Автор: Денис Аветисян
Исследователи представили инновационную систему, позволяющую значительно улучшить процесс обучения и развития моделей искусственного интеллекта, обеспечивая стабильный прогресс и избегая распространенных проблем.
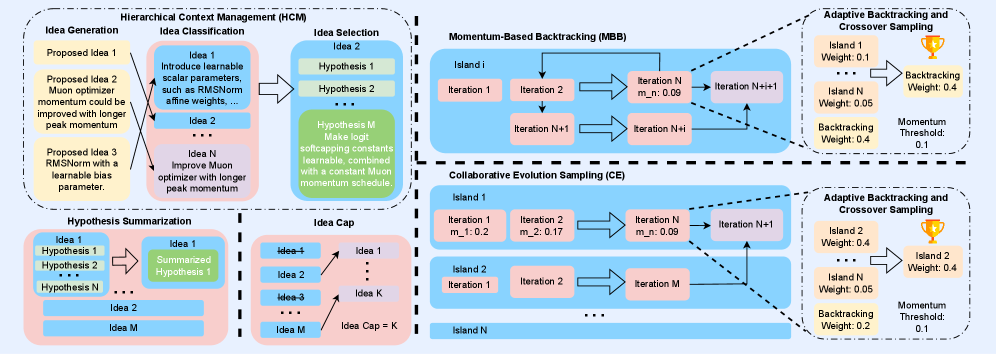
В статье представлена методика PACEvolve, основанная на иерархическом управлении контекстом, адаптивной совместной эволюции и механизме возврата к оптимальным решениям для повышения эффективности LLM-driven эволюционного поиска.
Несмотря на впечатляющие возможности больших языковых моделей (LLM) в качестве инструментов эволюционного поиска, эффективная организация этого процесса остаётся сложной задачей. В данной работе представлена система PACEvolve: Enabling Long-Horizon Progress-Aware Consistent Evolution, предназначенная для решения проблем, связанных с накоплением контекстной информации, застреванием в локальных минимумах и недостаточной кооперацией агентов поиска. Предложенный фреймворк, сочетающий иерархическое управление контекстом, механизм возврата к перспективным решениям и адаптивную стратегию сэмплирования, обеспечивает устойчивое улучшение результатов на различных бенчмарках, включая LLM-SR и KernelBench, и превосходит существующие решения на Modded NanoGPT. Возможно ли с помощью подобных подходов создать самообучающиеся системы, способные к длительной и стабильной эволюции в сложных поисковых пространствах?
Пределы Традиционного Поиска: Эхо Локальных Оптимумов
Традиционные эволюционные алгоритмы, несмотря на свою мощь, часто сталкиваются с трудностями при исследовании сложных, многомерных пространств поиска. Суть проблемы заключается в том, что по мере увеличения числа параметров и ограничений, алгоритм склонен застревать в локальных оптимумах — решениях, которые кажутся наилучшими в узком контексте, но уступают глобальному оптимуму. Этот эффект усиливается в задачах, где функция оценки сложна и имеет множество “ловушек”, заставляя алгоритм преждевременно сходиться к субоптимальным результатам. В результате, даже при значительных вычислительных затратах, поиск действительно эффективного решения может оказаться невозможным, что ограничивает применимость таких алгоритмов в решении реальных, сложных задач.
Появление больших языковых моделей (LLM) открывает перспективные возможности для управления процессами поиска, однако их непосредственное применение сопряжено с рядом трудностей. В частности, возникает проблема “загрязнения контекста”, когда LLM, обученная на обширных данных, начинает генерировать нерелевантные или вводящие в заблуждение предложения, искажая траекторию поиска. Кроме того, наивное использование LLM может привести к неэффективному исследованию пространства решений, поскольку модель склонна эксплуатировать наиболее очевидные направления, упуская из виду потенциально более выгодные, но менее заметные области. Для эффективного использования LLM в задачах оптимизации необходимо разработать механизмы, позволяющие балансировать между использованием знаний, полученных из предварительного обучения, и активным исследованием новых, неизвестных областей пространства решений.
