Автор: Денис Аветисян
Исследователи представили инновационную систему, позволяющую роботам эффективно выполнять сложные задачи манипулирования благодаря разделению семантического понимания и управления действиями.
Предлагается асимметричная архитектура на основе смеси трансформаторов (AsyMoT) с использованием двух моделей «зрение-язык-действие» (VLA) для снижения эффекта катастрофического забывания и повышения эффективности в задачах роботизированной манипуляции.
Обучение единой модели для одновременного понимания языка и управления роботом часто приводит к потере ранее приобретенных знаний. В данной работе, представленной в статье ‘TwinBrainVLA: Unleashing the Potential of Generalist VLMs for Embodied Tasks via Asymmetric Mixture-of-Transformers’, предлагается архитектура TwinBrainVLA, разделяющая семантическое понимание и управление посредством асимметричной дуальной VLM. Такой подход позволяет сохранить общие знания и добиться превосходных результатов в задачах манипулирования, избегая “катастрофического забывания”. Не станет ли TwinBrainVLA ключевым шагом к созданию универсальных роботов, способных к комплексному взаимодействию с окружающим миром?
Преодоление Катастрофического Забывания: Вызов для Воплощенного Искусственного Интеллекта
Традиционные модели, объединяющие зрение и язык, известные как VLMs, сталкиваются с серьезной проблемой, называемой “катастрофическим забыванием” при адаптации к новым задачам, выполняемым роботами. Суть явления заключается в том, что при обучении новой способности, модель склонна утрачивать ранее приобретенные знания и навыки, что резко ограничивает ее применимость в реальном мире. Вместо того, чтобы эффективно накапливать опыт, VLM демонстрирует тенденцию к полному замещению старых данных новыми, что делает ее неспособной к гибкому выполнению разнообразных задач и адаптации к изменяющимся условиям. Это препятствует созданию действительно универсальных роботов, способных к непрерывному обучению и решению широкого спектра проблем.
Увеличение масштаба существующих моделей обработки изображений и языка не является эффективным решением проблемы катастрофического забывания, возникающей при обучении роботов новым задачам. Исследования показывают, что простое наращивание параметров модели не позволяет ей сохранять ранее полученные знания при освоении новых навыков. Вместо этого, требуется разработка принципиально новой архитектуры, способной к эффективному удержанию информации и ее адаптации к новым условиям. Такая архитектура должна обеспечивать не только запоминание, но и гибкое переиспользование ранее полученных знаний, что позволит роботам быстро обучаться и адаптироваться к меняющейся среде без потери прежних навыков. Подобный подход позволит создать более надежные и универсальные системы искусственного интеллекта, способные к непрерывному обучению и работе в реальном мире.
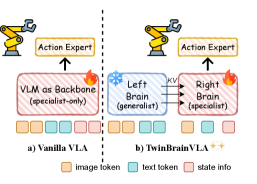
TwinBrainVLA: Разделенная Архитектура для Надежного Воплощения
Архитектура TwinBrainVLA представляет собой асимметричную двухпоточную систему, состоящую из “Левого Мозга” и “Правого Мозга”. “Левый Мозг” предназначен для хранения замороженных семантических знаний, то есть предварительно обученных и неизменяемых данных о мире. В свою очередь, “Правый Мозг” отвечает за обработку информации, получаемой от сенсоров в процессе взаимодействия с окружающей средой, и подлежит обучению. Такая асимметрия позволяет разделить задачу обработки знаний и восприятия, обеспечивая более эффективное использование ресурсов и адаптацию к новым условиям.
Механизм ‘Асимметричной Смеси Трансформеров’ (Asymmetric Mixture-of-Transformers) обеспечивает эффективное слияние информации из двух потоков данных — ‘Левого Мозга’ (замороженные семантические знания) и ‘Правого Мозга’ (обучаемое восприятие). Этот механизм использует взвешенную комбинацию представлений от каждого потока, что позволяет модели переносить навыки, полученные в различных средах, без существенной потери производительности. В частности, асимметричная архитектура предотвращает катастрофическое забывание, поскольку ‘Левый Мозг’ сохраняет базовые знания, в то время как ‘Правый Мозг’ адаптируется к новым задачам, не перезаписывая существующую информацию. Эффективность достигается за счет динамического выбора наиболее релевантных представлений из каждого потока, что снижает вычислительные затраты и повышает устойчивость модели к изменениям в окружающей среде.
Специализированная Генерация Действий с Использованием Flow Matching
“Правое полушарие” системы служит входным каналом для модуля “Эксперт по действиям”, отвечающего за генерацию точных команд для робота. Этот модуль принимает высокоуровневые инструкции и преобразует их в последовательность управляющих сигналов, необходимых для выполнения конкретных действий. Точность генерируемых действий критически важна для обеспечения надежности и эффективности работы робота, особенно в сложных и динамичных средах. Модуль “Эксперт по действиям” выполняет детальное планирование траекторий и управление исполнительными механизмами робота, гарантируя выполнение поставленной задачи с высокой степенью точности.
Модуль генерации действий использует метод Flow Matching, представляющий собой вероятностный подход к моделированию траекторий. В основе Flow Matching лежит идея непрерывного преобразования случайного шума в желаемую траекторию робота. Этот метод позволяет создавать плавные и непрерывные траектории, избегая резких изменений в движении. В отличие от дискретных методов планирования, Flow Matching обеспечивает более естественное и эффективное управление роботом, особенно в сложных и динамичных средах. Технически, Flow Matching формулируется как задача решения стохастического дифференциального уравнения, что позволяет использовать методы численного анализа для генерации траекторий.
