Автор: Денис Аветисян
Новое исследование формализует понятие ‘коллапса патчей’ в изображениях, демонстрируя, как наблюдение одних фрагментов уменьшает неопределенность в других.
Работа посвящена анализу и использованию порядка ‘коллапса патчей’ для улучшения задач генерации и классификации изображений с помощью Vision Transformers и Collapsed Mask Autoencoders.
Неопределённость в восприятии изображения часто рассматривается как равномерно распределённая, однако отдельные фрагменты изображения могут существенно влиять на интерпретацию остальных. В работе под названием ‘The Collapse of Patches’ предложен новый взгляд на эту проблему, формализующий явление “схлопывания фрагментов”, когда наблюдение одних участков изображения снижает неопределённость в отношении других, аналогично коллапсу волновой функции в квантовой механике. Авторы демонстрируют, что выявление оптимальной последовательности “схлопывания” фрагментов позволяет повысить эффективность различных методов моделирования изображений, от авторегрессивной генерации до классификации с использованием Vision Transformers. Не откроет ли это новые возможности для создания более эффективных и экономичных систем компьютерного зрения?
Преодолевая Границы: Ограничения Традиционной Генерации Изображений
Существующие авторегрессионные генераторы изображений, несмотря на свою эффективность в создании визуального контента, сталкиваются с существенными вычислительными сложностями, особенно при масштабировании для получения изображений высокого разрешения. Поскольку эти модели последовательно обрабатывают данные, генерируя каждый пиксель на основе предыдущих, сложность вычислений растет экспоненциально с увеличением размера изображения. Это означает, что для генерации детализированных и реалистичных изображений требуется значительное количество вычислительных ресурсов и времени, что ограничивает их практическое применение и возможности дальнейшего развития. Проблема усугубляется необходимостью хранения и обработки огромного объема промежуточных данных, что приводит к высоким требованиям к памяти и пропускной способности системы.
Существующие методы генерации изображений, основанные на авторегрессии, зачастую сталкиваются с ограничениями, обусловленными последовательной обработкой данных. Такой подход, когда каждый новый пиксель генерируется на основе предыдущих, препятствует эффективной параллелизации вычислений. В результате, даже при использовании мощных вычислительных ресурсов, генерация изображений высокого разрешения становится чрезвычайно затратной по времени и требует значительных ресурсов памяти. Это фундаментальное ограничение сужает возможности по созданию сложных и детализированных изображений, а также замедляет процесс обучения моделей, ограничивая их генеративный потенциал и масштабируемость.
Реалистичная и связная генерация изображений требует от моделей способности улавливать зависимости между удалёнными частями изображения. Проблема заключается в том, что традиционные методы часто испытывают трудности с установлением связей между объектами, находящимися далеко друг от друга в кадре. Например, для создания последовательной сцены, где объект в одном углу влияет на освещение или тени в другом, необходимо понимать эти глобальные взаимосвязи. Неспособность уловить эти долгосрочные зависимости приводит к генерации изображений с несогласованностями, артефактами или нереалистичными деталями, поскольку локальные операции над пикселями не учитывают контекст всего изображения. Успешное решение этой задачи критически важно для создания высококачественных, визуально правдоподобных изображений, где каждый элемент гармонично взаимодействует с остальными.

Маскированное Моделирование: Новый Фундамент Визуального Представления
Маскированное моделирование изображений (MIM) представляет собой подход самообучения, при котором модель обучается восстанавливать скрытые участки входного изображения. В процессе обучения, часть пикселей изображения случайным образом маскируется, и модель предсказывает исходные значения этих замаскированных пикселей на основе видимых частей изображения. Этот процесс вынуждает модель изучать контекстные зависимости и внутреннюю структуру изображения, что приводит к формированию надежного представления визуальной информации без использования размеченных данных. Эффективность MIM заключается в способности модели извлекать значимые признаки из неполной информации, что позволяет ей понимать взаимосвязи между различными частями изображения и формировать обобщенные представления об объектах и сценах.
Методы маскированного моделирования изображений, такие как MAE (Masked Autoencoders), SimMIM и CAPI (Consistent Pre-training with Iterative Masking), демонстрируют высокую эффективность в обучении надежным и экономичным представлениям изображений. MAE использует высокую долю маскирования, восстанавливая лишь небольшую часть исходного изображения, что способствует изучению высокоуровневых признаков. SimMIM упрощает процесс, избегая декодера и напрямую предсказывая признаки маскированных участков. CAPI применяет итеративное маскирование для последовательного улучшения качества представления. Результаты экспериментов показывают, что эти подходы превосходят другие методы самообучения на различных задачах компьютерного зрения, включая классификацию, обнаружение объектов и сегментацию изображений, при сравнимых или меньших вычислительных затратах.
