Автор: Денис Аветисян
Исследователи предлагают инновационный подход к обработке аудио, позволяющий моделям непрерывно взаимодействовать со звуком в процессе рассуждений.
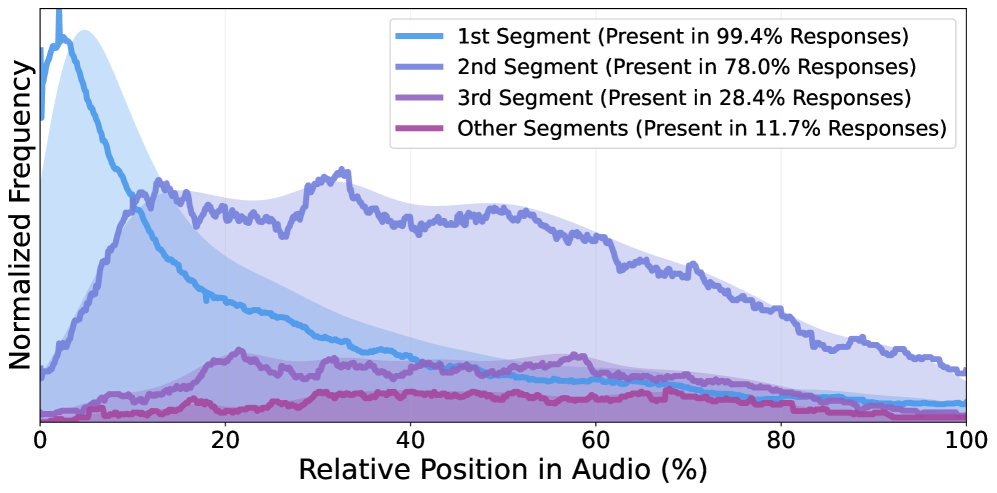
В статье представлена методика аудио-перемежающихся рассуждений для больших языковых моделей, специализирующихся на анализе звука.
Несмотря на прогресс в области больших аудиоязыковых моделей (LALM), их способность к комплексному пониманию аудио остается ограниченной из-за однократной обработки звукового сигнала. В работе ‘Echo: Towards Advanced Audio Comprehension via Audio-Interleaved Reasoning’ предложен новый подход — аудио-перемежающееся рассуждение, вдохновленное когнитивными способностями человека, позволяющее LALM динамически возвращаться к прослушиванию аудио во время анализа. Разработанная модель Echo демонстрирует превосходство в решении задач по пониманию аудио, как общего назначения, так и экспертного уровня, благодаря двухэтапному процессу обучения и структурированному созданию обучающих данных. Не откроет ли это путь к созданию по-настоящему «слышащих» и понимающих систем искусственного интеллекта?
За пределами кодирования: Ограничения традиционного аудио-рассуждения
Существующие большие языковые модели (LLM) зачастую полагаются на преобразование аудио в текст для последующего анализа, что создает узкое место для глубокого понимания. Этот процесс, известный как «аудио-обусловленное текстовое рассуждение», предполагает транскрипцию звука в текстовый формат, после чего модель обрабатывает уже текст. Однако, подобный подход неизбежно приводит к потере нюансов, таких как тон голоса, эмоциональная окраска и другие невербальные сигналы, критически важные для полноценного восприятия информации. По сути, модель лишается прямого доступа к аудиосигналу, что ограничивает ее способность к точному и комплексному анализу звуковой информации и может приводить к неверным интерпретациям.
Применение подхода, основанного на преобразовании аудио в текст для последующего анализа, часто сталкивается с ограничениями в понимании временных взаимосвязей и поддержании внимания к аудиоинформации на протяжении всей её продолжительности. Существующие модели, полагающиеся на данный метод, испытывают трудности с удержанием контекста при анализе сложных звуковых последовательностей, что приводит к потере значимых деталей и неточностям в интерпретации. В частности, модели могут испытывать затруднения с распознаванием изменений в звуковом ландшафте, определением продолжительности событий и установлением причинно-следственных связей между различными звуковыми элементами, что существенно ограничивает их способность к полноценному «аудиальному мышлению». В результате, полноценное понимание аудиоконтента, требующее учета как содержания, так и временной динамики, остается сложной задачей для систем, использующих исключительно текстовое представление звуковой информации.
