Автор: Денис Аветисян
Исследователи предлагают инновационную систему, использующую принципы эволюции для автоматического улучшения программного кода и поиска оптимальных решений в научных задачах.
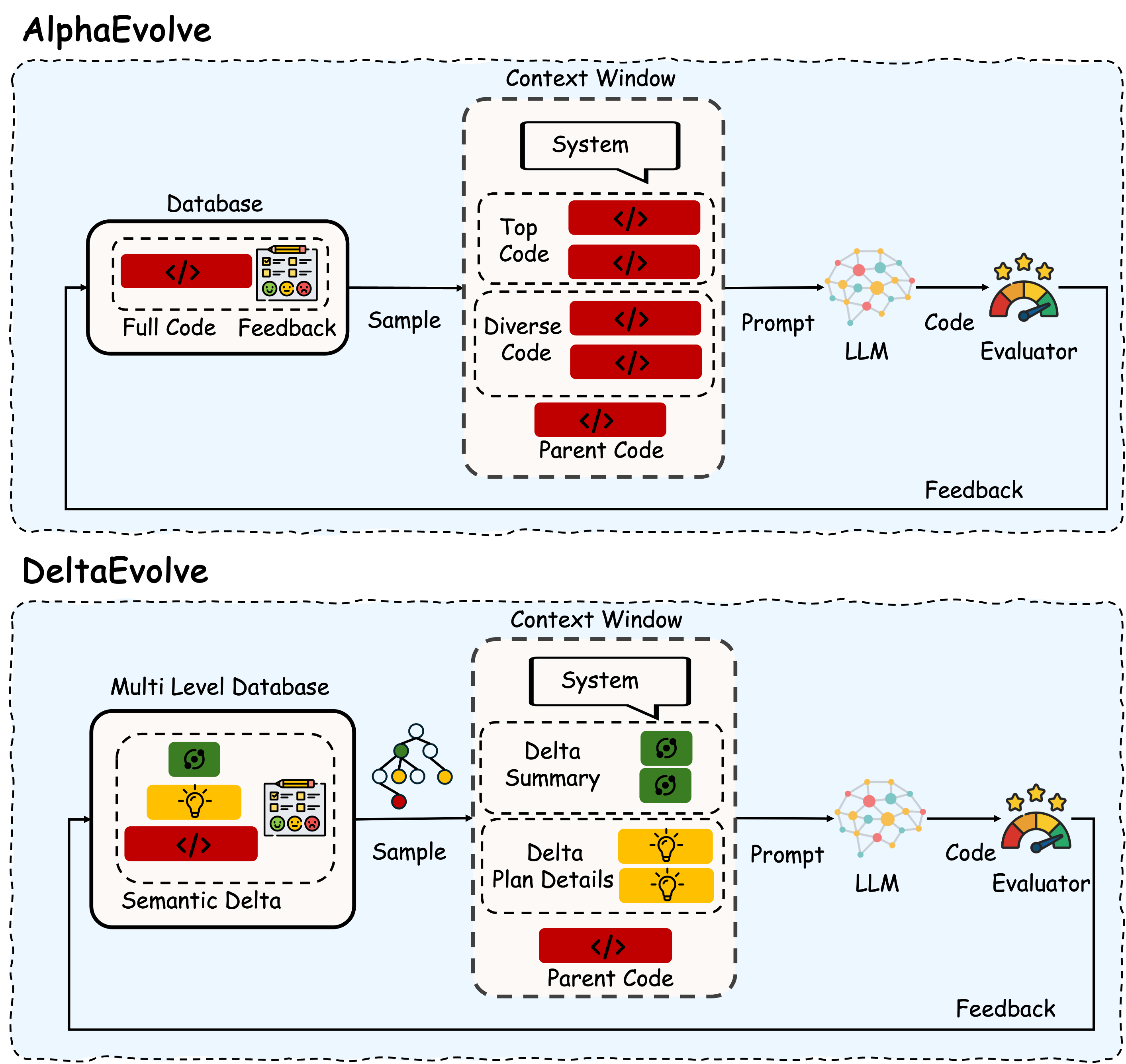
Представлен DeltaEvolve — фреймворк, использующий компактные ‘семантические дельты’ для повышения эффективности эволюции программного кода на основе больших языковых моделей.
