Автор: Денис Аветисян
Новый подход позволяет в реальном времени определять управляющие уравнения сложных систем, учитывая неизбежные погрешности и нелинейности.
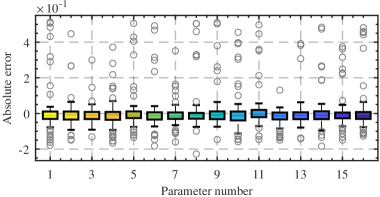
Представлен фреймворк BRSL, объединяющий байесовский регресс, символьное обучение и рекурсивную оценку для идентификации нелинейных динамических систем с квантификацией неопределенности.
Существующие подходы к идентификации динамических систем часто сталкиваются с необходимостью компромисса между интерпретируемостью модели и точным учетом неопределенностей. В данной работе, посвященной ‘Online identification of nonlinear time-varying systems with uncertain information’, предложен новый фреймворк BRSL (Bayesian Regression-based Symbolic Learning), объединяющий байесовский подход с символическим обучением для онлайн-идентификации нелинейных систем. Данный подход позволяет одновременно оценивать параметры модели, учитывать неопределенности и обеспечивать интерпретируемость полученных уравнений, благодаря использованию разреженных априорных распределений. Сможет ли предложенный фреймворк стать основой для создания надежных и адаптивных цифровых двойников сложных технических систем?
Цифровые Двойники: Когда Теория Встречается с Продуктивным Хаосом
Технология цифровых двойников открывает колоссальные возможности для оптимизации и управления разнообразными системами, начиная от промышленных процессов и заканчивая городскими инфраструктурами. Однако, эффективность этих виртуальных представлений напрямую зависит от точности и способности адаптироваться к изменяющимся условиям. Цифровой двойник — это не просто статичная копия реального объекта, а динамическая модель, требующая постоянного обновления на основе поступающих данных. Неточные или устаревшие модели приводят к ошибочным прогнозам и неэффективным решениям, сводя на нет все преимущества технологии. Поэтому, создание и поддержание актуальных, самообучающихся моделей является ключевым фактором успешного внедрения цифровых двойников в различных сферах деятельности.
Традиционные методы идентификации систем часто сталкиваются с трудностями при работе со сложностями реальных данных, что обусловлено наличием шумов, нелинейностей и изменяющихся во времени параметров. Это требует частой переоценки моделей, что является ресурсоемким процессом и создает значительные задержки. В результате, применение таких методов в приложениях реального времени, где требуется оперативное реагирование на изменения, становится проблематичным. Например, в управлении сложными промышленными процессами или в системах автономного вождения, задержки в обновлении модели могут привести к снижению эффективности или даже к аварийным ситуациям. Поэтому, возникает необходимость в разработке более адаптивных и эффективных методов идентификации, способных оперативно учитывать динамику реальных данных и обеспечивать надежную работу систем в изменяющихся условиях.
В условиях динамично меняющихся систем и растущего объема поступающих данных, потребность в непрерывном обучении моделей становится критически важной. Традиционные методы идентификации систем, требующие периодической переоценки на основе статических выборок, оказываются неэффективными для задач реального времени. Вместо этого, всё большее внимание уделяется онлайн-методам, позволяющим инкрементально обновлять математические модели по мере поступления новых данных. Такой подход обеспечивает адаптивность и точность цифровых двойников, позволяя им оперативно реагировать на изменения в окружающей среде и оптимизировать процессы в режиме реального времени. Использование онлайн-идентификации систем открывает возможности для создания самообучающихся систем, способных к долгосрочной и устойчивой работе без необходимости вмешательства человека.
Байесовский Регрессионный Символический Анализ: Простота как Гарантия Надежности
Байесовский регрессионный символический анализ представляет собой эффективный метод обучения лаконичным управляющим уравнениям непосредственно на основе данных, что позволяет создавать интерпретируемые модели. В отличие от традиционных методов, данный подход позволяет автоматически определять наиболее значимые термины в уравнении, исключая из рассмотрения незначительные, тем самым упрощая модель и повышая ее обобщающую способность. Это особенно полезно при анализе сложных систем, где количество возможных взаимодействий велико, и требуется выявить лишь основные факторы, определяющие поведение системы. В результате, полученные модели не только точно описывают данные, но и позволяют получить ценные сведения о физических или иных закономерностях, лежащих в основе наблюдаемого процесса.
