Автор: Денис Аветисян
Новая система RankEvolve автоматически находит эффективные методы ранжирования, используя возможности больших языковых моделей.
Автоматизированное обнаружение алгоритмов лексического поиска с применением эволюционных программных подходов и больших языковых моделей.
Несмотря на эффективность алгоритмов лексического поиска, таких как BM25, их совершенствование в значительной степени полагалось на ручную настройку параметров и интуицию экспертов. В работе ‘RankEvolve: Automating the Discovery of Retrieval Algorithms via LLM-Driven Evolution’ представлен новый подход к автоматическому поиску улучшенных алгоритмов ранжирования, основанный на эволюции программ с использованием больших языковых моделей. Разработанная система RankEvolve способна генерировать новые, эффективные функции ранжирования, превосходящие существующие методы на различных информационно-поисковых задачах. Возможно ли дальнейшее развитие этого подхода для автоматического создания полностью оптимизированных систем поиска, адаптированных к специфическим потребностям пользователей?
Пределы Традиционных Функций Ранжирования
Традиционные методы информационного поиска, такие как TF-IDF и BM25, исторически полагались на статистический анализ частоты встречаемости слов в документах и запросах. Однако, эти подходы испытывают значительные трудности при обработке семантической сложности языка и нюансированных запросов. Они оперируют преимущественно поверхностными признаками, не учитывая контекст, синонимию или полисемию слов. В результате, запрос, содержащий несколько ключевых слов, может вернуть множество документов, формально соответствующих этим словам, но не отвечающих на истинный информационный запрос пользователя. Например, запрос «яблоки для выпечки» может выдать документы о яблоках как фрукте, а не рецепты пирогов, поскольку алгоритм не понимает намерение пользователя — найти информацию о применении яблок в кулинарии, а не просто о самом фрукте.
Традиционные методы информационного поиска зачастую сталкиваются с проблемой понимания истинного намерения пользователя, скрывающегося за запросом. Даже при значительном совпадении ключевых слов между запросом и документом, система может возвращать нерелевантные результаты, поскольку не учитывает контекст и смысл. Например, запрос «яблоки» может относиться к фруктам, компании Apple или даже философской концепции, но алгоритмы, ориентированные лишь на частоту встречаемости слов, не способны распознать эту неоднозначность. Это приводит к тому, что пользователь получает информацию, формально соответствующую запросу, но не отвечающую его фактической потребности, что снижает эффективность поиска и требует дополнительных усилий для уточнения запроса или анализа полученных результатов.
Традиционные методы ранжирования информации, такие как TF-IDF и BM25, зачастую демонстрируют ограниченную адаптивность к разнообразию данных и усложнению информационных запросов. Их функциональность базируется преимущественно на поверхностных признаках, например, частоте встречаемости ключевых слов, что не позволяет учитывать семантические нюансы и истинные намерения пользователя. Вследствие этого, при работе с новыми доменами знаний или сложными запросами, требующими понимания контекста, эффективность этих методов существенно снижается, приводя к нерелевантным результатам, несмотря на формальное совпадение терминов. Ограниченность в анализе глубинной структуры запроса и содержания документов препятствует эффективной обработке информации в условиях постоянно растущего объема и сложности данных.
Эволюция Алгоритмов Поиска с Использованием Синтеза Программ
Синтез программ представляет собой перспективный подход к автоматическому построению функций ранжирования на основе заданных спецификаций. Однако, эффективность данного подхода напрямую зависит от используемых стратегий поиска. Автоматическое создание оптимальных функций ранжирования требует эффективного исследования пространства возможных программ, что представляет собой сложную задачу оптимизации. Необходимость в эффективных алгоритмах поиска обусловлена экспоненциальным ростом числа возможных программ даже при относительно простых спецификациях, что делает полный перебор невозможным и требует использования эвристических методов для сокращения пространства поиска и нахождения приемлемых решений в разумные сроки.
Генетическое программирование и обучение ранжированию (Learning to Rank) могут использоваться в качестве методов поиска при автоматическом построении функций ранжирования, однако оба подхода подвержены проблеме застревания в локальных оптимумах. Это означает, что алгоритм может найти решение, которое оптимально в небольшом диапазоне параметров, но не является глобально оптимальным. Кроме того, оба метода часто демонстрируют недостаток разнообразия в генерируемых решениях, что ограничивает область поиска и снижает вероятность обнаружения более эффективных алгоритмов. Недостаточное разнообразие связано с тенденцией алгоритмов эксплуатировать уже найденные хорошие решения вместо исследования новых, потенциально лучших, вариантов.