Несмотря на перспективность автоматизированного научного поиска с использованием LLM, существующие эволюционные системы, такие как AlphaEvolve, часто страдают от неэффективности контекста из-за сохранения полных версий кода. В данной работе, посвященной разработке фреймворка ‘DeltaEvolve: Accelerating Scientific Discovery through Momentum-Driven Evolution’, предлагается новый подход, основанный на представлении изменений в программах в виде компактных семантических дельт, что позволяет значительно сократить объем входных токенов и повысить эффективность эволюционного процесса. Экспериментальные результаты показывают, что DeltaEvolve позволяет находить более качественные решения в различных научных областях, потребляя при этом меньше вычислительных ресурсов. Способно ли такое представление эволюционного контекста стать стандартом для автоматизированного научного поиска и синтеза программ?
Пределы масштаба: Вызовы оптимизации «чёрных ящиков»
Многие задачи, с которыми сталкивается современная наука и промышленность, относятся к категории так называемой «черноящиковой оптимизации». Это означает, что функция, определяющая желаемый результат, настолько сложна и многогранна, что её внутреннее устройство остаётся непрозрачным. По сути, исследователи и инженеры могут лишь наблюдать входные данные и соответствующие выходные значения, не имея возможности анализировать или модифицировать внутренние процессы, влияющие на результат. Примерами могут служить оптимизация логистических цепочек, разработка новых материалов с заданными свойствами или даже поиск оптимальных параметров для сложных финансовых моделей. В таких ситуациях традиционные методы оптимизации, требующие полного понимания функции, оказываются неэффективными, а поиск решения превращается в сложный процесс проб и ошибок.
Традиционные методы оптимизации часто сталкиваются с существенными вычислительными затратами при исследовании обширных пространств поиска, особенно в контексте использования больших языковых моделей (LLM). Проблема усугубляется экспоненциальным ростом сложности с увеличением числа параметров и переменных, что делает полный перебор или даже применение стандартных алгоритмов непрактичным. LLM, несмотря на свою мощь, требуют значительных ресурсов для обработки и анализа больших объемов данных, что приводит к увеличению времени вычислений и потребления энергии. Таким образом, задача эффективного исследования пространства поиска при использовании LLM представляет собой серьезный вызов, требующий разработки новых подходов, способных снизить вычислительную нагрузку и повысить скорость оптимизации.
Ограниченный контекст, доступный большим языковым моделям (LLM), представляет собой существенное препятствие для решения сложных задач оптимизации. Эта особенность архитектуры LLM напрямую влияет на их способность эффективно исследовать пространство поиска и углубленно анализировать проблему. В процессе оптимизации модели вынуждены оперировать лишь частью информации, что ограничивает их возможности по выявлению оптимальных решений, особенно в задачах, требующих долгосрочного планирования или учета взаимосвязей между множеством параметров. Неспособность удерживать в памяти значительный объем данных о предыдущих шагах поиска приводит к повторным ошибкам и замедляет процесс сходимости к желаемому результату, что делает эффективное использование LLM в задачах с обширным пространством поиска крайне сложной задачей.