В рамках подхода используется байесовский вывод и Horseshoe prior для индукции разреженности модели. Horseshoe prior, являясь регуляризирующим приором, способствует обнулению коэффициентов при незначимых терминах, тем самым идентифицируя только наиболее важные слагаемые и снижая риск переобучения. Результаты моделирования демонстрируют высокую точность оценки истинных значений параметров, особенно при 30% ненулевых параметров, что подтверждает эффективность данного метода в задачах идентификации систем и построении интерпретируемых моделей.
Предложенный подход развивает существующие методы Sparse Identification of Nonlinear Dynamics (SID) путем интеграции алгоритма Recursive Least Squares (RLS) для эффективной оценки параметров в режиме реального времени. В отличие от традиционных методов SID, требующих пакетной обработки данных, использование RLS позволяет адаптировать модель к поступающим данным последовательно, что особенно важно для задач онлайн-обучения и управления. Интеграция RLS обеспечивает вычислительную эффективность при оценке параметров, что позволяет применять данный подход к задачам с большим объемом данных и высокими требованиями к скорости обработки. Это позволяет модели динамически адаптироваться к изменениям в данных и обеспечивать более точные прогнозы и управление.
Гарантия Устойчивости и Сходимости: Когда Алгоритм Работает, Как Часы
Квантификация неопределенностей является критически важной процедурой для оценки надежности прогнозов, особенно в приложениях, связанных с безопасностью. Оценка неопределенности включает в себя не только определение точности предсказаний, но и выявление потенциальных рисков, связанных с ошибочными результатами. В контексте систем управления и критически важных приложений, таких как автономное вождение или авиация, понимание вероятности возникновения ошибок и их потенциальных последствий позволяет разрабатывать стратегии смягчения рисков и обеспечивать безопасную работу системы. Методы квантификации неопределенностей включают в себя анализ чувствительности, байесовский вывод и методы Монте-Карло, позволяющие оценить влияние различных факторов на точность предсказаний и обеспечить принятие обоснованных решений.
Анализ сходимости алгоритма обучения, подкрепленный условием устойчивого возбуждения (Persistent Excitation), гарантирует достижение стабильного решения и, как следствие, долговременную работоспособность системы. Условие устойчивого возбуждения требует, чтобы входной сигнал содержал достаточное количество информации для возбуждения всех релевантных модальностей системы на протяжении всего процесса обучения. Отсутствие устойчивого возбуждения может привести к тому, что алгоритм застрянет в локальном минимуме или не сможет адекватно отслеживать изменяющиеся условия среды. Математически, устойчивое возбуждение часто выражается через требование к ограниченному снизу определителю матрицы корреляции входных данных за конечное время \lim_{T \to \in fty} \frac{1}{T} \sum_{t=1}^{T} x(t)x(t)^T > 0 , где x(t) — вектор входных данных в момент времени t .
Коэффициент забывания (Forgetting Factor), интегрированный в рекурсивную структуру алгоритма, представляет собой параметр, определяющий, в какой степени информация из предыдущих итераций учитывается при обновлении модели. Значение коэффициента в диапазоне от 0 до 1 определяет баланс между адаптацией к текущим изменениям в данных и сохранением полезной исторической информации. Более низкие значения коэффициента приводят к быстрой адаптации, но могут привести к потере стабильности и игнорированию долгосрочных тенденций. Напротив, более высокие значения обеспечивают большую стабильность и сохранение исторической информации, но могут замедлить адаптацию к новым условиям. Выбор оптимального значения коэффициента забывания критически важен для достижения эффективного обучения и обеспечения надежной работы системы в динамически меняющейся среде. 0 < \lambda \le 1, где λ — коэффициент забывания.
