Автор: Денис Аветисян
Новое исследование показывает, что основной прогресс в развитии языковых моделей обусловлен не постепенными улучшениями, а фундаментальными изменениями в архитектуре и масштабированием данных.
Основной вклад в развитие языковых моделей вносят переходы к новым архитектурам (например, от LSTM к Transformer) и стратегии масштабирования данных, такие как Chinchilla, а также зависимость этих улучшений от масштаба.
Несмотря на впечатляющий прогресс в области искусственного интеллекта, источники повышения эффективности обучения алгоритмов остаются недостаточно изученными. В работе ‘On the Origin of Algorithmic Progress in AI‘ авторы анализируют факторы, обусловившие 22 000-кратное увеличение эффективности обучения за период с 2012 по 2023 год. Полученные результаты свидетельствуют о том, что основная часть этих улучшений связана не с постепенными усовершенствованиями алгоритмов, а с переходом к новым архитектурам, таким как Transformer, и практиками масштабирования данных, наподобие подхода Chinchilla. Действительно ли существующие оценки прогресса в алгоритмах занижают роль масштаба вычислений и архитектурных инноваций?
В поисках эффективности: за пределами грубой силы масштабирования
Современные языковые модели, особенно основанные на архитектуре Transformer, демонстрируют впечатляющие результаты в различных задачах обработки естественного языка. Однако, эта производительность достигается за счет значительных вычислительных ресурсов. Обучение и развертывание таких моделей требует огромных объемов памяти, энергии и времени обработки. Например, обучение крупнейших моделей может потребовать нескольких недель или даже месяцев на специализированном оборудовании, таком как графические процессоры (GPU) или тензорные процессоры (TPU). Эта вычислительная сложность создает серьезные ограничения для широкого применения этих моделей, особенно в условиях ограниченных ресурсов или при необходимости обработки больших объемов данных в режиме реального времени. Следовательно, поиск путей повышения эффективности языковых моделей является ключевой задачей для дальнейшего развития области.
Исторически, значительные улучшения в производительности языковых моделей достигались за счет последовательного увеличения их размера и объемов обучающих данных — подход, наиболее ярко продемонстрированный законом масштабирования Каплана. Однако, в последнее время наблюдается тенденция к уменьшению эффективности этого метода. Дальнейшее увеличение масштаба моделей и датасетов требует экспоненциально растущих вычислительных ресурсов, при этом прирост в качестве перестает соответствовать затраченным усилиям. Это означает, что простая стратегия «больше — лучше» приближается к своему пределу, и для дальнейшего прогресса необходимо искать альтернативные пути, фокусируясь на более эффективных алгоритмах и архитектурах.