Проблемы, возникающие при использовании алгоритмов эволюционной оптимизации в сложных задачах, коренятся в сложном балансе между эксплуатацией найденных перспективных решений и исследованием всего пространства возможных вариантов. Слишком сильный уклон в сторону эксплуатации приводит к застреванию в локальных оптимумах, лишая систему возможности обнаружить более эффективные, но менее очевидные решения. В то же время, чрезмерное исследование без достаточной эксплуатации замедляет сходимость и требует значительно больше вычислительных ресурсов. Такой дисбаланс напрямую влияет на производительность и масштабируемость алгоритма, особенно в высокоразмерных пространствах, где поиск оптимального решения становится экспоненциально сложнее. Эффективное преодоление этой дилеммы является ключевой задачей для разработки новых, более устойчивых и эффективных методов оптимизации.
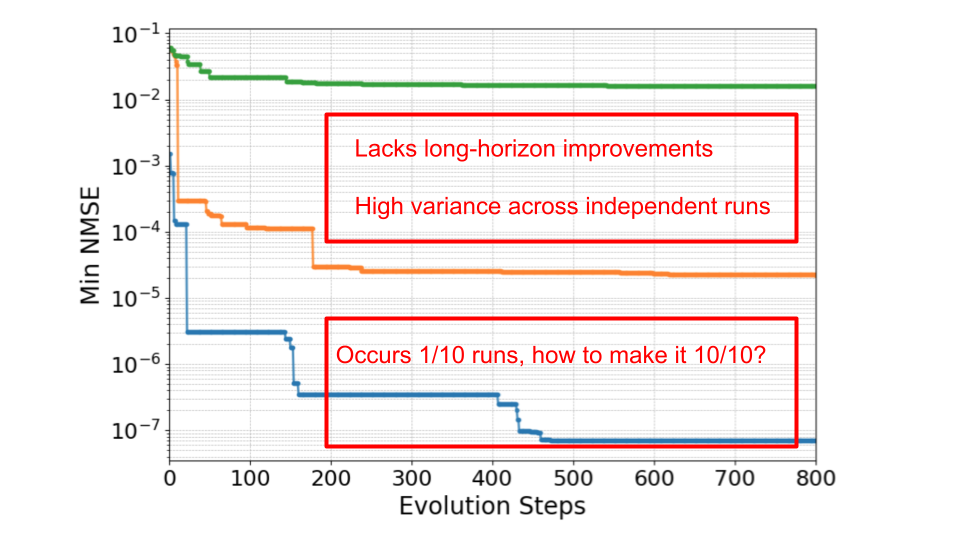
PACEvolve: Новый Взгляд на LLM-Управляемый Поиск
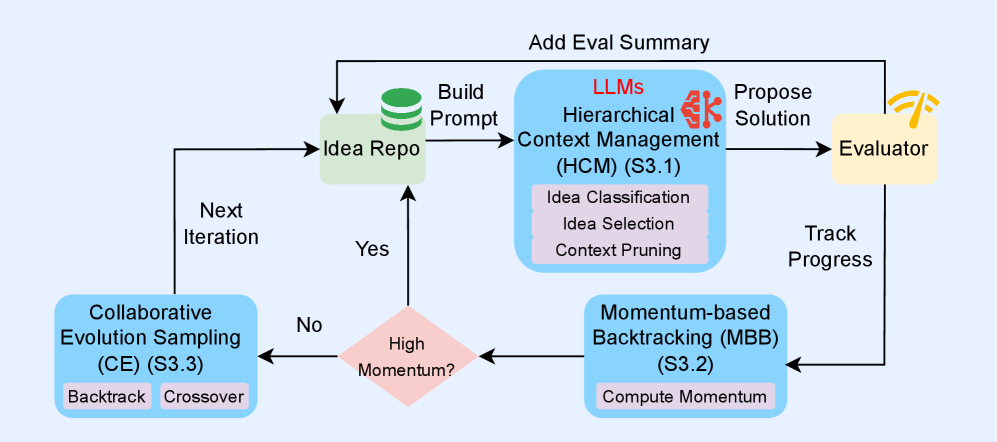
PACEvolve расширяет возможности LLM-Driven Evolutionary Search за счет внедрения иерархической системы управления контекстом. Данная система обеспечивает разделение процессов генерации и отбора идей, что позволяет поддерживать целенаправленный и когерентный поиск. Иерархическая структура позволяет алгоритму сохранять и использовать информацию о предыдущих шагах поиска, предотвращая отклонение от заданной цели и повышая эффективность генерации релевантных решений. Разделение генерации и отбора позволяет более точно контролировать процесс эволюции, избегая преждевременной конвергенции к локальным оптимумам и обеспечивая более глубокое исследование пространства поиска.