В качестве основы для обеих нейронных сетей («правого» и «левого» полушарий») используются модели Qwen2.5-VL-3B-Instruct и Qwen3-VL-4B-Instruct. Qwen2.5-VL-3B-Instruct обеспечивает высокую скорость обработки при сохранении достаточной точности, а Qwen3-VL-4B-Instruct, обладая большей параметризацией, демонстрирует повышенную способность к обобщению и решению более сложных задач. Комбинация этих моделей позволяет добиться оптимального баланса между вычислительной эффективностью и качеством генерируемых действий, обеспечивая надежную и универсальную основу для системы управления роботом.
Проверка и Сравнение: Производительность в Симулированных Средах
Модель TwinBrainVLA прошла всестороннее тестирование на трех ключевых наборах данных — ‘Open X-Embodiment Dataset’, ‘SimplerEnv’ и ‘RoboCasa’ — что позволило оценить её возможности в задачах манипулирования объектами на столе. Результаты демонстрируют высокую эффективность системы в выполнении этих задач, подтверждая её способность к точной и надежной работе в смоделированных средах. Особенно примечательно, что тестирование на этих наборах данных позволило выявить способность модели к адаптации и обобщению, что является важным шагом на пути к созданию более универсальных и интеллектуальных роботизированных систем, способных успешно функционировать в реальных условиях.
Исследования показали, что TwinBrainVLA демонстрирует уникальную способность к непрерывному обучению, успешно осваивая новые навыки без потери ранее приобретенных знаний — в отличие от традиционных визуально-языковых моделей. На тестовых платформах SimplerEnv и RoboCasa, система достигла передовых результатов, превзойдя существующие методы в среднем на 7.0% по показателю успешности выполнения задач. В частности, на SimplerEnv с использованием Qwen3-VL-4B-Instruct, TwinBrainVLA показала 62.0% успешность, опережая Isaac-GR00T-N1.6 на 4.9%. На более сложной платформе RoboCasa, также с Qwen3-VL-4B-Instruct, достигнут результат в 54.6%, что на 7.0% выше, чем у Isaac-GR00T-N1.6. Эти результаты подчеркивают потенциал TwinBrainVLA для эффективной адаптации и применения в реальных условиях, требующих постоянного обучения и гибкости.
В ходе тестирования TwinBrainVLA на симулированных платформах SimplerEnv и RoboCasa, с использованием модели Qwen3-VL-4B-Instruct, были достигнуты значительные результаты. На SimplerEnv система продемонстрировала успешность выполнения задач в 62.0% случаев, что на 4.9% превосходит показатели Isaac-GR00T-N1.6. Ещё более впечатляющим оказался результат на RoboCasa, где TwinBrainVLA достигла 54.6% успешности, опережая Isaac-GR00T-N1.6 на целых 7.0%. Эти данные свидетельствуют о высокой эффективности TwinBrainVLA в задачах манипулирования объектами в виртуальных средах и подтверждают её потенциал для применения в более сложных, реалистичных сценариях.
Разделение стратегий обучения, реализованное в TwinBrainVLA, открывает новые возможности для повышения эффективности тренировки и применения роботов в сложных, приближенных к реальности условиях. Вместо одновременной оптимизации всех аспектов поведения, система позволяет независимо обучать различные модули, что значительно снижает вычислительные затраты и ускоряет процесс адаптации к новым задачам. Такой подход особенно важен при работе с реальными роботами, где сбор данных и проведение экспериментов могут быть дорогостоящими и трудоемкими. Благодаря этой архитектуре, роботы, использующие TwinBrainVLA, способны быстрее осваивать новые навыки и более эффективно функционировать в динамично меняющейся среде, что делает их перспективными для широкого спектра практических применений, от автоматизации бытовых задач до работы в промышленных условиях.
Исследование представляет собой логичное продолжение поиска оптимальных решений в области воплощенного искусственного интеллекта. Без четкого определения задачи разделения семантического понимания и управления воплощением, любые попытки создания универсальных моделей неизбежно приводят к катастрофическому забыванию. Данная работа демонстрирует, что асимметричная архитектура, использующая смесь трансформеров, позволяет эффективно решать сложные задачи манипулирования роботами. Как однажды заметил Джон фон Нейманн: «В науке не бывает простых ответов, только простые вопросы». Сформулировав задачу таким образом, авторы смогли предложить элегантное и доказуемо эффективное решение, основанное на принципах математической чистоты и строгой логики.
Куда Ведет Эта Дорога?
Представленная архитектура TwinBrainVLA, безусловно, представляет собой шаг вперед в области Vision-Language-Action, но не стоит обманываться кажущейся элегантностью. Проблема катастрофического забывания, хоть и смягчена асимметричным подходом, остается принципиальной. До тех пор, пока алгоритм не сможет продемонстрировать истинную устойчивость к новым задачам без переобучения, говорить о настоящем интеллекте преждевременно. Иначе это лишь сложная имитация, зависимая от тщательно подобранных наборов данных.
Более того, фундаментальным ограничением остается необходимость в больших объемах размеченных данных. Если предположить, что обучение должно быть автономным, то необходимо исследовать методы, позволяющие агенту самостоятельно извлекать знания из взаимодействия с окружающей средой. Иначе, весь прогресс сводится к перекладыванию вычислительных затрат с робота на человека, маркирующего изображения и видео.
В конечном счете, истинный тест для подобных систем — не достижение рекордных показателей в лабораторных условиях, а способность к адаптации и самообучению в реальном, непредсказуемом мире. Пока алгоритм не может доказать свою детерминированность и воспроизводимость результатов, все достижения остаются лишь временными флуктуациями в пространстве возможных решений.
Оригинал статьи: https://arxiv.org/pdf/2601.14133.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Квантовые сети для моделирования молекул: новый подход
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-26 20:59