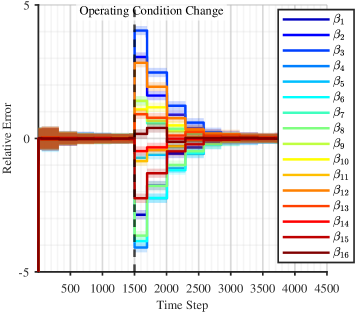
Проверка на Практике: Система Лоренца как Лакимус-Бумага
Для проверки эффективности разработанного метода, он был применен к системе Лоренца — известному и сложному эталону для идентификации нелинейных систем. В рамках исследования, динамика системы Лоренца была представлена в виде модели пространства состояний (StateSpaceModel), что позволило эффективно анализировать и моделировать её поведение. Такой подход позволяет не только точно воспроизвести траекторию системы, но и предоставляет основу для дальнейшего анализа её чувствительности к различным параметрам и начальным условиям, что критически важно для понимания сложных динамических процессов.
Изученная модель продемонстрировала способность точно воспроизводить динамику системы Лоренца, что подтверждается ее высокой точностью прогнозирования будущих состояний. Проверка отслеживания состояний системы проводилась посредством симуляций в сложных, зашумленных условиях, имитирующих реальные сценарии. Результаты показали, что модель надежно сохраняет соответствие траекториям системы даже при наличии значительных помех, что свидетельствует о ее устойчивости и применимости для анализа нелинейных систем в условиях неопределенности. Данная способность к точному прогнозированию и отслеживанию в сложных условиях подтверждает эффективность предложенного подхода к идентификации динамических систем.
Для обеспечения прозрачности и доверия к полученной модели, исследователи использовали SHAP-значения — метод интерпретируемого машинного обучения. Анализ с применением SHAP-значений позволил выявить ключевые признаки, оказывающие наибольшее влияние на динамику системы Лоренца. Установлено, что определенные компоненты состояния системы оказывают доминирующее влияние на предсказания модели, что подтверждает ее способность улавливать существенные взаимосвязи внутри сложной нелинейной системы. Это не только подтверждает адекватность модели, но и предоставляет ценную информацию о внутренних механизмах, определяющих поведение системы Лоренца, способствуя более глубокому пониманию ее динамики.
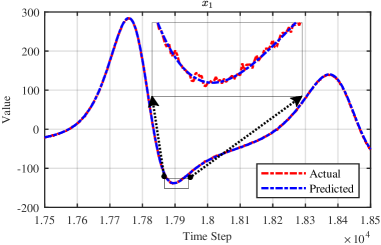
Исследование демонстрирует стремление к построению моделей, способных адаптироваться к реальности, а не к идеализированным представлениям о ней. Авторы предлагают framework, объединяющий интерпретируемость и оценку неопределенности — подход, который, судя по всему, направлен на снижение рисков, связанных с чрезмерной уверенностью в результатах. В этой связи вспоминается высказывание Андрея Николаевича Колмогорова: «Математика — это искусство находить закономерности в хаосе». Ведь именно умение адекватно оценивать неопределенность и учитывать возможные погрешности является ключевым для успешного применения любых математических моделей к динамическим системам, особенно в контексте построения цифровых двойников и онлайн-идентификации нелинейных систем.
Куда же это всё ведёт?
Представленный подход, объединяющий байесовский вывод и символьное обучение, безусловно, элегантен. Однако, как показывает практика, любая элегантность рано или поздно обращается в прагматичный техдолг. Проблема не в алгоритмах, а в данных. В реальных системах неопределённость информации не просто «учитывается», она множится в геометрической прогрессии, порождая каскад ошибок, которые даже самые изящные модели не в силах предсказать. Цифровые двойники остаются лишь фантазией, пока реальность не научится быть более предсказуемой.
Дальнейшие исследования, вероятно, будут направлены на повышение робастности алгоритмов к шуму и выбросам. Но истинный прогресс, скорее всего, потребует отказа от иллюзий полной идентичности модели и реальной системы. Вместо того чтобы стремиться к идеальному описанию, необходимо научиться эффективно работать с приближениями и неполнотой данных. Нам не нужно больше микросервисов для идентификации систем — нам нужно меньше иллюзий о возможности их полного контроля.
Вероятно, наиболее перспективным направлением является разработка алгоритмов, способных не только идентифицировать уравнения, но и оценивать пределы их применимости. То есть, система должна уметь сказать: «Я знаю, что не знаю». Иначе, всё это останется лишь красивой математической игрой, оторванной от суровой реальности производственных задач.
Оригинал статьи: https://arxiv.org/pdf/2601.10379.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовая химия: моделирование сложных молекул на пороге реальности
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
2026-01-18 22:36