В рамках PACEvolve реализован механизм Momentum-Based Backtracking, позволяющий алгоритму избегать локальных минимумов и предотвращать стагнацию. Данная техника основана на интеллектуальном возврате к перспективным предковым состояниям, отобранным на основе оценки их потенциала для дальнейшего улучшения. В отличие от случайного возврата, Momentum-Based Backtracking учитывает историю поиска и приоритезирует состояния, которые ранее демонстрировали положительную динамику, что повышает эффективность поиска и позволяет алгоритму преодолевать барьеры, препятствующие достижению оптимального решения. Оценка перспективности предковых состояний производится на основе заданных критериев, обеспечивающих баланс между исследованием новых областей поиска и использованием накопленного опыта.
PACEvolve использует стратегию самоадаптивной совместной эволюционной выборки (Self-Adaptive Collaborative Evolution Sampling) для динамического баланса между внутренней разведкой пространства решений и внешним обменом знаниями между параллельными процессами. Этот подход позволяет алгоритму автоматически регулировать соотношение между исследованием новых вариантов и использованием информации, полученной от других процессов. Регулировка осуществляется на основе оценки эффективности каждого процесса и степени разнообразия генерируемых решений. В результате обеспечивается эффективное сотрудничество между процессами, что позволяет избежать преждевременной сходимости к локальным оптимумам и повысить общую скорость и качество поиска.
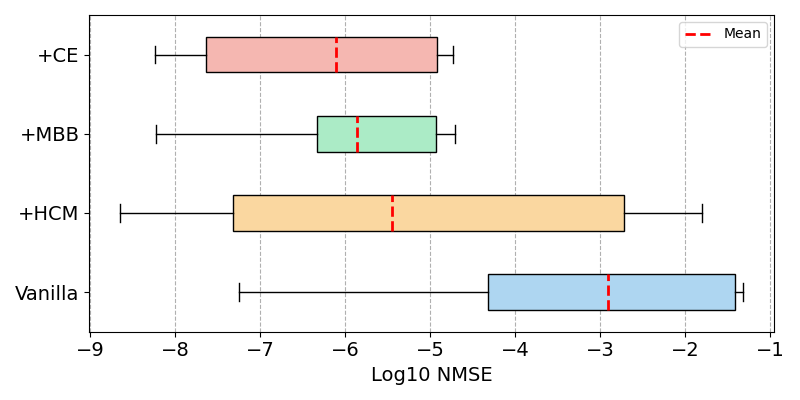
Эмпирическая Подтверждение: PACEvolve в Действии
Эффективность PACEvolve была тщательно проверена на KernelBench — комплексном наборе бенчмарков для ядер глубокого обучения. Результаты демонстрируют значительное превосходство над базовыми алгоритмами и достижение передовых показателей. KernelBench включает в себя широкий спектр задач, позволяющих всесторонне оценить производительность и масштабируемость алгоритмов автоматизированного машинного обучения. Систематическое тестирование на данном наборе бенчмарков подтверждает способность PACEvolve оптимизировать ядра глубокого обучения, обеспечивая улучшенную производительность в различных сценариях.
PACEvolve демонстрирует высокую эффективность в задачах символьной регрессии, в частности, при поиске уравнений, описывающих нелинейные осцилляторы. Данный подход позволяет автоматически выводить математические выражения, соответствующие наблюдаемым данным, что критически важно для моделирования сложных динамических систем. Успешное применение PACEvolve в данной области подтверждается его способностью находить точные и компактные представления для уравнений, описывающих поведение нелинейных осцилляторов, превосходя существующие методы в точности и эффективности поиска.
В ходе тестирования на бенчмарке KernelBench, PACEvolve продемонстрировал превосходство над существующими ядрами во всех протестированных случаях. Вариант PACEvolve-Multi достиг производительности 81.25%, превосходя PACEvolve-Single в 13 из 16 ядер. В сравнении с алгоритмами ShinkaEvolve и OpenEvolve, PACEvolve-Multi показал более высокую эффективность, одержав победу в 14 из 16 и 15 из 16 тестов соответственно, что свидетельствует о значительных улучшениях в производительности и эффективности.