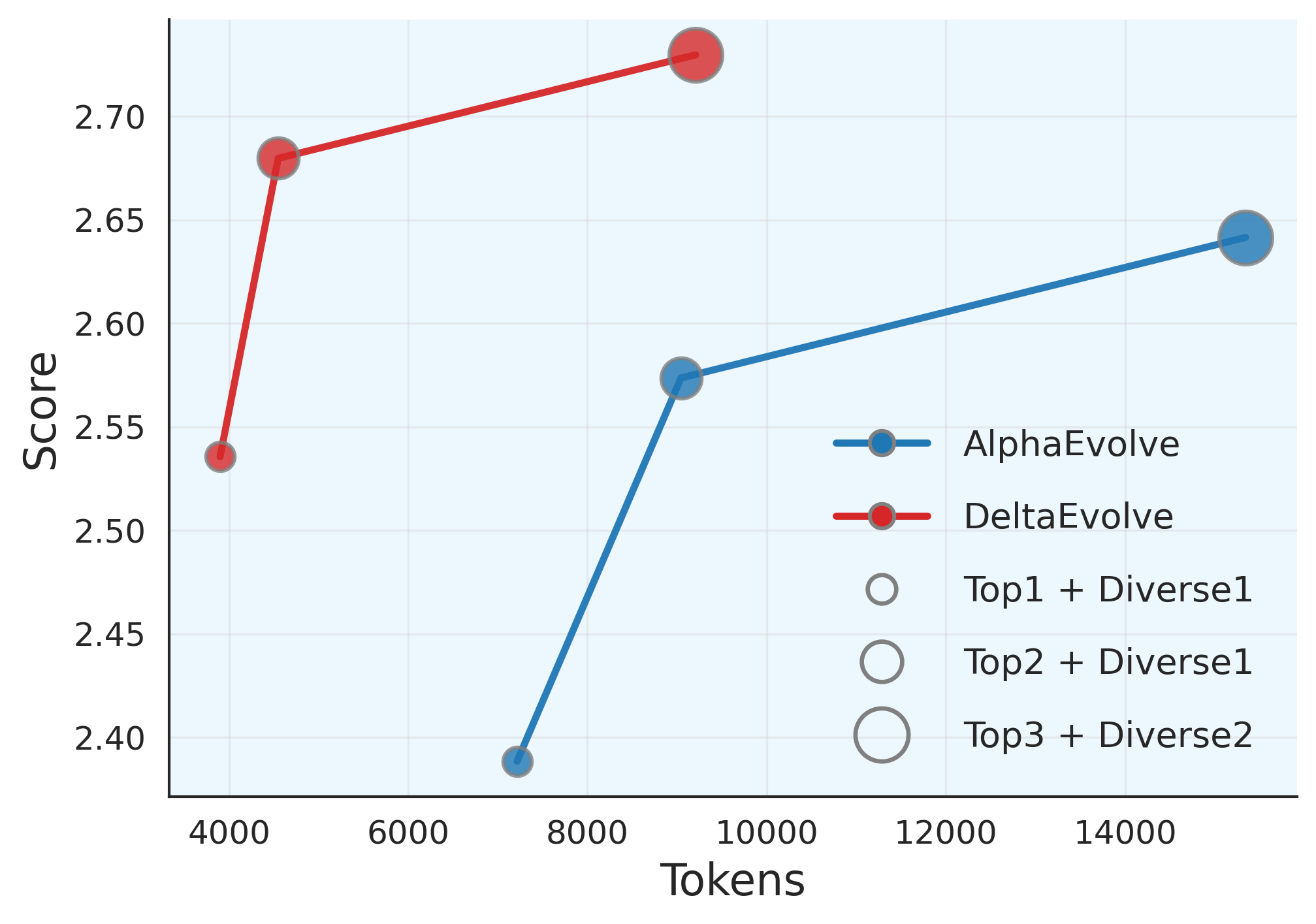
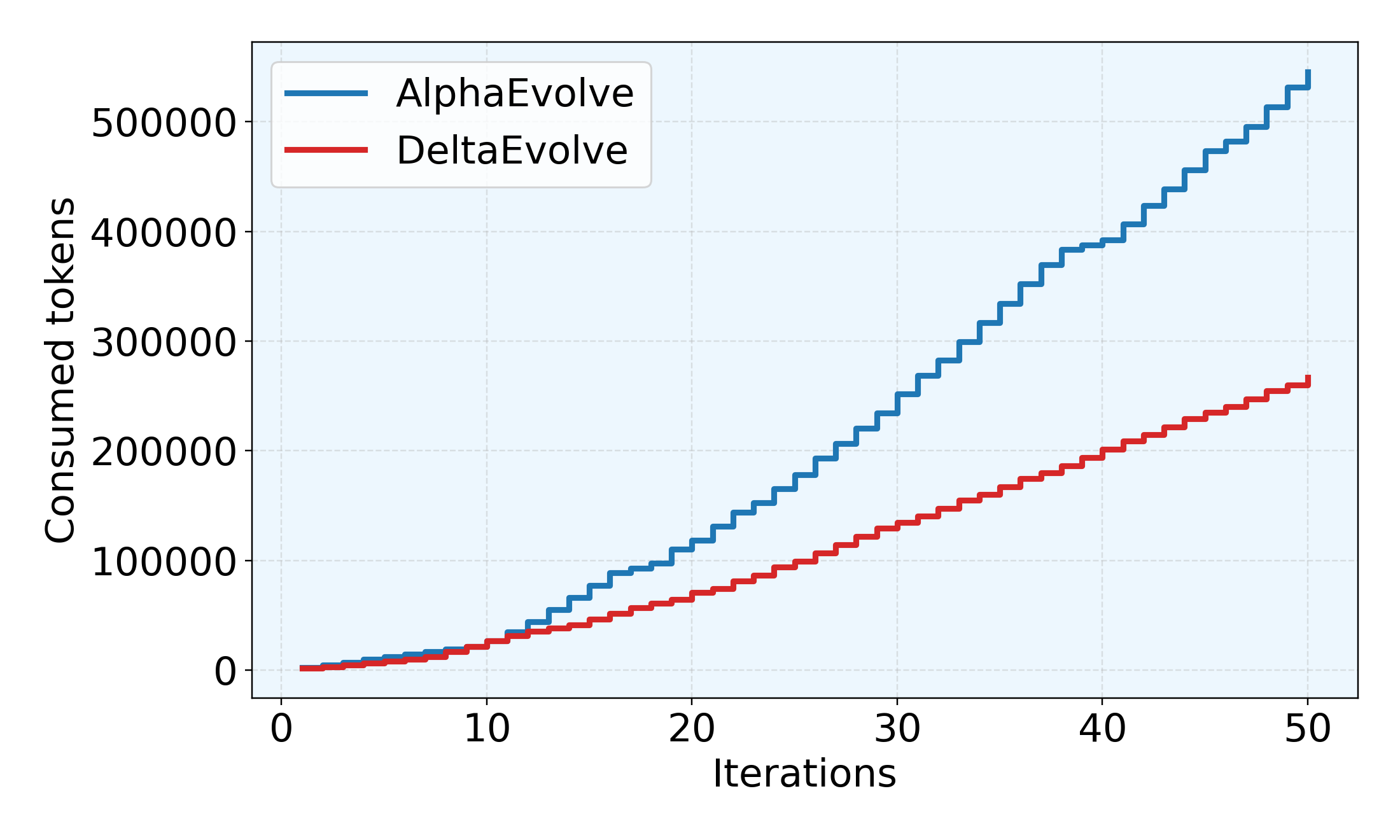
Высокое потребление токенов представляет собой существенное ограничение при использовании больших языковых моделей (LLM) для решения сложных задач, значительно увеличивая вычислительные затраты и время обработки. Данная проблема особенно актуальна при оптимизации «черных ящиков», где необходимо исследовать обширные пространства поиска. Разработанный подход DeltaEvolve направлен на смягчение этого ограничения путем оптимизации процесса взаимодействия с LLM, что позволяет снизить среднее потребление токенов примерно на 36.79%. Такое снижение позволяет не только уменьшить финансовые издержки, связанные с использованием LLM, но и расширить возможности применения этих моделей для более масштабных и ресурсоемких задач оптимизации, делая их более доступными и эффективными для широкого круга пользователей.