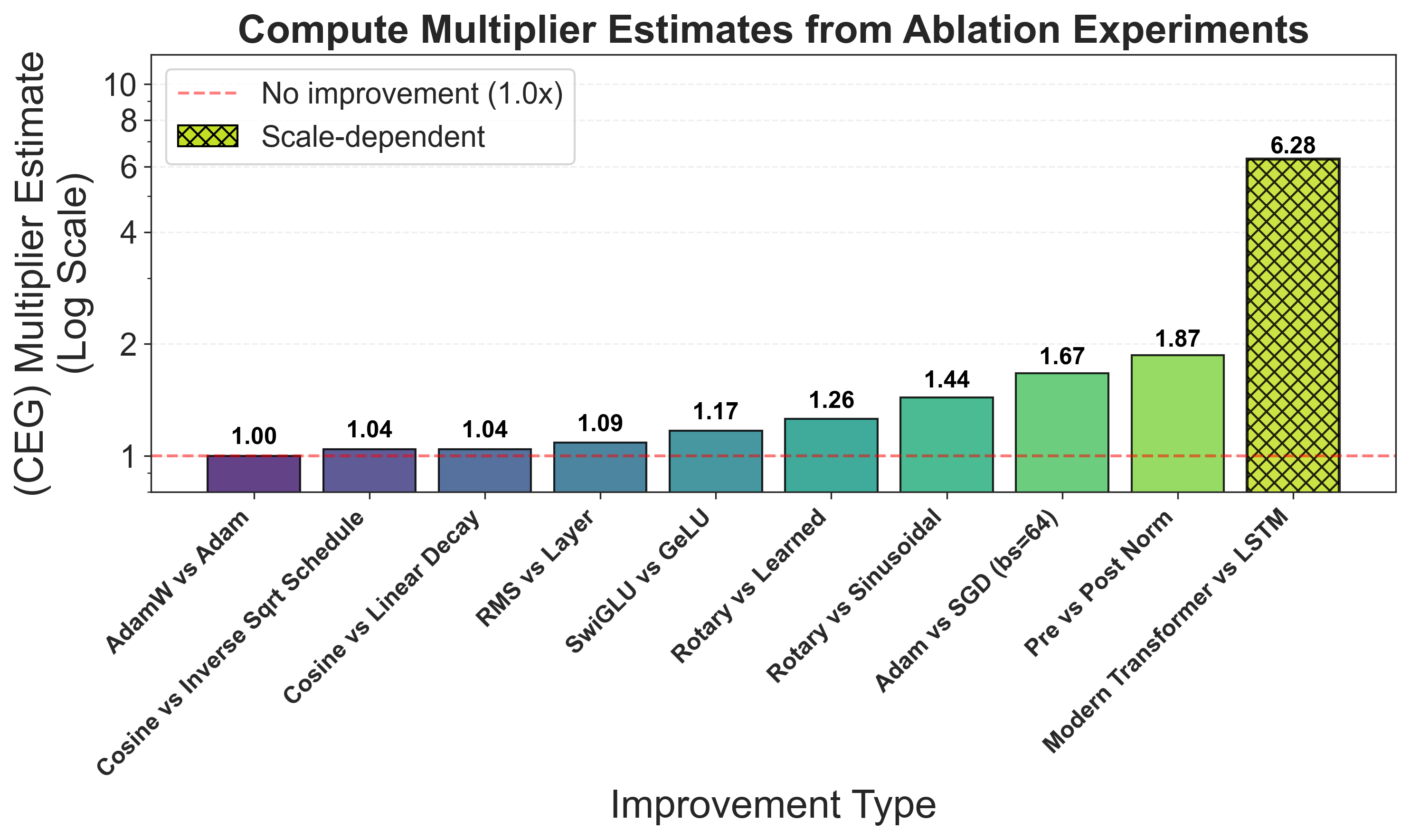
В настоящее время наблюдается тенденция к переходу от простого увеличения вычислительных ресурсов к развитию алгоритмической эффективности в области больших языковых моделей. Исследования показывают, что дальнейшее масштабирование размеров моделей и объемов данных дает всё меньше прироста в производительности. Примечательно, что переход от рекуррентных сетей LSTM к архитектуре Transformer обеспечил 68% от общего прироста эффективности на передовых масштабах. Этот факт демонстрирует, что инновации в архитектуре моделей способны оказать значительно большее влияние на производительность, чем просто увеличение вычислительных мощностей, и открывает новые перспективы для дальнейшего развития в области искусственного интеллекта.
Измеряя алгоритмический прогресс: сила CEG
Вычислительное эквивалентное усиление (CEG) является ключевым показателем для оценки реальной эффективности алгоритмических инноваций в языковых моделях. CEG позволяет сопоставить производительность различных моделей, нормализованную к затратам на вычисления. В отличие от традиционных метрик, таких как точность, CEG учитывает объем вычислительных ресурсов, необходимых для достижения определенного уровня производительности. Это позволяет объективно сравнивать различные архитектуры и алгоритмы, выявляя наиболее эффективные решения и определяя, насколько значительно улучшилась производительность на единицу затраченных вычислительных ресурсов. Таким образом, CEG предоставляет более полную картину прогресса в области языковых моделей, чем просто оценка их способности решать конкретные задачи.
Вычислительная эквивалентная выгода (CEG) позволяет проводить оценку эффективности как современных архитектур, таких как Transformer, так и более ранних, например, LSTM. Применение CEG к обеим архитектурам позволяет количественно оценить прирост производительности, достигнутый благодаря переходу к Transformer. Этот подход предоставляет возможность объективного сравнения различных архитектур и выявления тех, которые обеспечивают наибольший выигрыш в производительности на единицу вычислительных ресурсов. Анализ с использованием CEG подтверждает, что переход от LSTM к Transformer привел к значительному увеличению эффективности.