Взгляд в Будущее: Значение и Перспективы PACEvolve
Алгоритм PACEvolve демонстрирует значительное снижение распространенных проблем, таких как коллапс моды и слабая кооперация, которые часто возникают в эволюционных алгоритмах, управляемых большими языковыми моделями. Традиционно, языковые модели, используемые для генерации и оценки решений в процессе эволюции, могут застревать в узком диапазоне вариантов, игнорируя перспективные, но менее вероятные решения — это и есть коллапс моды. Слабая кооперация проявляется, когда отдельные “особи” в популяции не вносят существенного вклада в общий прогресс. PACEvolve, благодаря своим инновационным механизмам отбора и мутации, способствует более разнообразному и эффективному исследованию пространства решений, обеспечивая тем самым стабильную эволюцию и предотвращая застой в локальных оптимумах. Это позволяет алгоритму находить более качественные и устойчивые решения для сложных задач.
Результаты тестирования PACEvolve на различных эталонных задачах демонстрируют значительное превосходство над существующими подходами, подтверждая перспективность интеграции больших языковых моделей с эволюционными алгоритмами для решения сложных проблем. Система успешно справляется с задачами, требующими как креативности в генерации решений, так и точной оптимизации, что указывает на ее способность эффективно использовать сильные стороны обеих парадигм. Достигнутые показатели свидетельствуют о том, что PACEvolve не просто улучшает существующие методы, но и открывает новые возможности для автоматизации процессов, ранее требовавших значительного человеческого участия и экспертных знаний, что делает ее ценным инструментом в различных областях науки и техники.
Дальнейшие исследования будут сосредоточены на применении PACEvolve в более сложных областях, таких как автоматизированное машинное обучение и научные открытия. Предполагается, что данный подход позволит значительно ускорить процесс разработки новых алгоритмов машинного обучения, оптимизируя их архитектуру и параметры без непосредственного участия человека. В контексте научных открытий, PACEvolve может быть использован для автоматического анализа больших объемов данных, выявления закономерностей и выдвижения гипотез, тем самым способствуя прогрессу в различных областях науки, от материаловедения до биологии. Перспективные направления включают в себя автоматизацию процесса проектирования новых материалов с заданными свойствами и разработку инновационных лекарственных препаратов на основе анализа геномных данных.
В исследовании 𝙿𝙰𝙲𝙴𝚟𝚘𝚕𝚟𝚎 наблюдается закономерность, напоминающая рост сложной экосистемы. Система не строится как монолит, но скорее взращивается через итеративные улучшения и адаптацию, подобно тому, как естественный отбор формирует виды. Авторы подчеркивают важность управления контекстом и предотвращения “застоя” в процессе эволюционного поиска, что соответствует идее поддержания биоразнообразия в экосистеме. В этом контексте, слова Винтон Серфа, «Интернет — это система, созданная для того, чтобы быть несовершенной», кажутся пророческими. Ведь в любой развивающейся системе неизбежны мутации и ошибки, которые, в конечном итоге, и приводят к ее эволюции и совершенствованию. Не стоит стремиться к идеальной стабильности, а скорее к устойчивости к изменениям и способности к самовосстановлению.
Куда же дальше?
Предложенный фреймворк 𝙿𝙰𝙲𝙴𝚟𝚘𝚕𝚟𝚎, несомненно, демонстрирует способность направлять эволюционный поиск, управляемый большими языковыми моделями. Однако, иллюзия полного контроля над такими системами обманчива. Каждое улучшение в контекстном управлении и коллаборации лишь откладывает неизбежное — наступление хаоса, порожденного сложностью самой задачи. Вместо стремления к «идеальной» архитектуре, представляется более плодотворным признание принципа: порядок — это лишь временный кэш между сбоями.
Особое внимание следует уделить исследованию механизмов, позволяющих не просто адаптироваться к изменениям в ландшафте поиска, но и предвидеть их. Речь идет не о предсказании будущего, но о создании систем, устойчивых к непредсказуемым событиям. Иными словами, вместо строительства крепости, необходимо научиться выращивать сад, способный выжить в бурю. Попытки создания самовосстанавливающихся систем, способных к рефлексии и перестройке своей стратегии поиска, представляются более перспективными, чем дальнейшая оптимизация существующих методов.
В конечном итоге, успех в этой области будет зависеть не от мощности вычислительных ресурсов или сложности алгоритмов, а от способности признать фундаментальную неопределенность, присущую процессу эволюции. Каждая новая архитектура обещает свободу, пока не потребует DevOps-жертвоприношений. Поэтому, вместо поиска «серебряной пули», следует сосредоточиться на создании гибких, адаптивных систем, способных сосуществовать с хаосом и извлекать из него пользу.
Оригинал статьи: https://arxiv.org/pdf/2601.10657.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-18 04:10