Автор: Денис Аветисян
В статье представлена инновационная теория, объединяющая принципы континуальной механики и оптимального транспорта для создания генеративных моделей, эффективно работающих при ограниченном объеме данных.

Предлагается фреймворк CM-GAI, использующий физически обоснованные нейронные сети для решения задачи переноса вероятностных распределений в пространствах признаков.
Несмотря на впечатляющие успехи генеративного искусственного интеллекта, его применение в специализированных областях часто сдерживается дефицитом данных. В настоящей работе, посвященной теории ‘CM-GAI: Continuum Mechanistic Generative Artificial Intelligence Theory for Data Dynamics’, предложен новый теоретический аппарат, основанный на принципах континуальной механики и оптимального транспорта, позволяющий эффективно моделировать динамику данных при ограниченном объеме обучающей выборки. Разработанный подход реализует генерацию данных посредством переноса вероятностных распределений в пространстве признаков и решения возникающей транспортной задачи с использованием физически обоснованных нейронных сетей. Может ли интеграция механики и искусственного интеллекта открыть новые горизонты для решения сложных задач не только в инженерных расчетах, но и в других областях, требующих генерации и анализа данных?
Генезис Генеративного ИИ: Новая Эпоха Творчества и Точности
Генеративный искусственный интеллект стремительно меняет ландшафт различных областей — от искусства и дизайна до науки и инженерии — благодаря растущей потребности в создании новых, ранее не существовавших данных. Эта трансформация обусловлена не только автоматизацией рутинных задач, но и возможностью генерировать сложные и реалистичные образцы, которые могут быть использованы для решения широкого спектра проблем. Например, в медицине генеративные модели помогают создавать синтетические изображения для обучения диагностических систем, а в материаловедении — предсказывать свойства новых материалов. Подобные инновации стимулируют развитие новых технологий и открывают возможности для решения задач, которые ранее казались невозможными, делая генеративный ИИ ключевым двигателем прогресса в современном мире.
В основе генеративного искусственного интеллекта лежит концепция генеративных моделей — сложных алгоритмов, способных изучать скрытую структуру данных и на её основе создавать новые, реалистичные образцы. Эти модели не просто копируют существующую информацию, а выявляют закономерности и взаимосвязи, позволяющие им генерировать данные, похожие на те, на которых они обучались. Например, изучив тысячи изображений лиц, генеративная модель может создать совершенно новое изображение лица, которое никогда не существовало в реальности. Этот процесс происходит за счет построения вероятностного представления данных, позволяющего модели предсказывать наиболее вероятные значения для каждого параметра и, таким образом, создавать убедительные и правдоподобные результаты. Способность к генерации новых данных открывает широкие возможности в различных областях, от создания произведений искусства и дизайна до разработки новых лекарств и материалов.
В основе генеративных моделей лежит глубокое понимание и представление вероятностных распределений, позволяющее им оценивать правдоподобие различных исходов. По сути, модель не просто воспроизводит данные, но и изучает, насколько вероятны те или иные комбинации признаков в исходном наборе. Это достигается путем построения математической функции, описывающей вероятность появления каждого возможного значения или комбинации значений. Например, при генерации изображений, модель оценивает вероятность появления определенного пикселя определенного цвета в конкретной позиции, учитывая контекст соседних пикселей. Чем точнее модель представляет это вероятностное распределение P(x), тем более реалистичными и правдоподобными будут генерируемые ею образцы. Именно способность моделировать и воспроизводить эти распределения является ключевым фактором, определяющим качество и разнообразие генерируемого контента.

Преодоление Имитации: Внедрение Физики в Процесс Генерации
Традиционные генеративные модели часто демонстрируют несоответствие физическим принципам, что проявляется в создании нереалистичных или невозможных результатов. Например, генерируемые изображения могут содержать объекты с нарушенной гравитацией или нефизичными деформациями. Для повышения достоверности и реалистичности сгенерированных данных необходимо внедрение физических законов непосредственно в процесс генерации. Это достигается за счет использования физически обоснованных моделей и ограничений, которые обеспечивают соответствие генерируемых данных наблюдаемым физическим явлениям и принципам сохранения, таким как сохранение энергии и импульса. В результате, модели становятся способны генерировать более правдоподобные и согласованные данные, особенно в областях, где физическая достоверность критически важна, например, в симуляциях и моделировании.