AlphaEvolve представляет собой платформу, предназначенную для автоматического создания алгоритмов ранжирования, преодолевающую ограничения традиционных методов, таких как генетическое программирование и Learning to Rank. В отличие от подходов, зависящих от заранее определенных операторов и эвристик, AlphaEvolve использует эволюционный поиск для генерации алгоритмов непосредственно из спецификаций, что позволяет создавать решения, выходящие за рамки человеческих представлений. Ключевой особенностью является возможность генерировать полностью новые алгоритмы, а не просто оптимизировать существующие, обеспечивая более широкий спектр поисковых стратегий и потенциально превосходя производительность ручных разработок. Архитектура платформы включает в себя генетический алгоритм, который оперирует с программой в виде графа вычислений, обеспечивая гибкость и выразительность в процессе поиска.
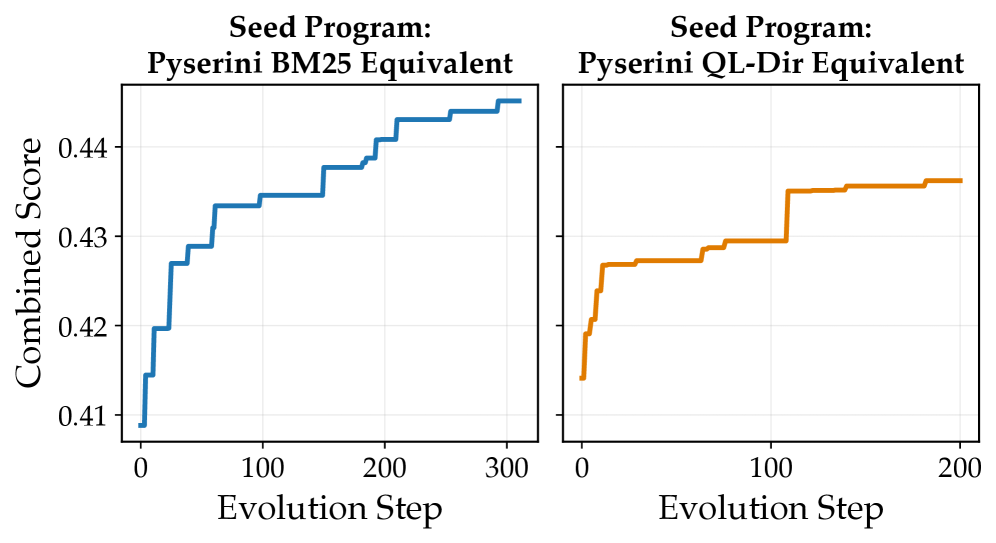
Усиление Разнообразия и Производительности посредством Эволюции
RankEvolve использует возможности большой языковой модели (LLM) в качестве оптимизатора для управления процессом эволюции алгоритмов ранжирования. Вместо традиционных методов, основанных на градиентах или случайном поиске, LLM выступает в роли функции оценки и направляет эволюцию к созданию программ, которые не только эффективны с точки зрения метрик качества ранжирования, но и обладают большей интерпретируемостью. LLM анализирует промежуточные варианты алгоритмов, предоставляя обратную связь, которая способствует развитию наиболее перспективных решений и предотвращает застревание в локальных оптимумах. Такой подход позволяет создавать алгоритмы, которые легче понять и модифицировать, что упрощает их адаптацию к новым задачам и данным.
Для поддержания разнообразия популяции алгоритмов ранжирования и предотвращения преждевременной сходимости, RankEvolve использует методы MAP-Elites и островной эволюции. MAP-Elites позволяет сохранять и исследовать алгоритмы, представляющие различные ниши в пространстве характеристик, а островная эволюция поддерживает несколько подпопуляций, развивающихся независимо друг от друга с периодическим обменом генетическим материалом. Такой подход способствует поддержанию широкого спектра решений и снижает риск застревания в локальных оптимумах, что критически важно для достижения высокой производительности и обобщающей способности на различных наборах данных.
Экспериментальные результаты, полученные на эталонных наборах данных BEIR и BRIGHT, демонстрируют превосходство RankEvolve над существующими методами. Алгоритм показал улучшения по ключевым метрикам, таким как Recall@100 и nDCG@10. В процессе эволюции наблюдалась монотонно возрастающая траектория целевой функции, определяемой как 0.8 \times Avg\ Recall@100 + 0.2 \times Avg\ nDCG@100, что свидетельствует о стабильном улучшении производительности на различных наборах данных.