Метрика Compute Equivalent Gain (CEG) позволяет исследователям проводить объективное сравнение различных подходов к построению языковых моделей и определять приоритетность тех, которые обеспечивают максимальную производительность на единицу вычислительных ресурсов. Переход от архитектуры LSTM к Transformer продемонстрировал значительное повышение эффективности — в 846 раз, что подтверждает существенное влияние данной инновации на область обработки естественного языка. Использование CEG позволяет количественно оценить прогресс и оптимизировать затраты на вычисления при разработке новых моделей, фокусируясь на реальном приросте производительности, а не только на абсолютных показателях.

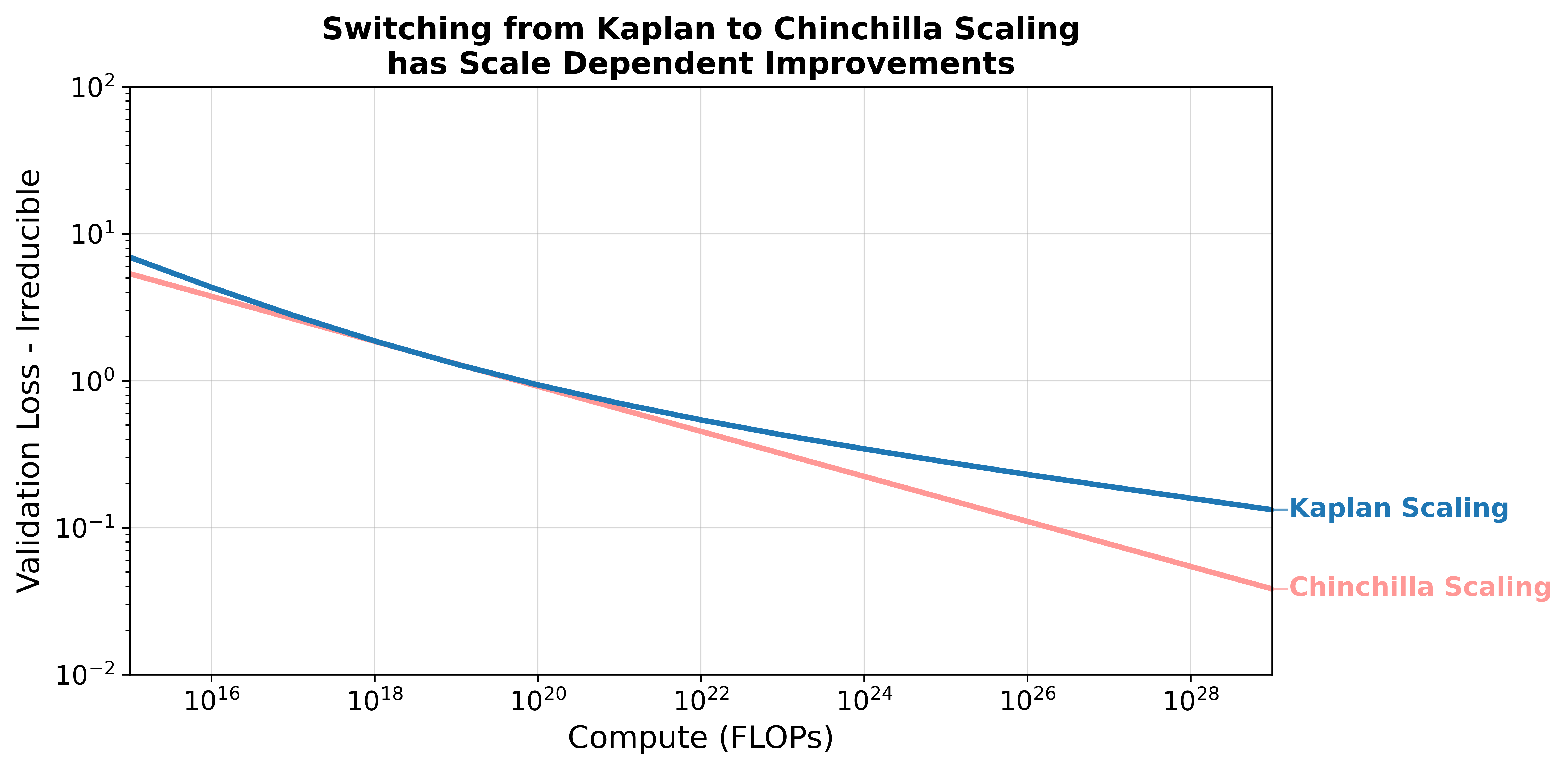
Оптимизация масштаба: от Каплана к Чинчилле
Метод масштабирования Chinchilla представляет собой усовершенствованный подход к масштабированию моделей, в отличие от более ранней модели Kaplan. Kaplan Scaling фокусировался в основном на увеличении размера модели, в то время как Chinchilla оптимизирует использование вычислительных ресурсов за счет баланса между размером модели и размером обучающего набора данных. Этот подход позволяет достичь более высокой производительности при заданном объеме вычислений, избегая избыточного увеличения параметров модели без соответствующего увеличения данных. В результате, Chinchilla демонстрирует повышенную вычислительную эффективность и снижает затраты на обучение, сохраняя или улучшая точность по сравнению с моделями, масштабированными по принципам Kaplan Scaling.