DeltaEvolve: Эволюция решений с помощью семантических дельт
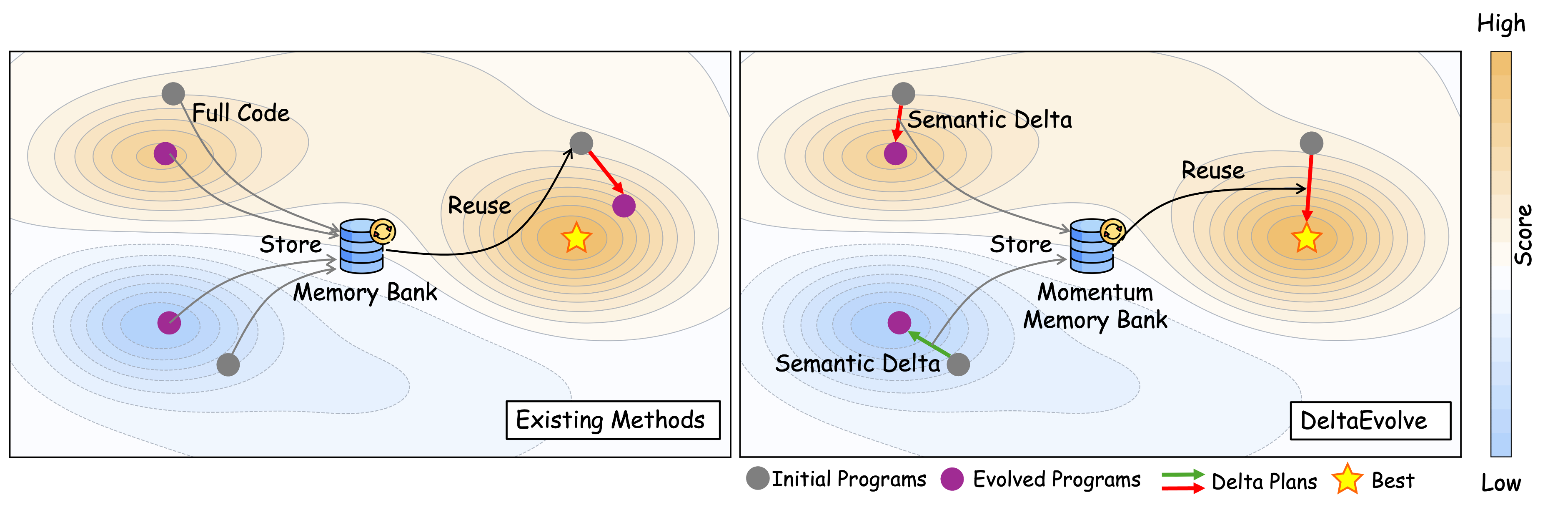
В основе DeltaEvolve лежит использование семантических дельт — компактных представлений изменений между состояниями программы. Вместо эволюции полных программ, DeltaEvolve оперирует этими дельтами, что значительно снижает вычислительные затраты. Семантическая дельта представляет собой минимальный набор изменений, необходимых для перехода от одного работоспособного состояния программы к другому. Такой подход позволяет уменьшить объем данных, обрабатываемых языковой моделью (LLM), и, следовательно, снизить требования к объему контекстного окна, необходимого для эффективной работы. Размер дельты обычно существенно меньше, чем размер полной программы, что обеспечивает экономию ресурсов и ускоряет процесс эволюции.
В DeltaEvolve, эволюция происходит не над полным исходным кодом программы, а над семантическими дельтами — компактными представлениями изменений состояния программы. Это существенно снижает требования к объему контекстного окна большой языковой модели (LLM), поскольку дельты значительно меньше по размеру, чем полные программы. Вместо обработки и модификации всего кода, LLM оперирует лишь с изменениями, необходимыми для достижения желаемого результата, что позволяет обрабатывать более сложные задачи и эволюционировать программы, превышающие возможности обработки полных программ в ограниченном контекстном окне.
В DeltaEvolve для ускорения обучения и направления эволюционного процесса используется механизм, вдохновлённый принципами оптимизации, а именно — импульс (momentum). Этот подход позволяет учитывать предыдущие шаги эволюции при определении текущего направления поиска, что способствует более быстрой сходимости к оптимальным решениям. В отличие от случайного поиска, импульс позволяет сохранять информацию о градиенте изменения целевой функции, эффективно «раскачивая» эволюцию в перспективных направлениях и избегая локальных оптимумов. Эффект импульса заключается в том, что изменения в программе, приведшие к улучшению результатов на предыдущих итерациях, усиливают вероятность аналогичных изменений в будущем, тем самым обеспечивая более стабильное и предсказуемое обучение.
