скрытые части компенсируются доступными данными. В результате, даже при использовании относительно небольшого объема обучающих данных, модель демонстрирует повышенную устойчивость к шуму и обобщающую способность, что приводит к более точным и надежным результатам. Такой подход особенно важен в условиях ограниченных вычислительных ресурсов и необходимости создания высокопроизводительных языковых моделей.
Процесс обучения LLaDA2.0 включает в себя этап точной настройки с использованием контролируемых данных, что позволяет модели усваивать предпочтения, характерные для человеческого восприятия. В сочетании с оптимизацией на основе непосредственных предпочтений, этот подход позволяет LLaDA2.0 генерировать ответы, более соответствующие ожиданиям пользователей и контексту запроса. Благодаря этому, модель демонстрирует повышенную пригодность для практического применения, предоставляя релевантные и понятные результаты, что существенно расширяет спектр ее потенциальных задач и улучшает взаимодействие с пользователем. Оптимизация предпочтений является ключевым фактором в создании полезных и эффективных языковых моделей, способных адаптироваться к нюансам человеческого общения.
Архитектура LLaDA2.0 использует возможности диффузионной модели для реализации параллельной декодировки, что значительно повышает скорость и эффективность генерации текста. В отличие от традиционных последовательных методов, где каждое следующее слово генерируется после получения предыдущего, параллельная декодировка позволяет одновременно обрабатывать несколько возможных вариантов, что приводит к экспоненциальному ускорению процесса. Это нововведение напрямую отражается на показателях производительности: модель демонстрирует впечатляющие результаты в тестах HumanEval, достигая 94.51%, и MBPP, с результатом 88.29%, подтверждая превосходство подхода в решении задач программирования и логического мышления.
Взгляд в будущее: Масштабируемость, эффективность и выравнивание с ценностями
Репозиторий dFactory представляет собой ценный ресурс для исследователей в области языковых моделей, предоставляя готовые, оптимизированные рецепты обучения диффузионных моделей. Эти рецепты значительно упрощают процесс воспроизведения и адаптации передовых методов, позволяя исследователям сосредоточиться на инновациях, а не на рутинных задачах настройки обучения. Предоставляя готовые решения для ключевых аспектов обучения, таких как выбор гиперпараметров и архитектура модели, dFactory способствует ускорению прогресса в области диффузионных языковых моделей и открывает новые возможности для исследований в области генерации текста, машинного перевода и других приложений обработки естественного языка. Этот подход способствует демократизации доступа к передовым технологиям и стимулирует дальнейшее развитие этой перспективной области искусственного интеллекта.
Модель LLaDA2.0 демонстрирует перспективность диффузионных моделей в области обработки естественного языка, предлагая альтернативу традиционным авторегрессионным подходам. В отличие от последних, которые последовательно генерируют текст, предсказывая следующее слово на основе предыдущих, LLaDA2.0 использует процесс диффузии — постепенного добавления шума к данным и последующего его удаления — для создания текста. Этот подход позволяет модели лучше улавливать сложные зависимости в языке и генерировать более связный и разнообразный текст, преодолевая некоторые ограничения авторегрессионных моделей, такие как склонность к повторениям или трудности с генерацией длинных последовательностей. Результаты показывают, что диффузионные модели, подобные LLaDA2.0, могут стать ключевым направлением в развитии более эффективных и гибких языковых моделей будущего.
Постоянное совершенствование инфраструктуры обучения и методов оптимизации играет ключевую роль в расширении возможностей языковых моделей. Разработчики активно внедряют новые аппаратные решения, включая специализированные ускорители и распределенные системы, что позволяет значительно увеличить масштаб обучаемых моделей и сократить время обучения. Параллельно, усовершенствованные алгоритмы оптимизации, такие как адаптивные методы градиентного спуска и квантизация, снижают вычислительные затраты и требования к памяти. Эти достижения открывают путь к созданию еще более мощных и эффективных языковых моделей, способных решать сложные задачи обработки естественного языка и генерировать высококачественные тексты, при этом снижая энергопотребление и повышая доступность подобных технологий для более широкого круга исследователей и разработчиков.
В дальнейшем исследования в области языковых моделей будут сосредоточены на более тесной адаптации к человеческим ценностям и снижении предвзятости. Это предполагает разработку новых методов обучения, которые не только повышают точность и связность генерируемого текста, но и гарантируют соответствие этическим нормам и социальным ожиданиям. Особое внимание уделяется выявлению и смягчению скрытых предубеждений, заложенных в обучающих данных, чтобы избежать воспроизведения стереотипов и дискриминации. Использование таких подходов, как обучение с подкреплением на основе обратной связи от человека и разработка метрик для оценки этичности, позволит создавать более справедливые и надежные языковые модели, способные эффективно взаимодействовать с людьми и приносить пользу обществу. Успех в этой области критически важен для широкого внедрения языковых моделей в различные сферы жизни.
Наблюдатель видит, как LLaDA2.0, подобно сложной машине, стремится преодолеть ограничения традиционных авторегрессионных моделей. Преобразование в диффузионный подход, с его акцентом на непрерывное предобучение и оптимизацию, напоминает попытку укротить хаос данных. Как однажды заметил Алан Тьюринг: «Мы можем только надеяться, что машины не станут слишком умными, чтобы превзойти нас». И хотя LLaDA2.0 демонстрирует впечатляющие результаты в масштабировании и эффективности, всегда остается вероятность, что реальная среда, с её непредсказуемостью, внесет свои коррективы. Ведь даже самая элегантная архитектура, как бы тщательно она ни была спроектирована, рано или поздно столкнётся с неизбежным крахом в продакшене.
Что дальше?
Работа, представленная в данной статье, демонстрирует, как можно заставить очередную «революционную» архитектуру — диффузионные языковые модели — работать. И, конечно, как можно потратить огромное количество вычислительных ресурсов, чтобы она работала чуть лучше, чем то, что уже работало. Авторы ухитрились преобразовать авторегрессионные модели в диффузионные, что, безусловно, интересно, пока кто-нибудь не поймет, что это просто ещё один способ усложнить и без того непростую систему. Не стоит забывать, что каждое новое улучшение — это просто новый уровень технического долга, который рано или поздно придётся оплачивать.
Очевидно, что предстоит ещё немало работы по оптимизации этих моделей. Параллельное декодирование и обучение с учётом уверенности — это неплохо, но это лишь временные меры. Настоящая проблема в том, что мы продолжаем гоняться за производительностью, забывая о том, что в конечном итоге все эти сложные архитектуры должны решать реальные задачи. И пока кто-нибудь не научит эти модели хоть как-то адаптироваться к меняющимся требованиям, все эти 100 миллиардов параметров будут лишь бесполезным грузом.
В конечном счете, всё новое — это просто старое с худшей документацией. Можно строить сложные системы, можно оптимизировать обучение, но фундаментальная проблема останется прежней: любая модель — это лишь приближение к реальности, и всегда найдется случай, когда она потерпит неудачу. И когда-нибудь, через несколько лет, появится новая архитектура, которая «решит все проблемы», и мы снова начнем всё сначала.
Оригинал статьи: https://arxiv.org/pdf/2512.15745.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
2025-12-19 08:51