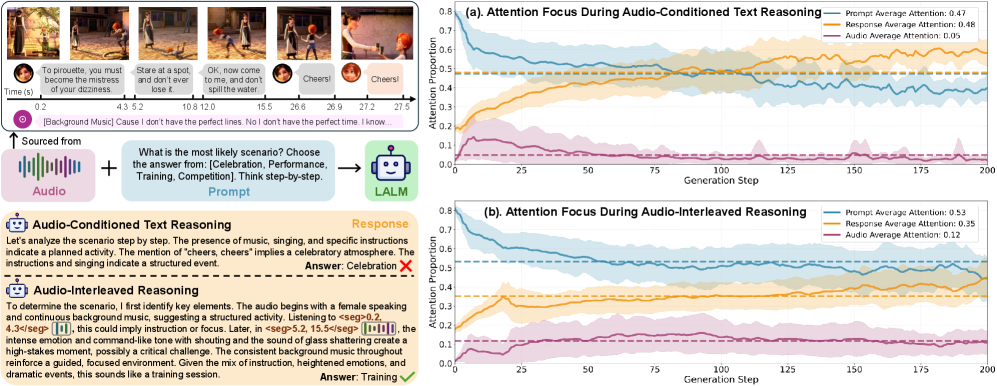
Эхо: Представляем аудио-перемежающееся рассуждение
Мы представляем Echo, большую языковую модель (LLM), использующую метод “аудио-перемежающегося рассуждения”. В отличие от традиционных подходов, где аудио обрабатывается как отдельный этап перед передачей в модель, Echo интегрирует обработку аудио непосредственно в цикл рассуждений. Это означает, что модель динамически обрабатывает аудиосегменты по мере необходимости в процессе выполнения задачи, а не полагается на предварительно вычисленные представления. Такая архитектура позволяет модели постоянно взаимодействовать с аудиоинформацией, что способствует более глубокому и контекстуально-зависимому пониманию.
Архитектура Echo обеспечивает динамическое внимание и анализ аудиосегментов по мере необходимости. В отличие от традиционных подходов, где аудио обрабатывается как единый блок, Echo позволяет модели выборочно фокусироваться на релевантных фрагментах звука в процессе рассуждений. Это достигается за счет механизмов внимания, которые определяют наиболее важные моменты в аудиопотоке для текущей задачи. Такой подход значительно улучшает понимание временных зависимостей в аудио, поскольку модель способна учитывать контекст и изменения звука на протяжении всей последовательности, что критически важно для сложных задач аудиального восприятия и анализа.
Архитектура Echo отличается от традиционных подходов, ограничивающихся однократным кодированием аудиоданных. Вместо этого, модель обеспечивает продолжительное взаимодействие с аудиопотоком, динамически обрабатывая и анализируя релевантные сегменты в процессе логических рассуждений. Это позволяет Echo более эффективно решать сложные задачи, требующие глубокого понимания временных зависимостей в аудио, демонстрируя улучшенные результаты по сравнению с системами, использующими только статичное кодирование входных данных. В частности, такая схема позволяет модели удерживать контекст и выполнять более точный анализ на протяжении всего аудиофрагмента.
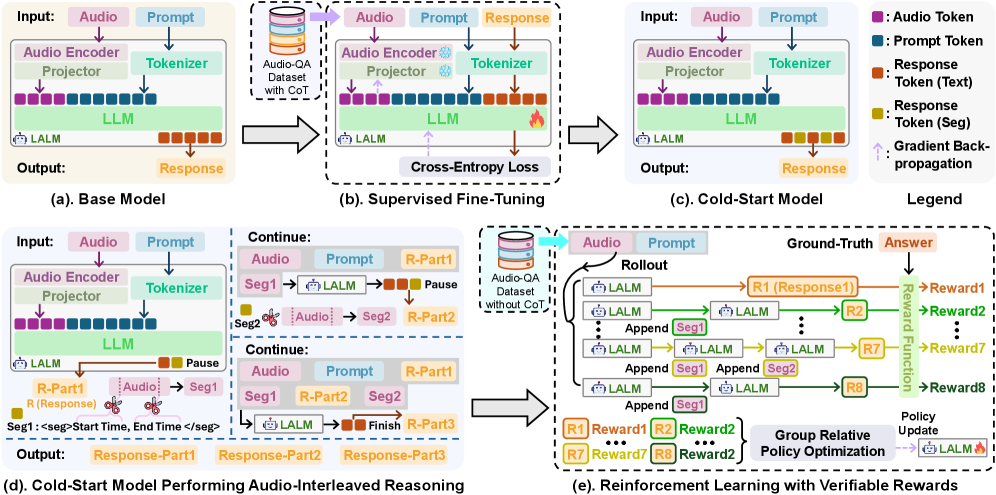
Обучение Эхо: Двухэтапный процесс усовершенствования
Обучение Echo осуществляется посредством двухэтапного процесса: сначала применяется контролируемое обучение (SFT) для локализации релевантных аудиосегментов, что позволяет модели точно определять временные рамки интересующих звуковых событий. На втором этапе используется обучение с подкреплением (RL) для уточнения процесса рассуждений, включающего в себя обработку аудиоинформации, и оптимизации последовательности действий модели при анализе звуковых потоков. Такой подход позволяет добиться более точного и эффективного анализа аудиоданных, чем при использовании одноэтапных методов обучения.