Метод масштабирования Chinchilla признает, что простое увеличение размера модели не всегда является оптимальной стратегией. Традиционный подход, ориентированный на наращивание параметров модели, часто приводит к неэффективному использованию вычислительных ресурсов и может привести к переобучению. Chinchilla подчеркивает критическую важность сопоставления размера модели с размером обучающего набора данных. Исследования показали, что для достижения максимальной производительности необходимо увеличивать размер набора данных пропорционально увеличению числа параметров модели. Например, если количество параметров модели увеличивается в 10 раз, размер набора данных также должен быть увеличен примерно в 10 раз для поддержания оптимального баланса и избежания ситуации, когда модель запоминает данные вместо того, чтобы обобщать их. Этот подход позволяет добиться более высокой эффективности и снизить необратимые потери ($Irreducible\ Loss$).
Оптимизированное масштабирование, реализованное в методологии Chinchilla, напрямую влияет на $Irreducible Loss$ — фундаментальный предел производительности модели — за счет повышения эффективности использования данных и снижения переобучения. Перебалансировка данных в Chinchilla составляет значительную часть наблюдаемого прироста эффективности, и в сочетании со структурными изменениями в архитектуре модели, эти два фактора обеспечивают 91% от всех достигнутых улучшений. Таким образом, повышение размера модели не является единственным путем к улучшению производительности; ключевым фактором является оптимизация соотношения между размером модели и размером обучающей выборки.
Архитектурные решения: построение эффективных Transformer
Архитектура Transformer включает в себя несколько техник для повышения эффективности и стабильности обучения. В частности, нормализация слоев (LayerNorm) и RMSNorm используются для стабилизации градиентов во время тренировки, что позволяет использовать более высокие скорости обучения и снижает вероятность расхождения процесса. LayerNorm нормализует активации в пределах каждого слоя, в то время как RMSNorm, являясь упрощенной версией, фокусируется на нормализации по корню из суммы квадратов активаций, что часто приводит к снижению вычислительных затрат и сохранению эффективности. Обе техники способствуют более быстрому схождению модели и улучшению обобщающей способности, особенно в задачах с большими объемами данных и сложными архитектурами.
Инновации в архитектуре Transformer, такие как активация SwiGLU и выбор между синусоидальными и вращающимися эмбеддингами, направлены на повышение производительности и эффективности использования ресурсов. SwiGLU, заменяя традиционную ReLU активацию, использует функцию сигмоиды и произведения, что позволяет улучшить градиентный поток и стабилизировать обучение. Выбор между синусоидальными и вращающимися эмбеддингами позиций влияет на способность модели учитывать порядок токенов в последовательности. Синусоидальные эмбеддинги являются фиксированными, в то время как вращающиеся эмбеддинги (RoPE) позволяют модели лучше обобщать на последовательности различной длины и более эффективно обрабатывать длинные последовательности, что критично для задач, требующих учета контекста.