В основе DeltaEvolve лежит многоуровневая база данных, предназначенная для организации информации о программах и их изменениях. Она включает в себя три основных уровня: краткие сводки дельт (delta summaries), содержащие высокоуровневое описание изменений; планы дельт (delta plans), детализирующие шаги, необходимые для применения изменений; и полный исходный код программы. Такая структура позволяет эффективно получать доступ к различным уровням детализации, ускоряя процесс эволюции и снижая вычислительные затраты за счет манипулирования компактными представлениями изменений, а не полными копиями программного кода. Организация данных по уровням также оптимизирует хранение и поиск информации, необходимой для отслеживания и применения эволюционных изменений.
Подтверждение эффективности: Решение разнообразных задач
DeltaEvolve продемонстрировал высокую эффективность при решении разнообразных сложных задач. В ходе тестирования, фреймворк успешно применялся для задач символьной регрессии, где необходимо было найти аналитическое выражение, описывающее заданные данные. Кроме того, DeltaEvolve показал хорошие результаты в задаче оптимальной упаковки шестиугольников, требующей нахождения наиболее плотной конфигурации. Успешно решались и задачи, связанные с численным решением частных дифференциальных уравнений (PDESolver), что подтверждает универсальность подхода и его применимость в различных областях науки и техники. Результаты тестирования показывают, что DeltaEvolve способен эффективно справляться с задачами, требующими как аналитических, так и численных методов.
Эффективность фреймворка дополнительно повышается за счет использования ансамбля больших языковых моделей (LLM). Вместо использования одной языковой модели, DeltaEvolve объединяет несколько, что позволяет использовать различные сильные стороны каждой из них. Этот подход позволяет снизить вероятность ошибок, свойственных отдельным моделям, и повысить общую надежность и точность решения задач. Комбинирование результатов, полученных от разных LLM, выполняется с использованием методов агрегации, что позволяет получить более устойчивое и качественное решение, чем при использовании одной модели.
В DeltaEvolve реализована интеграция с алгоритмом качества-разнообразия MAP-Elites, что позволяет поддерживать разнообразный набор решений и повышать устойчивость системы. MAP-Elites функционирует путем организации популяции решений в пространстве характеристик, определяемых метриками качества и новизны. Этот подход позволяет избежать преждевременной сходимости к субоптимальным решениям и обеспечивает исследование широкого спектра возможных стратегий. Поддерживая разнообразие, система становится более устойчивой к изменениям в условиях задачи и способна адаптироваться к новым требованиям, обеспечивая надежность и предсказуемость результатов.
Прогрессивный отборник (Progressive Disclosure Sampler) динамически регулирует объем предоставляемой информации языковой модели (LLM) в процессе решения задачи. Этот механизм основан на адаптивном изменении уровня детализации входных данных, что позволяет максимизировать прирост информации при минимальном потреблении токенов. Изначально LLM предоставляется только основная информация, и по мере необходимости, в зависимости от хода решения, предоставляются дополнительные детали. Такой подход позволяет избежать перегрузки LLM избыточными данными, снижает вычислительные затраты и повышает эффективность работы, особенно при решении сложных задач, требующих обработки большого объема информации.
За пределами текущих ограничений: Перспективы и влияние
В основе DeltaEvolve лежит принципиально новый подход к применению больших языковых моделей (LLM) для решения сложных задач. Вместо обработки полной истории кода, как это делает AlphaEvolve, DeltaEvolve фокусируется на представлении лишь семантических изменений — дельт, отражающих суть эволюции решения. Такой акцент на эффективном представлении и инкрементальных улучшениях позволяет преодолеть ключевое ограничение, с которым сталкиваются LLM при работе со сложными проблемами: экспоненциальный рост объема информации, требующей обработки. Игнорируя избыточность и сосредотачиваясь на значимых изменениях, DeltaEvolve существенно снижает потребление токенов, обеспечивая сопоставимую, а зачастую и превосходящую производительность по сравнению с традиционными методами, и открывая путь к созданию более масштабируемых и адаптивных интеллектуальных систем.