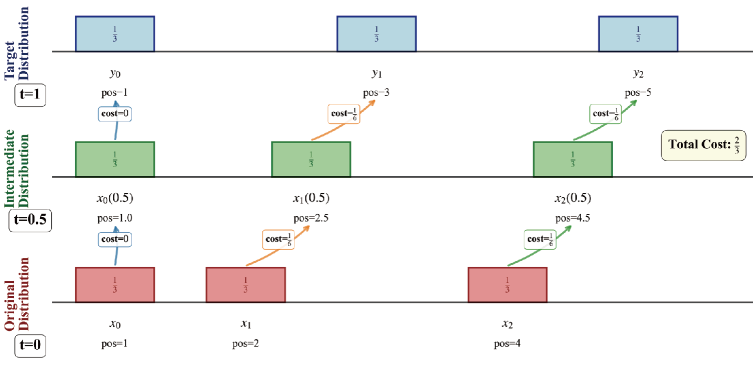
Оптимальная транспортировка (Optimal Transport, OT) представляет собой мощный математический аппарат для сопоставления распределений вероятностей, позволяющий рассматривать процесс генерации данных как физический процесс. В основе OT лежит задача нахождения наиболее экономичного способа перемещения «массы» из одного распределения в другое, измеряемого с помощью функции стоимости. Это позволяет формализовать задачу генерации как минимизацию этой стоимости, используя методы, разработанные в физике, такие как принципы наименьшего действия. Математически, задача OT формулируется как поиск транспортного плана \gamma(x,y) минимизирующего функционал \in t \gamma(x,y) c(x,y) dx dy , где c(x,y) — функция стоимости перемещения единицы массы из точки x в точку y . Применение OT в генеративных моделях позволяет обеспечить согласованность и реалистичность сгенерированных данных, поскольку модель обучается «переносить» статистические свойства исходных данных в пространство сгенерированных данных.
Использование Optimal Transport автоматически включает в себя принципы Континуальной Механики, позволяя моделировать деформацию и взаимодействие данных в Пространстве Признаков. В данном контексте, данные рассматриваются как континуум, где ∇ (оператор набла) описывает градиент плотности вероятности, а тензор деформации характеризует изменение структуры данных при генерации. Это позволяет не только создавать более реалистичные образцы, но и контролировать физически правдоподобные изменения в сгенерированных данных, моделируя их как непрерывную среду, подверженную деформациям и взаимодействиям.
Архитектуры для Физически Обоснованной Генерации
В настоящее время активно развиваются различные генеративные модели, использующие принципы, лежащие в основе создания реалистичных данных. Среди наиболее заметных — диффузионные модели (Diffusion Models), основанные на постепенном добавлении шума к данным и последующем его удалении, и вариационные автоэнкодеры (Variational Autoencoders), использующие вероятностные методы для кодирования и декодирования данных. Обе эти архитектуры позволяют создавать новые образцы, схожие с обучающей выборкой, и находят применение в задачах генерации изображений, звука и других типов данных. Они отличаются подходами к представлению и обработке данных, но преследуют общую цель — генерацию высококачественного и разнообразного контента.
Потоковые модели (Flow-based Models) представляют собой альтернативный подход к генеративному моделированию, основанный на использовании обратимых преобразований. В отличие от других генеративных моделей, требующих приближенных методов вычисления правдоподобия, потоковые модели позволяют точно вычислить вероятность данных p(x) благодаря своей структуре. Это достигается путем построения цепочки обратимых преобразований, которые отображают простое распределение (например, гауссовское) в сложное распределение данных. Точность вычисления правдоподобия делает потоковые модели особенно полезными в задачах, где оценка вероятности имеет критическое значение, а также упрощает процесс обучения и анализа модели.