В процессе обучения модель Echo использует временные метаданные, предоставляемые датасетами, такими как AudioGrounding Dataset, для точной привязки к моменту начала и продолжительности звуковых событий. Эти метаданные содержат информацию о временных метках, определяющих, когда конкретное звуковое событие происходит в аудиозаписи, и как долго оно длится. Использование этих данных позволяет модели более эффективно локализовать релевантные аудиофрагменты и синхронизировать рассуждения с временным контекстом звука, что критически важно для задач, требующих понимания последовательности и длительности звуковых событий.
Процесс обучения модели Echo дополняется использованием больших языковых моделей (LLM), в частности DeepSeek-R1, для двух основных задач. Во-первых, LLM используется для синтеза данных, что позволяет расширить обучающую выборку и повысить устойчивость модели к различным условиям. Во-вторых, DeepSeek-R1 применяется для полировки и редактирования текстовых описаний, генерируемых в процессе обучения, обеспечивая их грамматическую корректность и семантическую связность. Это позволяет улучшить качество итоговых результатов и упростить процесс анализа и валидации модели.
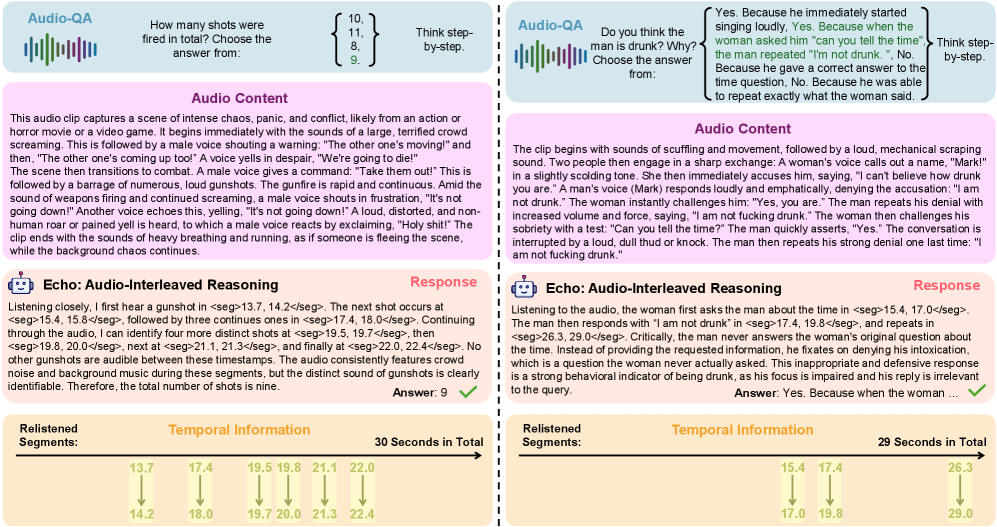
Тестирование и результаты: Превосходство Эхо
Модель Echo демонстрирует передовые результаты на эталонных наборах данных MMAU и MMAR, задавая новые стандарты в области понимания речи. Прохождение тестов на этих наборах, отличающихся уровнем сложности, подтверждает способность Echo эффективно обрабатывать и интерпретировать аудиоинформацию различного характера. Это достижение указывает на значительный прогресс в разработке систем, способных к более глубокому и точному анализу звуковых данных, открывая перспективы для улучшения взаимодействия человека и машины в различных приложениях, от голосовых помощников до систем автоматической транскрипции.
В ходе сравнительного анализа производительности, модель Echo продемонстрировала превосходство над ведущими большими языковыми моделями (LLM), такими как GPT-4o и Gemini-2.0-Flash. В частности, на упрощенном наборе данных MMAU-mini, Echo добилась повышения точности на 1.22% по сравнению с альтернативными LLM. Этот результат указывает на значительный прогресс в области мультимодального понимания, подчеркивая способность модели более эффективно обрабатывать и интерпретировать аудиоинформацию в контексте сложных задач. Улучшение точности, хотя и кажется незначительным, имеет существенное значение для приложений, требующих высокой степени надежности и точности, например, в автоматическом распознавании речи и понимании естественного языка.