Влияние и Перспективы в Области Открытия Алгоритмов
Успешная реализация RankEvolve наглядно демонстрирует перспективность автоматизированного поиска алгоритмов, позволяя отойти от традиционной практики ручной разработки. Вместо того, чтобы полагаться на экспертные знания и трудоемкий процесс создания алгоритмов «вручную», данная система способна самостоятельно генерировать и оптимизировать решения для задач ранжирования информации. Это открывает новые возможности для автоматизации сложных вычислительных процессов и позволяет создавать алгоритмы, превосходящие по эффективности те, что разработаны человеком, особенно в случаях, когда пространство возможных решений чрезвычайно велико и трудно поддается интуитивному анализу. Полученные результаты указывают на то, что автоматизированный подход к разработке алгоритмов может стать ключевым фактором инноваций в области информационного поиска и смежных областях.
Разработанный фреймворк демонстрирует высокую степень адаптивности к различным задачам информационного поиска, что выходит за рамки узкой специализации. Его архитектура позволяет не только оптимизировать существующие алгоритмы для повышения эффективности, но и создавать принципиально новые решения для сложных вычислительных задач. Исследователи полагают, что данная методология применима к широкому спектру алгоритмов, включая задачи машинного обучения, оптимизации и даже в областях, требующих разработки специализированных вычислительных моделей. Потенциал расширения фреймворка заключается в возможности адаптации к различным типам данных и вычислительных сред, что открывает перспективы для создания универсальных инструментов автоматизированной разработки алгоритмов.
Дальнейшие исследования направлены на изучение возможностей различных архитектур больших языковых моделей (LLM) для повышения эффективности процесса обнаружения алгоритмов. Особое внимание уделяется внедрению более сложных метрик разнообразия, которые позволят не только находить оптимальные решения, но и генерировать широкий спектр альтернативных алгоритмов, отличающихся подходами и структурами. Это позволит выйти за рамки поиска единственного «лучшего» алгоритма и создать набор специализированных решений, адаптированных к различным условиям и требованиям, значительно расширяя область применения автоматизированного поиска алгоритмов и открывая новые перспективы для оптимизации сложных вычислительных задач.
Исследование, представленное в данной работе, демонстрирует, что автоматическое развитие алгоритмов поиска с помощью больших языковых моделей открывает новые горизонты в области информационного поиска. Система RankEvolve, являясь ярким примером этого подхода, подчеркивает важность эволюционной оптимизации и способности LLM генерировать эффективные функции ранжирования. Как однажды заметил Джон Маккарти: «Всякий интеллект — это способность учиться и адаптироваться». Эта фраза прекрасно отражает суть RankEvolve, поскольку система не просто использует существующие алгоритмы, но и непрерывно эволюционирует, чтобы достичь лучших результатов, подобно живому организму, приспосабливающемуся к меняющимся условиям. Оптимизация, основанная на поиске, в данном контексте, позволяет системе находить оптимальные решения, а не полагаться на заранее заданные правила, что соответствует принципам гибкости и адаптивности.
Что Дальше?
Представленная работа демонстрирует, что автоматизация открытия алгоритмов поиска, основанная на больших языковых моделях, — не просто техническая возможность, но и неизбежность. Однако, элегантность этой автоматизации пока обманчива. Каждая оптимизация, даже кажущаяся удачной, порождает новые узлы напряжения в системе, новые области, требующие пристального внимания. Нельзя рассматривать RankEvolve как конечное решение, а лишь как отправную точку для более глубокого понимания структуры, определяющей поведение систем поиска.
Очевидным направлением дальнейших исследований является расширение пространства поиска алгоритмов. Текущий подход, сосредоточенный на лексическом поиске, — лишь вершина айсберга. Необходимо исследовать возможность эволюции алгоритмов, комбинирующих различные подходы — семантический, поведенческий, основанный на знаниях. Вместе с тем, возникает вопрос о масштабируемости: насколько хорошо подобный подход будет работать с более сложными задачами и огромными объемами данных?
Наконец, необходимо критически оценить саму природу «открытия» алгоритмов. Действительно ли RankEvolve «открывает» что-то новое, или лишь перекомбинирует существующие знания? Архитектура системы — это поведение системы во времени, а не схема на бумаге. Поэтому истинным критерием успеха будет не только повышение точности поиска, но и глубина понимания принципов, лежащих в основе эффективных алгоритмов.
Оригинал статьи: https://arxiv.org/pdf/2602.16932.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Виртуальная примерка без границ: EVTAR учится у образов
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
- Сердце музыки: открытые модели для создания композиций
- Квантовый скачок: от лаборатории к рынку
2026-02-22 19:21