Автор: Денис Аветисян
Исследователи представляют GutenOCR — семейство моделей, объединяющих зрение и язык для более точного и структурированного понимания документов.

GutenOCR — это фронтенд для оптического распознавания символов, основанный на мультимодальном обучении и обеспечивающий управляемое поведение при чтении документов.
Несмотря на значительные успехи в области оптического распознавания символов (OCR), извлечение структурированной информации из документов остается сложной задачей. В данной работе представлена система ‘GutenOCR: A Grounded Vision-Language Front-End for Documents’, представляющая собой семейство моделей, основанных на архитектуре Vision-Language, и предназначенных для создания “заземленного” OCR-интерфейса. Модели GutenOCR, обученные на бизнес-документах и научных статьях, демонстрируют более чем двукратное увеличение эффективности по сравнению с базовой моделью Qwen2.5-VL-7B в задачах распознавания, обнаружения и “привязки” текста к его местоположению на странице. Каковы перспективы использования подобных моделей для автоматизации обработки документов и извлечения знаний из неструктурированных данных?
Основы: Новая парадигма оптического распознавания символов
Традиционные методы оптического распознавания символов (OCR) часто сталкиваются с серьезными трудностями при обработке документов со сложной структурой и различными дефектами качества. Неровное освещение, искажения, шум, размытость изображений, а также наличие таблиц, многоколоночного текста и нестандартных шрифтов существенно снижают точность распознавания. В результате, стандартные алгоритмы часто терпят неудачу при анализе реальных документов, таких как сканы исторических текстов, рукописные заметки или сложные формы, ограничивая их практическое применение и требуя значительных усилий по предварительной обработке и ручной коррекции ошибок. Эта неспособность адаптироваться к разнообразию реальных документов представляет собой ключевое препятствие для автоматизации процессов, связанных с извлечением информации из визуального контента.
Современные системы оптического распознавания символов (OCR) часто сталкиваются с трудностями при обработке документов сложной структуры или низкого качества. Однако, использование так называемых “базовых моделей”, предварительно обученных на огромных массивах данных, открывает новые возможности в этой области. Эти модели, изначально предназначенные для задач обработки естественного языка, способны к “переносу знаний” — трансферному обучению — что позволяет им эффективно адаптироваться к задачам распознавания текста на изображениях. Благодаря предварительному обучению на колоссальных объемах данных, модели приобретают глубокое понимание языковых закономерностей и визуальных признаков, что значительно повышает их устойчивость к вариациям в шрифтах, освещении и дефектах изображений. Такой подход позволяет добиться более высокой точности и надежности распознавания текста, даже в сложных и неидеальных условиях, существенно расширяя сферу применения OCR-технологий.
Для достижения оптимальной производительности в задачах оптического распознавания символов (OCR) требуется специализированная донастройка предварительно обученных фундаментальных моделей. Простое применение этих моделей, изначально ориентированных на общее понимание языка, недостаточно для эффективной обработки визуального текста. Донастройка предполагает адаптацию модели к специфике OCR — включая работу с различными шрифтами, искажениями, сложными макетами документов и шумами. Этот процесс позволяет “перевести” общие лингвистические знания модели в способность точно извлекать текст из изображений, преодолевая разрыв между общим пониманием языка и конкретной задачей визуального извлечения информации. Успешная донастройка значительно повышает надежность и точность OCR, открывая возможности для автоматизированной обработки документов в различных областях.

Строительные блоки: от базовых моделей к специализированному OCR
Модели Qwen2.5-VL-3B и Qwen2.5-VL-7B являются базовыми моделями, объединяющими возможности компьютерного зрения и обработки естественного языка. Они предварительно обучены на обширных наборах данных изображений и текста, что позволяет им выполнять широкий спектр задач, включая понимание содержимого изображений и генерацию текстовых описаний. В частности, модели способны извлекать визуальную информацию из изображений и сопоставлять её с соответствующими текстовыми данными, что является основой для решения задач, требующих взаимодействия между визуальным и текстовым контентом. Объем параметров моделей — 3 миллиарда и 7 миллиардов соответственно — определяет их вычислительные требования и потенциальную производительность.
Для адаптации базовых моделей Qwen2.5-VL-3B и Qwen2.5-VL-7B к задачам оптического распознавания символов (OCR) применяется контролируемое обучение с учителем (supervised fine-tuning). Этот процесс включает в себя обучение моделей на размеченных данных, содержащих изображения текста и соответствующие текстовые метки. В ходе контролируемого обучения параметры предобученной модели корректируются для минимизации ошибки распознавания текста на целевых изображениях. Такая адаптация позволяет оптимизировать производительность моделей в задачах визуального извлечения текста, повышая точность и скорость распознавания по сравнению с использованием базовых моделей без дополнительной настройки.