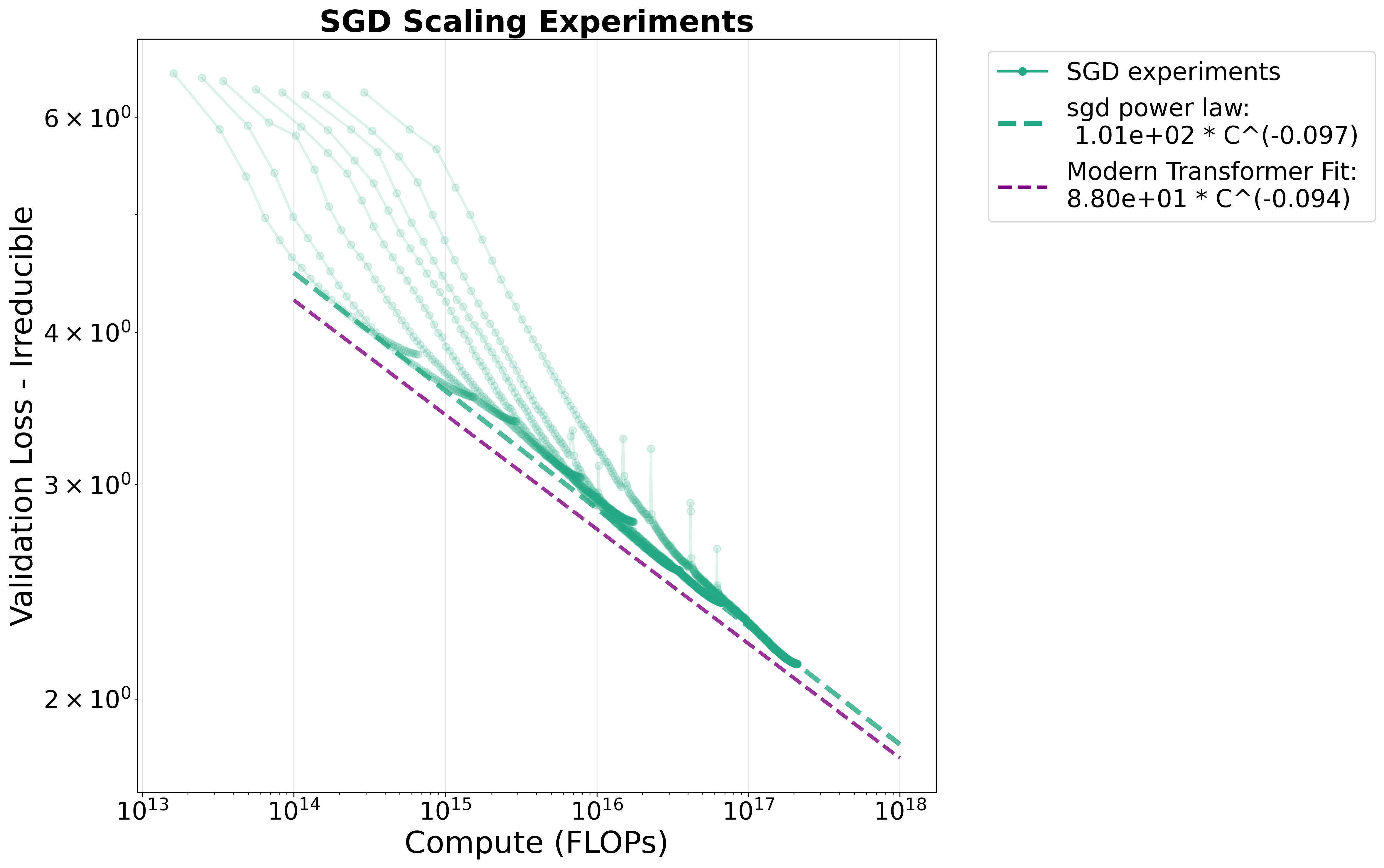
Выбор оптимального алгоритма оптимизации, такого как AdamW или SGD, оказывает существенное влияние на скорость обучения и достижение наилучших результатов при работе с архитектурой Transformer. Исследования показывают, что показатель масштабирования (scaling exponent) для Transformer, обученных с использованием SGD, составляет приблизительно 0.1, что сопоставимо с показателем, наблюдаемым при использовании AdamW. Это указывает на схожую эффективность обоих алгоритмов в контексте обучения больших языковых моделей, где показатель масштабирования отражает зависимость между размером модели и требуемыми вычислительными ресурсами для достижения оптимальной производительности. Оба алгоритма демонстрируют эффективную сходимость при правильной настройке гиперпараметров.
Путь в будущее: передовые вычисления и устойчивый ИИ
Дальнейший прогресс в алгоритмической эффективности, оцениваемый с помощью метрики CEG (Computational Efficiency Gains), является ключевым фактором для раскрытия всего потенциала Frontier Compute. Изучение показывает, что повышение эффективности алгоритмов позволяет добиться значительного увеличения производительности без пропорционального увеличения потребляемой энергии и вычислительных ресурсов. Это особенно важно в контексте Frontier Compute, где модели становятся все более сложными и масштабными. Оптимизация алгоритмов позволяет создавать более мощные и функциональные модели, доступные для широкого круга пользователей, и при этом минимизировать их экологический след. Более того, постоянное стремление к повышению CEG открывает путь к инновациям в области искусственного интеллекта, позволяя решать задачи, которые ранее считались невозможными, и расширяя горизонты применения ИИ в различных сферах деятельности.