Нейронные сети, учитывающие физические ограничения (Physics-Informed Neural Networks, PINN), непосредственно включают уравнения, описывающие физические процессы, в структуру обучения. Это позволяет повысить реалистичность и точность генерируемых результатов, поскольку модель вынуждена соответствовать известным физическим законам. В отличие от традиционных методов, таких как метод конечных элементов (Finite Element Method, FEM), PINN предлагают альтернативный подход к решению задач, требующих учета физических ограничений. В наших исследованиях, разработанный подход CM-GAI демонстрирует высокую точность, достигая среднеквадратичной нормализованной ошибки (NRMSE) всего 0.56% и 1.10% в стандартных задачах, что подтверждает эффективность интеграции физических ограничений в процесс обучения нейронной сети.

Навигация в Высокой Размерности и За Ее Пределами
Проблема «проклятия размерности» возникает, когда анализ данных с большим количеством признаков становится вычислительно невозможным и статистически ненадежным. Для эффективной работы с такими данными применяются методы понижения размерности. Эти методы, такие как анализ главных компонент или t-SNE, позволяют выделить наиболее значимые признаки, сохранив при этом максимальное количество информации. В результате, сложность данных снижается, что облегчает их визуализацию, моделирование и интерпретацию. Понижение размерности не только улучшает производительность алгоритмов машинного обучения, но и позволяет выявлять скрытые закономерности и взаимосвязи в данных, которые были бы невидимы в исходном пространстве высокой размерности. Таким образом, это важный этап в обработке сложных наборов данных, обеспечивающий более эффективный и точный анализ.
Исследование неевклидовых пространств открывает новые возможности для представления данных, выходящие за рамки привычных координат и расстояний. Традиционные методы, основанные на евклидовой геометрии, могут оказаться неэффективными при работе со сложными, многомерными данными, поскольку не учитывают нелинейные зависимости и скрытые структуры. Переход к неевклидовым пространствам, таким как гиперболические или сферические, позволяет более точно отразить взаимосвязи между объектами, выявлять кластеры и аномалии, которые были бы незаметны в евклидовом пространстве. Это особенно актуально в областях, где данные обладают сложной геометрией, например, в обработке изображений, анализе социальных сетей и биоинформатике. Использование метрик, отличных от евклидова расстояния, позволяет учитывать специфические особенности данных и повысить точность моделирования, что приводит к более реалистичным и информативным результатам.
Авторегрессионные модели, в частности, трансформеры, предварительно обученные на больших объемах данных, представляют собой значительный шаг вперед в обработке естественного языка. Эти модели, предсказывая следующий элемент в последовательности на основе предыдущих, демонстрируют поразительную способность к генерации связного и контекстуально релевантного текста. В отличие от традиционных подходов, трансформеры используют механизм внимания, позволяющий учитывать взаимосвязи между всеми элементами входной последовательности, а не только ближайшими. Это позволяет им эффективно моделировать сложные языковые структуры и понимать нюансы смысла. Подобная архитектура обеспечивает выдающиеся результаты в задачах машинного перевода, суммаризации текста, генерации контента и даже в создании креативных текстов, открывая новые горизонты в области искусственного интеллекта и взаимодействия человека с компьютером.
Будущее Физически Обоснованной Генерации
Следующее поколение генеративного искусственного интеллекта будет формироваться за счет объединения подходов, основанных на данных, и физически обоснованных моделей. Традиционные методы машинного обучения часто требуют огромных объемов данных для достижения приемлемой точности, в то время как физические модели, хотя и точны, могут быть вычислительно дорогими и сложными в применении к новым сценариям. Новая парадигма предполагает интеграцию этих двух подходов: использование данных для обучения и уточнения физических моделей, а также для ускорения вычислений и расширения области применения. Такой симбиоз позволяет создавать генеративные модели, которые не только воспроизводят наблюдаемые данные, но и учитывают фундаментальные законы физики, обеспечивая более реалистичные, надежные и обобщающие результаты в различных областях, от разработки материалов до климатического моделирования.
