Автор: Денис Аветисян
Исследователи представили систему, которая позволяет агентам эффективно извлекать информацию из сложных документов, используя их структуру для более точного и быстрого ответа на вопросы.
DeepRead: Структурно-ориентированное рассуждение для улучшения агентного поиска и ответов на вопросы по документам.
Несмотря на успехи в области извлечения знаний из документов с помощью агентов, существенные ограничения сохраняются при работе с длинными текстами, где игнорируется внутренняя структура документа. В данной работе, ‘DeepRead: Document Structure-Aware Reasoning to Enhance Agentic Search’, представлена новая система, использующая координатную навигацию по структуре документа для повышения эффективности и точности ответов на вопросы. Предложенный подход позволяет агенту учитывать иерархию и последовательность изложения, что значительно улучшает результаты по сравнению с традиционными методами поиска. Сможет ли подобный учет структуры документа привести к созданию агентов, способных к более глубокому пониманию и анализу больших объемов текстовой информации?
Погоня за контекстом: проблема больших документов и извлечения знаний
Современные большие языковые модели (LLM) демонстрируют впечатляющие способности в обработке языка, однако их эффективность значительно снижается при решении задач, требующих обширных знаний. Ограничение связано с фиксированным размером контекстного окна — объема текста, который модель способна одновременно анализировать. Несмотря на способность генерировать связные и грамматически правильные тексты, LLM испытывают трудности с точным извлечением и применением информации из больших объемов данных. Это фундаментальное ограничение препятствует использованию моделей в задачах, требующих глубокого понимания сложных текстов, таких как анализ юридических документов, научных статей или обширных баз данных, где релевантная информация может быть разбросана по всему тексту.
При попытке предоставить большие объемы информации языковым моделям посредством простого объединения текстов, возникают существенные трудности. Такой подход, несмотря на свою кажущуюся простоту, быстро теряет эффективность при работе со сложными или объемными документами. Модель, перегруженная избыточными данными, испытывает сложности в выделении релевантных фрагментов и установлении логических связей между ними. В результате, точность ответов снижается, а вероятность получения неверной или неполной информации возрастает. Это связано с тем, что стандартные механизмы внимания, используемые в архитектуре языковых моделей, не способны эффективно обрабатывать чрезмерно длинные последовательности текста, что приводит к потере важных деталей и искажению смысла.
Ограниченность контекстного окна больших языковых моделей (LLM) существенно затрудняет точное рассуждение и надежное генерирование ответов при работе с реальными источниками информации. Когда модель сталкивается с объемными документами или сложными знаниями, она не способна удержать в памяти всю необходимую информацию для формирования корректного ответа. Это приводит к тому, что ответы могут быть неполными, неточными или даже противоречивыми, поскольку модель вынуждена оперировать лишь фрагментами контекста. В результате, надежность системы снижается, а ее способность к решению сложных задач, требующих глубокого понимания предметной области, существенно ограничивается. Особенно критично это проявляется при анализе научных статей, юридических документов или других специализированных текстов, где каждая деталь может иметь решающее значение.
Первые системы генерации с расширением извлечением (RAG), в частности, простые одношаговые конвейеры, представляли собой частичное решение проблемы ограниченного контекста больших языковых моделей. Однако, эти системы зачастую не учитывали структуру документов, обрабатывая их как непрерывный поток текста. Это приводило к потере важной информации, связанной с иерархией разделов, заголовков и подзаголовков, что существенно ограничивало их способность к точному рассуждению и генерации надежных ответов на сложные вопросы, требующие глубокого понимания контекста документа. В результате, несмотря на определенный прогресс, ранние системы RAG не могли в полной мере использовать потенциал содержащейся в документах информации, нуждаясь в более сложных подходах к анализу и представлению знаний.