В основе архитектуры DeltaEvolve лежит принцип использования семантических дельт, что открывает возможности для непрерывного обучения и адаптации агентов. Вместо хранения полной истории изменений кода, система фокусируется на фиксации лишь значимых семантических различий между версиями, позволяя ей эффективно отслеживать эволюцию стратегий решения задач. Такой подход не только снижает потребность в вычислительных ресурсах и объеме памяти, но и способствует более гибкому и оперативному совершенствованию алгоритмов. Агенты, использующие DeltaEvolve, способны постепенно уточнять свои методы, извлекая уроки из предыдущих итераций и адаптируясь к изменяющимся условиям, что обеспечивает устойчивое повышение эффективности в долгосрочной перспективе.
В отличие от подхода AlphaEvolve, использующего полную историю кода, DeltaEvolve демонстрирует, что более лаконичное представление информации может обеспечивать сопоставимую или даже превосходящую производительность. Исследования показали, что новая система позволяет снизить потребление токенов примерно на 36.79% в среднем, применительно к пяти различным научным областям. Это достигается за счет фокусировки на семантических дельтах — изменениях в коде, несущих ключевую информацию — вместо хранения всей предыдущей истории, что значительно повышает эффективность и масштабируемость системы, особенно при работе с крупными и сложными задачами.
Дальнейшие исследования сосредоточены на изучении синергии между DeltaEvolve и другими эволюционными алгоритмами, в частности, алгоритмом Expectation-Maximization (EM). Предполагается, что комбинирование семантических дельт DeltaEvolve, обеспечивающих эффективное представление изменений, с итеративным подходом EM, направленным на максимизацию правдоподобия, позволит значительно расширить возможности агентов. Такой гибридный подход может привести к более быстрой сходимости, улучшенной адаптации к новым задачам и повышению общей производительности в сложных научных областях. Особое внимание будет уделено разработке методов интеграции, позволяющих использовать сильные стороны каждого алгоритма и компенсировать их недостатки, что открывает перспективы для создания интеллектуальных систем, способных к непрерывному обучению и самосовершенствованию.
Исследование демонстрирует стремление к лаконичности как ключевой фактор прогресса. Авторы предлагают подход, где изменения программного кода представляются не как полные копии, а как компактные ‘семантические дельты’. Это соответствует принципу, что сложность требует алиби. Подобный механизм, оптимизирующий потребление токенов, позволяет ускорить процесс эволюции программ, фокусируясь на существенных изменениях. Г.Х. Харди заметил: «Математика — это искусство делать сложные вещи простыми». В данном исследовании, стремление к упрощению представлений о программном коде, подобно математической элегантности, открывает новые возможности для автоматического поиска решений.
Куда Далее?
Представленный подход, хотя и демонстрирует эффективность в представлении эволюционных изменений, не является панацеей. Очевидным ограничением остаётся зависимость от адекватности семантического представления. Упрощение, неизбежное при создании «дельта», всегда несёт риск потери информации, критичной для последующих итераций. Вопрос не в скорости, а в точности приближения к истине.
Будущие исследования должны сосредоточиться на адаптивном определении размера «дельта». Статичное представление неизбежно компрометирует либо скорость, либо качество. Возможность динамической корректировки уровня детализации, основанной на анализе ландшафта поиска, представляется перспективной, но сложной задачей. Кроме того, необходимо исследовать взаимодействие «дельта» с различными архитектурами больших языковых моделей — универсальность подхода требует подтверждения.
В конечном счёте, ценность исследования заключается не в ускорении эволюции программного кода, а в осознании принципиальной возможности представления изменений в компактной, семантически значимой форме. Истинную экономию достигает не тот, кто быстрее перебирает варианты, а тот, кто задаёт правильные вопросы.
Оригинал статьи: https://arxiv.org/pdf/2602.02919.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Самообучающиеся агенты: новый подход к автономным системам
- Графы и действия: новый подход к планированию для роботов
- Третья Разновидность ИИ: Как модели, думающие «про себя», оставят позади GPT и CoT
- Охота на уязвимости: как большие языковые модели учатся на ошибках прошлого
- Тест Тьюринга: Защита старого друга
- BOOM: Визуальный перевод лекций: новый уровень доступности
- Визуальное мышление машин: проверка на прочность
- Генерация изображений: Новый взгляд на скорость и детализацию
2026-02-05 04:58