Отделение производительности от чистой вычислительной мощности открывает путь к более широкому доступу к передовым языковым моделям и одновременному снижению их негативного воздействия на окружающую среду. Традиционно, улучшение возможностей искусственного интеллекта требовало экспоненциального увеличения вычислительных ресурсов, что делало передовые модели недоступными для многих исследователей и организаций. Однако, фокусируясь на оптимизации алгоритмов и повышении их эффективности, становится возможным достичь сопоставимых или даже превосходящих результатов, используя значительно меньше энергии и оборудования. Это не только снижает финансовые барьеры для участия в развитии ИИ, но и способствует созданию более устойчивой и экологически ответственной технологической экосистемы, позволяя внедрять передовые решения в более широком спектре областей и стимулируя инновации.
Переход к устойчивому искусственному интеллекту открывает возможности для его применения в более широком спектре областей и стимулирует инновации в различных сферах деятельности. Исследования показывают, что подавляющее большинство — 91% — наблюдаемого повышения эффективности достигается за счет масштабно-инвариантных инноваций, то есть усовершенствований, которые сохраняют свою эффективность независимо от размера и сложности модели. Это свидетельствует о критической важности разработки алгоритмов и архитектур, способных к эффективной работе даже при ограниченных ресурсах, что делает передовые технологии искусственного интеллекта более доступными и экологичными, способствуя их внедрению в новые области, от медицины и образования до науки о климате и устойчивого развития.
Исследование закономерностей развития алгоритмов в области искусственного интеллекта выявляет, что значительные прорывы зачастую обусловлены не постепенными улучшениями, а фундаментальными изменениями в архитектуре систем и подходами к масштабированию данных. Этот процесс напоминает эволюцию, где ключевые этапы определяются не количеством мелких доработок, а качественными скачками. Как заметил Анри Пуанкаре: «Математика — это искусство находить закономерности, скрытые в хаосе». В данном исследовании, подобно тому, как математик ищет закономерности, авторы обнаруживают, что прогресс в обучении языковых моделей, таких как Transformer, напрямую зависит от масштабирования данных и архитектурных инноваций, что позволяет сократить необратимые потери и повысить эффективность вычислений. Логирование этих изменений — это хроника жизни системы, позволяющая отслеживать эволюцию алгоритмов во времени.
Куда Ведет Дорога?
Представленная работа демонстрирует, что кажущийся неуклонный прогресс в области языковых моделей — это не плавное течение, а скорее серия скачкообразных переходов, связанных с архитектурными инновациями и, что важнее, с масштабированием данных. Версионирование моделей — это форма памяти, запечатлевшая эти переходы, но и указание на неминуемый предел. Стрела времени всегда указывает на необходимость рефакторинга, и закономерности, проявившиеся в текущих масштабах, не обязательно сохранятся в будущем.
Неразрешенной остается проблема “неизбежных потерь” — фундаментального ограничения, которое, возможно, требует не просто увеличения масштаба, а принципиально новых подходов к представлению знаний. Эффективность вычислений, казавшаяся второстепенной, становится все более критичной, ведь рост вычислительных затрат может обогнать прирост производительности, превращая прогресс в иллюзию.
Следующим этапом, вероятно, станет поиск архитектур, способных к более эффективному обучению на меньших объемах данных, и разработка метрик, способных измерять не только производительность, но и устойчивость моделей к изменениям в данных и задачах. Все системы стареют — вопрос лишь в том, делают ли они это достойно. И время, как среда, в которой существуют эти системы, диктует свои условия.
Оригинал статьи: https://arxiv.org/pdf/2511.21622.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сохраняя геометрию: Квантование для эффективных 3D-моделей
- Квантовый Переход: Пора Заботиться о Криптографии
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Квантовая обработка данных: новый подход к повышению точности моделей
- Квантовые прорывы: Хорошее, плохое и смешное
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Квантовые вычисления: от шифрования армагеддона до диверсантов космических лучей — что дальше?
- Лунный гелий-3: Охлаждение квантового будущего
- Квантовая химия: моделирование сложных молекул на пороге реальности
2025-11-28 18:03