Эволюция RAG: от простого поиска к интеллектуальному извлечению
Современные системы RAG (Retrieval-Augmented Generation) выходят за рамки простого извлечения релевантных документов. Вместо однократного поиска, они используют итеративное извлечение, при котором система последовательно уточняет запрос и извлекает дополнительную информацию на основе предыдущих результатов. Также внедряются методы планирования, позволяющие системе определить оптимальную стратегию поиска, разбив сложный вопрос на более мелкие подзадачи и последовательно извлекая информацию для каждой из них. Такой подход значительно повышает эффективность сбора информации, особенно в случаях, когда ответ требует синтеза данных из нескольких источников или анализа сложной предметной области.
Грубая к точной переранжировка (coarse-to-fine reranking) представляет собой метод улучшения релевантности и точности контекста, предоставляемого LLM. Изначально, система извлекает большой набор документов, соответствующих запросу. Затем, применяется многоступенчатый процесс переранжировки: сначала используется быстрая, но менее точная модель для отсеивания очевидно нерелевантных документов (грубая ранжировка). После этого, оставшиеся документы оцениваются более сложной и ресурсоемкой моделью, которая учитывает более тонкие аспекты семантической близости к запросу и контексту (точная ранжировка). Этот процесс позволяет значительно повысить качество контекста, предоставляемого LLM, что приводит к более точным и обоснованным ответам.
В основе большинства конвейеров RAG (Retrieval-Augmented Generation) лежит принцип поиска информации на основе семантической схожести, обеспечиваемый моделями эмбеддингов. Эти модели преобразуют текстовые данные в векторные представления, позволяющие количественно оценить семантическое значение текста. При запросе пользователя, запрос также преобразуется в вектор, и производится поиск в векторной базе данных документов, находящихся наиболее близко к вектору запроса по метрикам, таким как косинусное расстояние. Эффективность моделей эмбеддингов напрямую влияет на качество извлекаемой информации, поскольку они определяют, насколько точно найденные документы соответствуют смысловому содержанию запроса. Современные модели, такие как Sentence Transformers и OpenAI Embeddings, демонстрируют высокую производительность в различных задачах, обеспечивая надежный фундамент для систем RAG.
Совершенствование архитектур RAG (Retrieval-Augmented Generation) напрямую влияет на качество контекста, предоставляемого большой языковой модели (LLM). Более эффективные методы извлечения информации, такие как итеративный поиск и переранжировка, позволяют LLM получать более релевантные и точные данные. Это, в свою очередь, значительно повышает способность модели генерировать ответы, которые не только грамматически корректны, но и содержательно обоснованы, а также соответствуют предоставленному контексту и требованиям пользователя. Улучшение качества контекста минимизирует вероятность генерации галлюцинаций и неверной информации, что критически важно для надежности и полезности LLM в различных приложениях.
DeepRead: агент для структурированного анализа документов
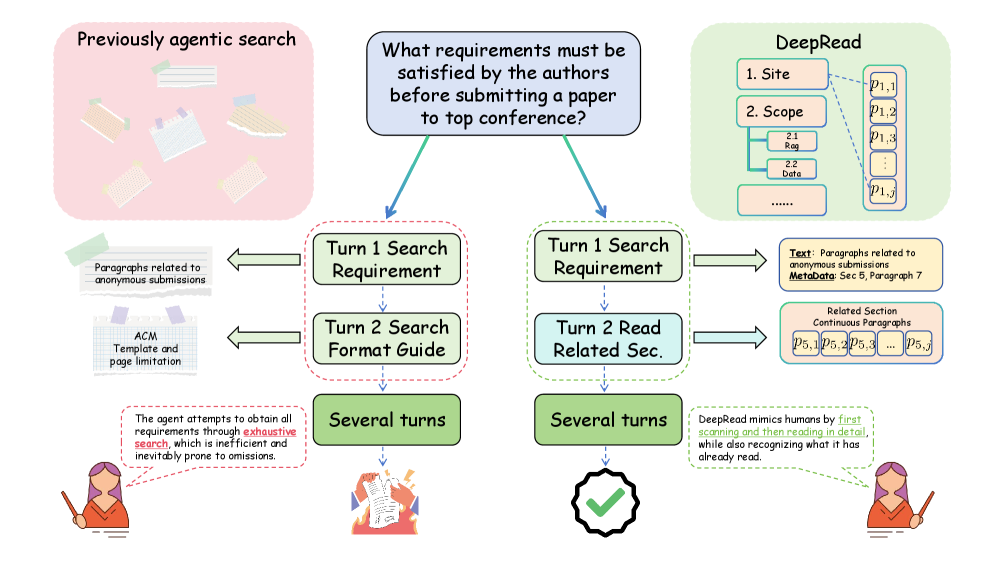
В отличие от традиционных систем RAG (Retrieval-Augmented Generation), которые часто игнорируют внутреннюю структуру документов, DeepRead явно моделирует иерархию документа и последовательность его частей. Это достигается путем представления документа не как единый блок текста, а как структурированный набор секций и элементов, что позволяет агенту учитывать логическую организацию информации. В частности, DeepRead использует информацию о порядке секций и их взаимосвязи, что позволяет ему более эффективно извлекать и синтезировать релевантные фрагменты текста для ответа на вопросы, преодолевая ограничения, связанные с отсутствием понимания структуры документа, характерные для многих существующих систем.