Несмотря на то, что добавление аудиосегментов в процесс обработки приводит к увеличению задержки примерно на 13%, данный показатель остается стабильным при различной продолжительности аудиоматериалов. Особого внимания заслуживает высокая точность сегментации, достигающая 97.75% (IoU ≥ ρ) для аудиофрагментов длительностью от 11 до 20 секунд. Это демонстрирует, что даже при увеличении времени обработки, система способна с высокой степенью надежности определять границы и содержание аудиоинформации, что критически важно для точного понимания и анализа.
Полученные результаты указывают на то, что непосредственная интеграция обработки аудио в процесс рассуждений позволяет достичь более тонкого и точного понимания. В отличие от моделей, которые обрабатывают аудио и текст последовательно, Echo объединяет эти процессы, что даёт возможность учитывать нюансы звучания и контекст одновременно. Такой подход позволяет модели не просто транскрибировать речь, но и анализировать интонации, эмоции и другие акустические характеристики, которые могут влиять на смысл высказывания. Это, в свою очередь, приводит к более глубокому пониманию и, как следствие, к повышению точности ответов, особенно в сложных сценариях, требующих учета невербальной информации и контекстуальных особенностей.

Внимательный взгляд на современные системы обработки звука неизбежно приводит к осознанию их хрупкости. Авторы данной работы, предлагая подход аудио-перемежающихся рассуждений, стремятся не просто построить модель, но и создать среду, в которой она может адаптироваться к непрерывности звукового потока. Это напоминает о том, что архитектура — это не застывшая структура, а компромисс, застывший во времени. Как точно подметала Грейс Хоппер: «Лучший способ предсказать будущее — это создать его». И в данном случае, создание системы, способной к непрерывному взаимодействию со звуком, — это шаг к более разумному и адаптивному будущему обработки аудиоинформации. Ведь технологии сменяются, зависимости остаются, и именно умение учитывать эту непрерывность — ключ к долговечности любой системы.
Что Дальше?
Представленный подход к построению больших аудио-языковых моделей, основанный на чередующемся рассуждении, лишь обнажает глубинные противоречия в стремлении к «пониманию» звука. Каждый новый цикл взаимодействия с аудиопотоком — это, по сути, отсрочка неизбежного столкновения с хаосом неполноты данных. Улучшение показателей на текущих задачах — это временное облегчение, за которым последует вырождение модели перед более сложными, неструктурированными сигналами. Уверенность в масштабируемости алгоритма подкрепления — иллюзия, за которой скрывается экспоненциальный рост вычислительных затрат.
Вместо погони за «идеальным» пониманием, необходимо признать, что ценность заключается не в абсолютной точности, а в способности модели предсказывать вероятные интерпретации. Будущие исследования неизбежно столкнутся с необходимостью интеграции с системами активного обучения, где модель самостоятельно формирует запрос на получение недостающей информации. Отказ от пассивного восприятия аудио в пользу активного исследования звуковой среды — не просто техническая задача, но и философский сдвиг в парадигме.
В каждом новом слое абстракции, добавляемом к архитектуре, таится страх перед непредсказуемостью. Надежда на создание универсальной модели аудио-понимания — это форма отрицания энтропии. В конечном счете, судьба этой и подобных систем будет определяться не столько архитектурными решениями, сколько способностью адаптироваться к неизбежному рассыпанию звукового мира на фрагменты.
Оригинал статьи: https://arxiv.org/pdf/2602.11909.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Внимание на границе: почему трансформеры нуждаются в «поглотителях»
- Искусственный нос будущего: как квантовая механика и машинное обучение распознают запахи
- Химический синтез под контролем искусственного интеллекта: новые горизонты
- Внимание в сети: Новый подход к ускорению больших языковых моделей
- Физика под контролем: Как «научить» модели понимать мир
- Пространственная Архитектура для Эффективного Ускорения Нейросетей
- Когда большая языковая модель молчит: как избежать галлюцинаций при ответе на вопросы?
- Квантовые Заметки: От Праздничной Оптимизации до Глобального Хаба
- Законы масштабирования нейросетей: трещины в науке о материалах
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
2026-02-15 22:30