GutenOCR-3B и GutenOCR-7B созданы посредством контролируемого дообучения моделей Qwen2.5-VL-3B и Qwen2.5-VL-7B, соответственно. Использование предварительно обученных моделей в качестве отправной точки позволяет значительно ускорить процесс обучения специализированной системы оптического распознавания символов (OCR). Предварительное обучение на обширных массивах данных изображений и текста обеспечивает моделям GutenOCR-3B и GutenOCR-7B начальные знания о визуальных особенностях текста, что приводит к повышению точности распознавания и снижению объема необходимых размеченных данных для дообучения.

Подтвержденные результаты: точность и понимание структуры
Модели GutenOCR-3B и GutenOCR-7B демонстрируют существенное повышение точности распознавания текста, что обеспечивает более надежную транскрипцию изображений. Улучшение в точности чтения позволяет снизить количество ошибок при преобразовании изображений в текст, что критически важно для задач оцифровки документов и автоматизированной обработки изображений. Повышенная надежность транскрипции способствует снижению необходимости ручной коррекции и повышению эффективности рабочих процессов, связанных с обработкой текстовой информации из визуальных источников.
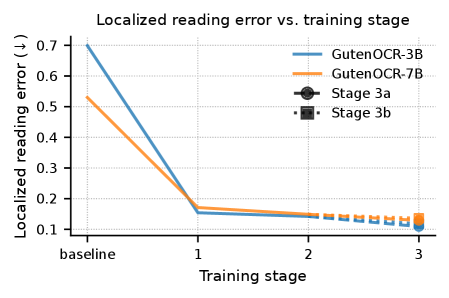
Модели GutenOCR-3B и GutenOCR-7B демонстрируют значительное снижение частоты ошибок распознавания символов (CER) при локальном чтении — от 0.11 до 0.20. Это представляет собой существенное улучшение по сравнению с базовыми моделями Qwen, у которых CER составлял приблизительно 0.7/0.53. Локальное чтение позволяет повысить точность за счет анализа текста в конкретных областях изображения, что приводит к более надежной транскрипции и снижению количества ошибок в распознанном тексте.
Модели GutenOCR-3B и GutenOCR-7B демонстрируют высокую точность обнаружения текста на полных страницах изображений, достигая значения F1-меры в диапазоне 0.75-0.82. Этот показатель значительно превосходит результаты, полученные на базовых моделях, что свидетельствует о существенном улучшении способности моделей правильно идентифицировать и локализовать текстовые строки на изображениях. Повышенная точность обнаружения способствует более надежной и полной транскрипции текста из визуальных источников.
Обе модели, GutenOCR-3B и GutenOCR-7B, включают в себя функциональность, учитывающую структуру документа, что позволяет сохранять исходное форматирование при распознавании текста. Это достигается за счет использования структурированного вывода данных, где информация о расположении текста (например, координаты строк и абзацев) сохраняется и передается вместе с самим текстом. Такой подход значительно упрощает последующую обработку данных, позволяя, например, восстановить оригинальный макет документа или выполнить более точный анализ его содержимого, что особенно важно для задач, требующих сохранения контекста и визуальной информации.
Функция локального чтения в GutenOCR-3B и GutenOCR-7B обеспечивает повышенную точность распознавания текста за счет анализа текста в определенных областях изображения. Вместо обработки изображения целиком, модели фокусируются на небольших участках, что позволяет снизить влияние шумов и артефактов, а также улучшить обработку текста с различным качеством или ориентацией. Такой подход позволяет добиться более надежного извлечения текста из изображений с сложной структурой или повреждениями, и существенно повышает точность по сравнению с методами, обрабатывающими изображение как единое целое.

Строгая валидация и широкие перспективы
Исследования, проведенные на базе OmniDocBench, наглядно демонстрируют устойчивую работу моделей GutenOCR-7B и GutenOCR-3B при обработке документов различных типов и в разнообразных условиях. Оценивалось качество распознавания текста в документах, отличающихся по структуре, качеству изображения и степени повреждений. Результаты показывают, что обе модели стабильно сохраняют высокую точность, успешно справляясь как с четкими, отсканированными документами, так и с изображениями низкого качества или содержащими искажения. Это подтверждает надежность и универсальность GutenOCR в реальных сценариях применения, где входные данные часто далеки от идеала, и подчеркивает возможность использования моделей в широком спектре задач, связанных с автоматической обработкой документов.
Комплексное тестирование моделей на базе FoxBenchmark подтвердило их высокую эффективность в задачах оптического распознавания символов (OCR), извлечения информации и визуального анализа. Данная методика позволила оценить способность моделей не только точно распознавать текст, но и понимать его контекст, а также находить и извлекать конкретные фрагменты информации на основе заданных критериев. Результаты демонстрируют, что модели успешно справляются с широким спектром задач, требующих сочетания навыков OCR, поиска и логического анализа визуальных данных, что открывает перспективы для создания более интеллектуальных систем обработки документов и автоматизации рабочих процессов.