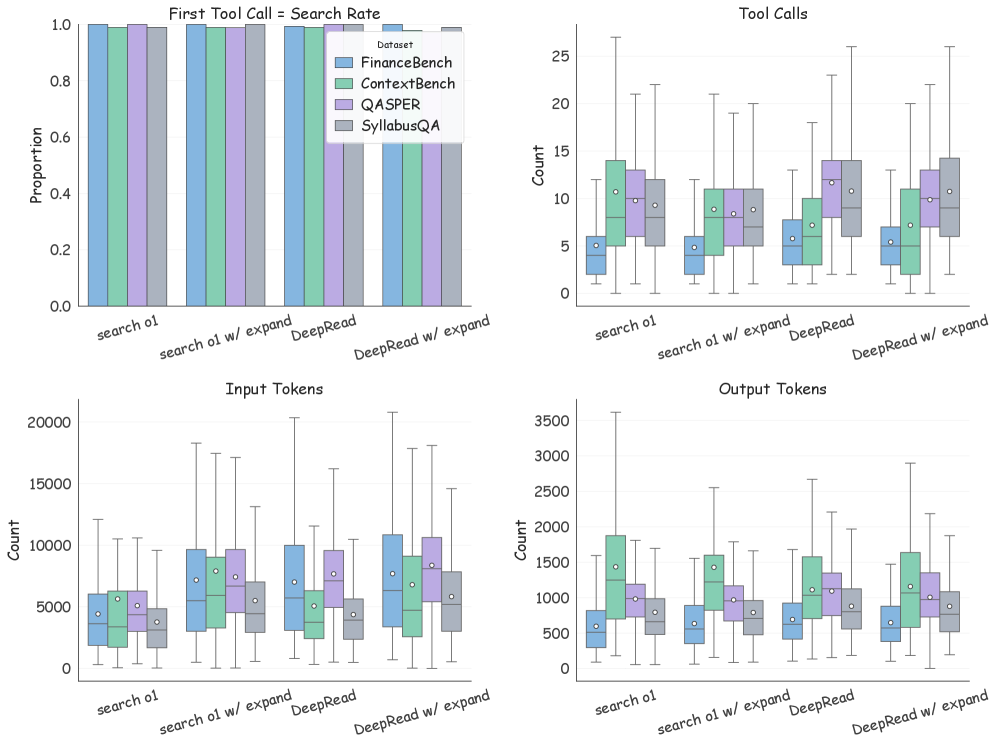
Для работы с документами DeepRead использует специализированные инструменты, такие как Retrieve Tool и ReadSection Tool. Retrieve Tool предназначен для поиска релевантных фрагментов документа, учитывая его структуру, в то время как ReadSection Tool обеспечивает последовательное чтение этих фрагментов, сохраняя оригинальный порядок представления информации. Такой подход, называемый scanning-aware localization и contiguous reading, позволяет агенту эффективно перемещаться по документу, избегая разрозненного извлечения информации и поддерживая контекст, заданный структурой документа. Это особенно важно для длинных и сложных документов, где понимание организации текста критически важно для точного ответа на вопросы.