Подходы, основанные на маскировании изображений (MIM), демонстрируют высокую эффективность в захвате контекстной информации, что позволяет успешно реконструировать значительные фрагменты исходного изображения, даже при высокой степени маскирования. Алгоритмы, такие как MAE и SimMIM, используют принципы самообучения, где модель обучается предсказывать недостающие пиксели на основе окружающего контекста. Успешная реконструкция при значительном уровне маскирования, достигаемая этими методами, свидетельствует о способности модели эффективно моделировать взаимосвязи между различными частями изображения и понимать общую структуру визуальных данных. Это позволяет создавать надежные и эффективные представления изображений, пригодные для решения различных задач компьютерного зрения.
Коллапсирующие Автокодировщики: Раскрытие Зависимостей Между Фрагментами
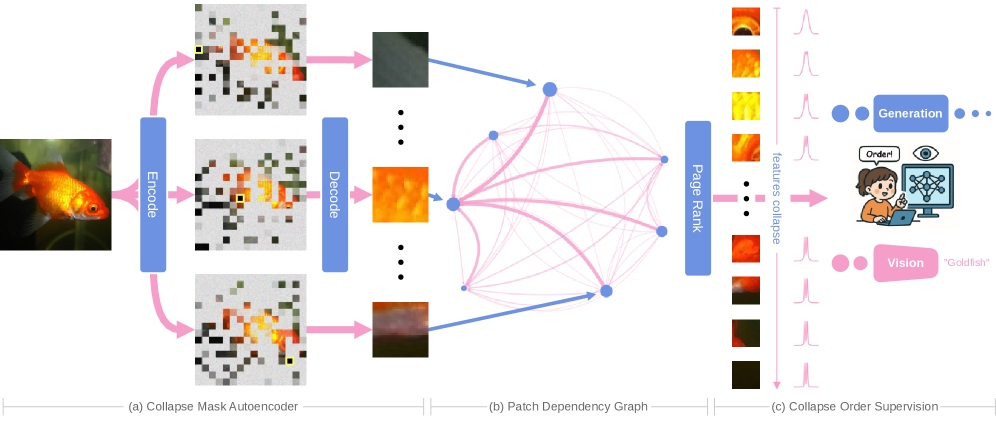
Коллапсирующие Маскированные Автокодировщики (Collapse Masked Autoencoders) представляют собой новый подход к методу MIM (Masked Image Modeling), который в отличие от традиционных методов, явно моделирует зависимости между фрагментами изображения (patch dependencies). Вместо последовательного восстановления замаскированных фрагментов, модель определяет оптимальный “порядок коллапса” (collapse order) для реконструкции, что позволяет эффективно использовать взаимосвязи между ними. Это достигается путем анализа и определения приоритетов восстановления фрагментов на основе их взаимовлияния, что, в свою очередь, повышает эффективность и качество реконструкции изображения.
Автокодировщики Collapse Masked Autoencoders (CMAE) оптимизируют процесс реконструкции изображений, используя методы, заимствованные из различных областей. Приоритезация реконструкции отдельных фрагментов изображения осуществляется на основе алгоритма PageRank, позволяющего определить наиболее значимые области для восстановления. Влияние оказали также концепции, применяемые в алгоритме Wave Function Collapse, который эффективно уменьшает неопределенность при решении задач с ограничениями, и расширение ряда Неймана, позволяющее приближенно вычислять обратные матрицы и, как следствие, оптимизировать процесс реконструкции. Такой подход позволяет CMAE эффективно фокусироваться на наиболее важных частях изображения, что приводит к более быстрой и качественной реконструкции.
Интеграция вариационных автоэнкодеров (VAE) и вращающегося позиционного кодирования (Rotary Position Embedding) в архитектуру Collapse Masked Autoencoders позволяет значительно улучшить качество полученных представлений. В ходе экспериментов было зафиксировано снижение показателя Frèchet Inception Distance (FID) на 4% по сравнению с оригинальной моделью MAR. Данное улучшение FID свидетельствует о более высокой реалистичности и детализации генерируемых изображений, что подтверждает эффективность предложенного подхода к моделированию зависимостей между патчами и повышению качества реконструкции.