Принцип Гамильтона, фундаментальный в классической механике, оказывается мощной теоретической базой для создания более надежных и эффективных генеративных алгоритмов. В его основе лежит идея о том, что динамика физической системы определяется стремлением к минимизации действия — интеграла от лагранжиана по времени. Применяя этот принцип к задачам генерации, исследователи стремятся разработать алгоритмы, которые не просто воспроизводят данные, но и учитывают фундаментальные физические законы, лежащие в их основе. Такой подход позволяет создавать модели, которые демонстрируют более высокую устойчивость к шуму и способны экстраполировать за пределы обучающих данных, генерируя правдоподобные и физически корректные результаты. \delta S = 0 — где S — действие, является ключевым уравнением, определяющим траекторию системы, и аналогичным образом может быть использовано для оптимизации параметров генеративной модели.
Сочетание возможностей, предоставляемых данными, и фундаментальных законов физики открывает принципиально новые перспективы в различных областях науки и техники. Подход CM-GAI, разработанный для генеративного искусственного интеллекта, демонстрирует впечатляющую точность даже при ограниченном объеме обучающих данных. В частности, исследования показали, что данный метод позволяет достичь среднеквадратичной нормализованной ошибки (NRMSE) всего в 0.56% при моделировании температурно-зависимых полей напряжений и 1.10% для полей пластической деформации. Такая высокая эффективность позволяет применять CM-GAI в самых разных сферах — от разработки новых материалов с заданными свойствами до создания более точных и реалистичных климатических моделей, значительно расширяя горизонты прогнозирования и анализа.
![Сравнение результатов, полученных с помощью модели Guo et al. [21] и предсказаний CM-GAI, демонстрирует их соответствие.](https://arxiv.org/html/2601.20462v1/x29.png)
Представленная работа демонстрирует стремление к математической чистоте в области искусственного интеллекта. Авторы, используя принципы континуальной механики и оптимального транспорта, создают модель, способную к генерации данных даже при ограниченном объеме обучающих выборок. Этот подход, требующий решения транспортной задачи с использованием нейронных сетей, обусловленных физикой, является ярким примером доказательной корректности алгоритма. Как однажды заметила Ада Лавлейс: «То, что можно выразить с помощью математических символов, может быть выражено с помощью кода». Использование математического аппарата для определения и управления вероятностными распределениями в пространствах признаков, как это реализовано в CM-GAI, подтверждает эту мысль, акцентируя внимание на важности строгости и точности в алгоритмических решениях.
Что Дальше?
Предложенный подход, сочетающий в себе строгую математику континуальной механики и гибкость генеративных моделей, открывает перспективные пути, но не избавляет от необходимости критического осмысления. Очевидно, что эффективность метода, зависящая от корректной постановки транспортной задачи, остро нуждается в более глубоком исследовании в контексте неполных и зашумленных данных. Необходимо разработать устойчивые алгоритмы решения, способные противостоять возмущениям, ведь в хаосе данных спасает только математическая дисциплина. Представленные результаты демонстрируют потенциал, но реальная применимость, особенно в задачах, требующих высокой точности, пока остаётся предметом дальнейших исследований.
Ключевым направлением представляется расширение области применения оптимального транспорта за пределы евклидовых пространств. Работа с многообразиями, хотя и заявлена, требует разработки эффективных и масштабируемых методов вычисления метрик и решения транспортных задач на этих пространствах. Особый интерес представляет адаптация метода к данным, представленным в виде графов или других нерегулярных структур, где стандартные инструменты континуальной механики неприменимы напрямую.
Наконец, стоит признать, что текущая реализация, использующая нейронные сети, хоть и удобна, не лишена недостатков. Необходимы альтернативные подходы, гарантирующие доказуемость и предсказуемость решения, а не полагающиеся на эмпирическую оценку производительности. Истинная элегантность алгоритма проявляется в его математической чистоте, а не в способности «работать на тестах».
Оригинал статьи: https://arxiv.org/pdf/2601.20462.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Взлом языковых моделей: эволюция атак, а не подсказок
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Кванты в Финансах: Не Шутка!
- Квантовый оптимизатор: Новый подход к сложным задачам
- Разделяй и властвуй: Новый подход к классификации текстов
- Врачебные диагнозы и искусственный интеллект: как формируются убеждения?
- Обучение с подкреплением и причинность: как добиться надёжных выводов
- Глубокое обучение на службе обратных задач: новый взгляд на оптимизацию
2026-01-30 05:51