В отличие от многих агентских систем RAG, страдающих от “структурной слепоты”, DeepRead использует систему координат для точного определения местоположения текста внутри документа и учитывает последовательность документа. Это позволяет DeepRead осознанно обрабатывать иерархическую структуру документа, а не рассматривать текст как неструктурированный поток. Вместо абстрактных идентификаторов, система координат предоставляет абсолютные позиции текста, что необходимо для эффективной навигации и извлечения информации в рамках документальной структуры. Учет последовательности документа гарантирует, что при чтении и анализе текста сохраняется логический порядок, что критически важно для понимания контекста и ответа на вопросы.
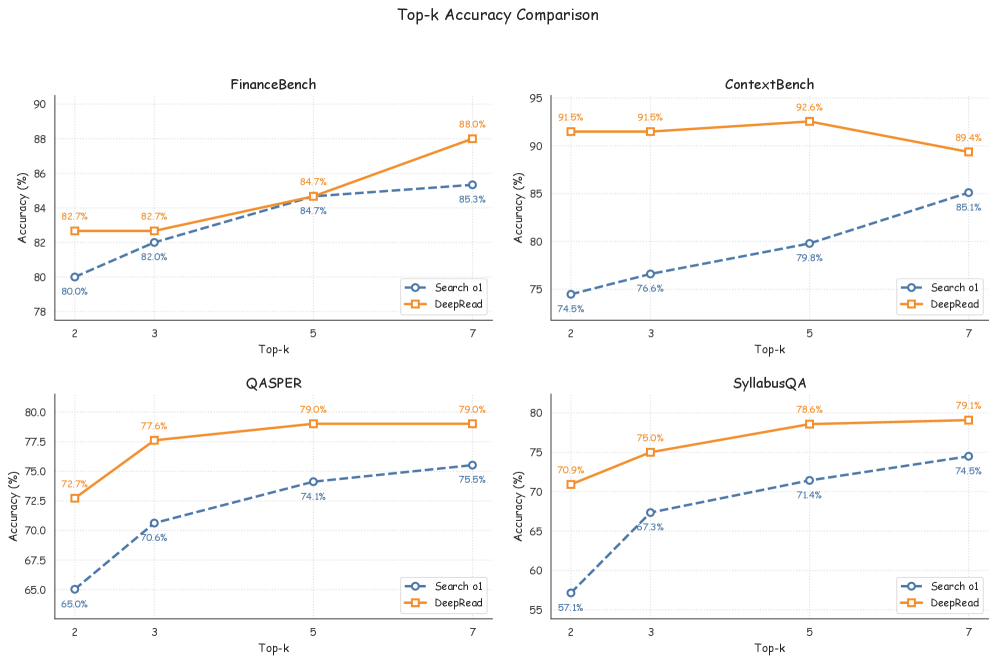
Результаты оценки DeepRead, проведенной с использованием модели DeepSeek V3.2 и генерации вопросов с помощью GLM-4.7, демонстрируют превосходство системы в многошаговых задачах вопросно-ответного взаимодействия (QA). Средняя точность DeepRead на четырех стандартных бенчмарках составила 79.5%, что на 10.3 процентных пункта выше, чем у современных аналогов. Данный показатель подтверждает эффективность подхода, основанного на моделировании структуры документа и последовательности его частей, для повышения качества ответов в сложных QA сценариях.