Ключевой особенностью GutenOCR-7B и GutenOCR-3B является возможность условного обнаружения, позволяющая осуществлять целенаправленное извлечение текста на основе заданных критериев. Эта функция значительно расширяет спектр применения моделей, выходя за рамки простого распознавания символов. Вместо извлечения всего текста со страницы, системы способны фокусироваться на конкретных областях или элементах, например, на извлечении информации из таблиц, полей форм или выделении определенных типов данных, таких как даты или суммы. Благодаря этому, модели открывают новые возможности для автоматизации сложных рабочих процессов, анализа структурированных документов и создания интеллектуальных систем обработки информации, где требуется не просто чтение текста, а его осмысленное извлечение и интерпретация.
Результаты тестирования показали значительное повышение точности распознавания текста в новых моделях. По сравнению с базовыми моделями Qwen, разработанные системы демонстрируют приблизительное снижение показателя полной ошибки распознавания символов (CERe2e) на 50%. Это указывает на существенное улучшение способности моделей к чтению и интерпретации текста на уровне целой страницы, что особенно важно для работы с большими объемами документов и сложными макетами. Достигнутое снижение ошибки позволяет надеяться на более качественную автоматизацию процессов, связанных с обработкой и анализом текстовой информации.
Модели демонстрируют высокую точность при поиске заданных фраз непосредственно на страницах документов, достигая показателя F1 в диапазоне 0.85-0.90. Этот результат свидетельствует о способности систем не просто распознавать текст, но и понимать его контекст, эффективно выделяя конкретные фрагменты информации по запросу. Такая фразо-зависимая детекция открывает широкие возможности для автоматизированного извлечения данных, например, для поиска определенных дат, сумм или ключевых терминов в больших объемах документов, значительно упрощая и ускоряя процессы анализа и обработки информации.
Повышенная точность и понимание структуры документов, обеспечиваемые данными моделями, открывают новые возможности для создания продвинутых систем обработки документов и автоматизации рабочих процессов. Благодаря способности не только распознавать текст, но и интерпретировать его контекст и расположение на странице, появляется возможность для автоматического извлечения информации, анализа сложных форм и документов, а также для создания интеллектуальных систем архивирования и поиска. Это позволяет существенно сократить время и ресурсы, затрачиваемые на ручную обработку документов, и повысить эффективность работы в различных областях, начиная от финансового сектора и заканчивая архивным делом и научными исследованиями. Перспективы включают в себя автоматизацию процессов выставления счетов, обработки страховых претензий, анализа юридических документов и даже автоматическое создание аннотаций к научным статьям.
Представленная работа демонстрирует элегантный подход к задаче оптического распознавания символов, превосходящий традиционные методы. GutenOCR, как front-end для vision-language моделей, предлагает не просто распознавание текста, а его структурированное понимание и контролируемое извлечение. Это соответствует философии, что истинная эффективность заключается в гармонии между формой и функцией. Как однажды заметил Эндрю Ын: «Мы должны стремиться к созданию систем, которые не просто работают, а делают это красиво и понятно». Особенно ценным является акцент на структурированном выводе, позволяющем более эффективно использовать извлеченную информацию в downstream-задачах. Такой подход подчеркивает, что рефакторинг — это искусство, позволяющее улучшить не только технические характеристики, но и удобство использования системы.
Куда же дальше?
Представленная работа, безусловно, демонстрирует изящный подход к задаче распознавания текста в документах. GutenOCR, как передний край взаимодействия зрения и языка, намекает на то, что истинное понимание документа требует не просто извлечения символов, но и их осмысленного связывания с контекстом. Однако, стоит признать, что совершенство в этой области — иллюзия, к которой можно лишь приблизиться. Проблема «шума» в реальных документах, разнообразие стилей и форматов, а также необходимость учета неявных связей между элементами — всё это требует дальнейшей, кропотливой работы.
Настоящий вызов заключается не в увеличении точности распознавания отдельных символов, а в создании систем, способных к адаптации и самообучению. Представьте себе модель, которая не просто «читает» документ, но и «понимает» его структуру, улавливает нюансы авторского стиля, и даже предсказывает намерения автора. Это требует не только развития архитектур машинного обучения, но и более глубокого осмысления самой природы информации и ее представления.
Истинно элегантное решение, вероятно, будет заключаться в создании систем, которые не навязывают пользователю свою логику, а предлагают гибкий инструмент для исследования и интерпретации документа. Подобно хорошему архитектору, GutenOCR закладывает прочный фундамент, но дальнейшее развитие потребует от нас не только технической изобретательности, но и философского осмысления роли технологии в познании мира.
Оригинал статьи: https://arxiv.org/pdf/2601.14490.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Метаболический профиль СДВГ: новый взгляд на диагностику
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Квантовая криптография: от теории к практике
2026-01-22 21:09