За Пределами Реконструкции: К Эффективной Генерации Изображений
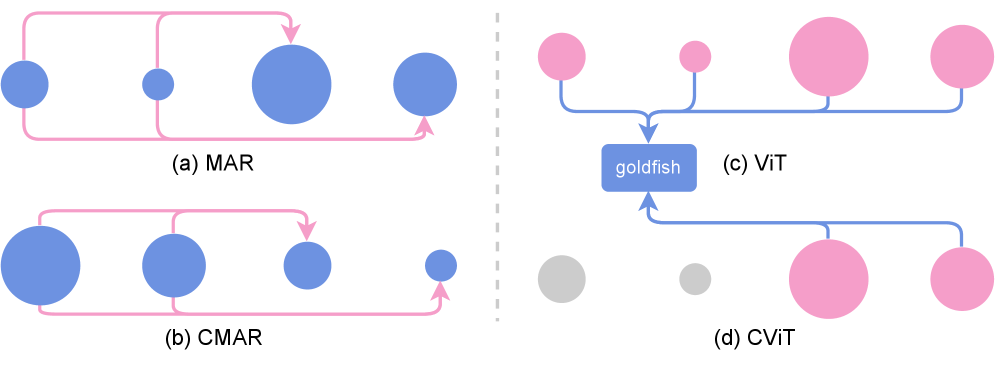
Принципы, лежащие в основе коллапсирующих маскированных автокодировщиков, выходят далеко за рамки простого восстановления изображения, открывая возможности для высококачественной генерации изображений с повышенной эффективностью и масштабируемостью. Данный подход позволяет моделям глубоко понимать структуру и взаимосвязи внутри изображений, что, в свою очередь, обеспечивает создание когерентных и реалистичных визуальных данных при значительно меньших вычислительных затратах. В ходе исследований продемонстрировано, что сохранение высокой точности классификации достигается при обработке лишь 22% фрагментов изображения, что приводит к впечатляющему снижению вычислительной сложности на 95.16%. Это представляет собой значительный шаг вперед в области генерации изображений, указывая на перспективы создания более устойчивых и доступных технологий в данной сфере.
Модели, основанные на принципах маскированных автоэнкодеров, способны генерировать связные и реалистичные изображения благодаря глубокому пониманию внутренней структуры и взаимосвязей в данных. Вместо простого восстановления исходного изображения, они учатся моделировать базовые принципы, определяющие визуальный контент. Это позволяет создавать новые изображения, которые не только правдоподобны, но и согласованы с общими закономерностями, присущими изображениям данного типа. Такой подход существенно снижает потребность в вычислительных ресурсах, поскольку модель не обязана обрабатывать всю информацию целиком, а может фокусироваться на ключевых элементах и зависимостях, что делает процесс генерации изображений более эффективным и доступным.
Предложенный подход знаменует собой значительный прогресс в области генерации изображений, открывая путь к более устойчивым и доступным технологиям. Исследования показали, что сохранение высокой точности классификации (top-1) достигается при обработке лишь 22% фрагментов изображения, что свидетельствует о значительном повышении эффективности. В частности, реализованная стратегия обработки фрагментов позволила снизить вычислительные затраты на 95.16%, что делает генерацию изображений более экономичной и применимой в условиях ограниченных ресурсов. Такой подход не только улучшает производительность существующих моделей, но и создает основу для разработки новых, более масштабируемых и экологичных систем генерации изображений.
Исследование демонстрирует, что визуальное восприятие и, следовательно, генерация изображений, подвержены принципам детерминированности, подобно математическим системам. В частности, концепция ‘patch collapse’, описывающая взаимосвязь между частями изображения и уменьшение неопределенности при наблюдении определенных участков, подтверждает эту идею. Ян Лекун однажды заметил: «Машинное обучение — это прежде всего математика». Этот принцип находит отражение в работе, где авторы формализуют взаимосвязи в изображениях, используя идеи, схожие с алгоритмом PageRank, для упорядочивания патчей и повышения эффективности генеративных моделей. Очевидно, что строгость математического подхода является ключевым фактором в разработке надежных систем искусственного интеллекта.
Куда Ведет Коллапс?
Представленное исследование, формализуя понятие «коллапса патчей», отделяет эвристику от математической необходимости. Утверждение о том, что наблюдение за одним участком изображения уменьшает неопределенность в других, кажется почти тривиальным, но, как показывает работа, его игнорирование приводит к ощутимым потерям в производительности. Однако, не стоит преувеличивать триумф. Остается нерешенным вопрос о степени универсальности этого принципа. Применимо ли это к данным, отличным от изображений? Существуют ли оптимальные стратегии для вычисления порядка коллапса, отличные от предложенных, или же PageRank действительно является достаточно точным инструментом?
Более глубокий вопрос касается самой природы неопределенности в контексте генеративных моделей. Уменьшение неопределенности — это лишь приближение к истине, а не ее достижение. Существующие методы, даже те, что учитывают коллапс патчей, остаются подвержены генерации артефактов и неспособны полностью воспроизвести сложность реальных изображений. Поиск алгоритмов, способных эффективно работать с внутренней противоречивостью данных, представляется более перспективным направлением, чем простое уменьшение энтропии.
В конечном счете, истинная элегантность заключается не в достижении высокой точности на узком наборе тестов, а в создании доказуемо корректных алгоритмов. Работа по формализации коллапса патчей — шаг в этом направлении, но предстоит еще долгий путь к созданию действительно интеллектуальных систем обработки изображений.
Оригинал статьи: https://arxiv.org/pdf/2511.22281.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
2025-12-01 20:10