От необработанных документов к структурированным знаниям
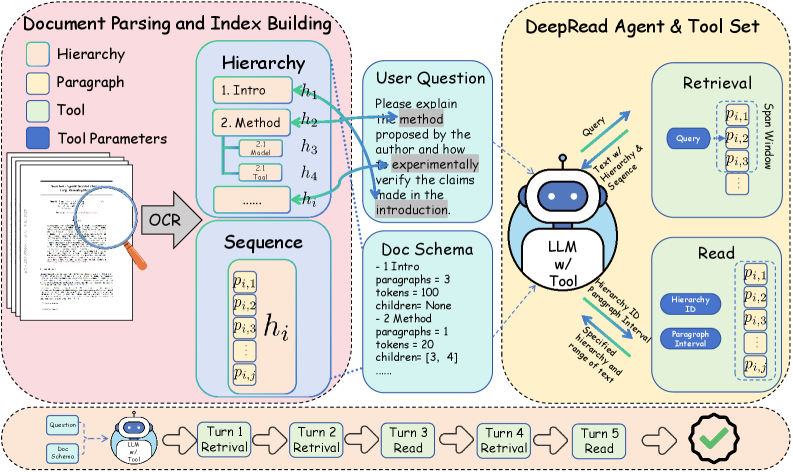
Многомодальные модели парсинга используются для преобразования изображений документов в структурированное представление, сохраняя при этом информацию о макете и организационной структуре. Этот процесс включает в себя не только извлечение текста, но и распознавание визуальных элементов, таких как заголовки, таблицы, списки и изображения, а также их взаимосвязь. Сохранение информации о макете, включая положение текста и графических элементов на странице, критически важно для понимания логической структуры документа и обеспечения точной интерпретации его содержания. В результате формируется представление, которое позволяет алгоритмам эффективно ориентироваться в документе и извлекать из него знания.
Оптическое распознавание символов (OCR) является основой моделей, преобразующих изображения документов в текстовый формат. Данный процесс включает в себя анализ растрового изображения и идентификацию символов, что позволяет извлечь текст из изображений, сканов или фотографий документов. Точность OCR критически важна для последующего структурирования и анализа информации, поскольку ошибки распознавания могут привести к искажению данных. Современные OCR-системы используют алгоритмы машинного обучения для повышения точности, особенно в случаях нечетких изображений или нестандартных шрифтов. Извлеченный текст затем служит входными данными для более сложных моделей обработки документов.
В основе конвейера обработки документов лежит мощный движок оптического распознавания символов (OCR) PaddleOCR-VL, использующий возможности VLLM. PaddleOCR-VL обеспечивает высокую точность извлечения текста из изображений документов, включая сложные макеты и различные шрифты. VLLM, как фреймворк для вывода больших языковых моделей, оптимизирует процесс обработки и позволяет эффективно масштабировать распознавание на больших объемах данных. Данная комбинация технологий позволяет извлекать текстовую информацию из документов с высокой скоростью и надежностью, подготавливая ее для дальнейшего структурирования и анализа.
Структурированное представление документов, полученное в результате обработки, обеспечивает эффективную навигацию и логический анализ сложных документов системой DeepRead. Это позволяет DeepRead не просто извлекать текст, но и понимать взаимосвязи между различными элементами документа, такими как заголовки, таблицы и абзацы. В результате, система способна более точно извлекать релевантную информацию, отвечать на вопросы, касающиеся содержимого документа, и выполнять сложные задачи анализа, требующие понимания контекста и структуры документа.
Будущее Document AI: за пределами текущих ограничений
Система DeepRead знаменует собой существенный прорыв в разработке интеллектуальных систем обработки документов, способных не просто извлекать данные, но и действительно понимать и логически анализировать сложную информацию. В отличие от традиционных подходов, которые часто фокусируются на структурном анализе и извлечении ключевых слов, DeepRead стремится к семантическому пониманию текста, позволяя системам делать выводы, выявлять взаимосвязи и отвечать на вопросы, требующие глубокого осмысления представленной информации. Это достигается за счет использования передовых моделей глубокого обучения, способных улавливать нюансы языка и контекста, что открывает новые возможности для автоматизации сложных задач, связанных с анализом больших объемов текстовых данных, таких как юридические документы, научные статьи или финансовые отчеты.
Современные системы искусственного интеллекта, работающие с документами, часто сталкиваются с проблемой “структурной слепоты”, то есть неспособностью полноценно учитывать организацию и взаимосвязи внутри длинных и структурированных текстов. Преодоление этого ограничения открывает принципиально новые возможности для извлечения знаний. Вместо простого распознавания отдельных фрагментов, системы, способные понимать структуру документа — заголовки, абзацы, списки, таблицы — могут более эффективно выявлять ключевую информацию, устанавливать логические связи и делать обоснованные выводы. Это позволяет не просто находить ответы на конкретные вопросы, но и анализировать большие объемы данных, выявлять тенденции и генерировать новые знания, максимально раскрывая потенциал содержащейся в документах информации.
Дальнейшие исследования в области Document AI направлены на повышение устойчивости и масштабируемости разработанных методов. Это позволит системам эффективно обрабатывать еще более сложные и объемные документы, содержащие разнообразную и неоднозначную информацию. Особое внимание уделяется способности систем адаптироваться к различным форматам документов, шумам и ошибкам, сохраняя при этом высокую точность и надежность извлечения знаний. Развитие этих технологий откроет новые возможности для решения сложных задач, требующих глубокого понимания и анализа больших объемов текстовой информации, например, в области юридического анализа, медицинской диагностики и научных исследований.
Развитие систем искусственного интеллекта, способных понимать и анализировать сложные документы, открывает новую эру в доступе к информации. Вместо простого поиска по ключевым словам, эти технологии позволяют извлекать глубокие знания и устанавливать взаимосвязи между различными фрагментами текста, значительно повышая надежность и точность получаемых результатов. Это приведет к трансформации способов взаимодействия с информацией: от автоматизированного анализа юридических документов и научных статей до создания интеллектуальных помощников, способных отвечать на сложные вопросы и предлагать новые идеи. В конечном итоге, подобный прогресс позволит людям эффективнее обрабатывать огромные объемы данных, принимать обоснованные решения и расширять границы познания.
Работа демонстрирует, что даже самые элегантные архитектуры, такие как Agentic RAG, рано или поздно сталкиваются с необходимостью учитывать структуру данных. DeepRead пытается навести порядок в хаосе больших документов, используя координатную навигацию — подход, который выглядит разумно, пока не встретит реальный мир, где документы часто не соответствуют ни одному шаблону. Впрочем, сама идея иерархического обхода и структурирования информации не нова. Как заметил Анри Пуанкаре: «Наука не состоит из ряда истин, открытых одна за другой, она есть система, более или менее согласованная, более или менее полная». В данном случае, система DeepRead стремится к согласованности в понимании структуры документа, но её полнота, как и у любой системы, будет проверена лишь временем и объёмом данных, с которыми она столкнётся.
Что дальше?
Представленная работа, безусловно, демонстрирует возможности структурированного подхода к извлечению информации из длинных документов. Однако, следует помнить: каждая элегантная навигационная система рано или поздно столкнётся с документом, намеренно или случайно нарушающим все правила. Архитектура, даже та, что учитывает структуру, — это компромисс, переживший деплой, а не абсолютная истина. Вопрос не в том, насколько эффективно можно «просканировать» документ, а в том, как быстро система научится игнорировать бессмысленные артефакты, которые всегда найдутся.
Следующим этапом видится отказ от иллюзии полного понимания структуры. Вместо того, чтобы строить иерархии, можно исследовать методы, позволяющие агенту «чувствовать» релевантность фрагментов текста, даже если они разбросаны по документу хаотично. Оптимизация под конкретный формат — занятие неблагодарное, ведь всё, что оптимизировано, рано или поздно оптимизируют обратно. Истинный прогресс лежит в способности адаптироваться к неструктурированному хаосу.
В конечном итоге, задача не в создании идеального агента для поиска информации, а в разработке системы, способной самостоятельно определять границы своей компетенции. Мы не рефакторим код — мы реанимируем надежду на то, что машина сможет честно признать свое незнание. И это, пожалуй, самое сложное.
Оригинал статьи: https://arxiv.org/pdf/2602.05014.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Самообучающиеся агенты: новый подход к автономным системам
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- В поисках оптимального дерева: новые горизонты GPU-вычислений
- Наука определений: Автоматическое извлечение знаний из научных текстов
- Графы и действия: новый подход к планированию для роботов
- Bibby AI: Новый помощник для исследователей в LaTeX
- Нейросети: баланс скорости и надёжности
- Поиск знаний: Студенты выбирают между классикой и искусственным интеллектом
- Многокритериальная оптимизация: взгляд на народные методы
2026-02-08 12:03