Автор: Денис Аветисян
Новый подход к синтезу данных, основанный на анализе реальных процессов разработки программного обеспечения, позволяет создавать более эффективные системы, способные решать сложные инженерные задачи.
В статье представлен daVinci-Agency — метод синтеза данных, использующий цепочки Pull Request для обучения агентов в задачах с долгосрочным планированием и требующих высокой эффективности.
Несмотря на успехи больших языковых моделей в решении краткосрочных задач, масштабирование их для выполнения сложных, долгосрочных задач агентами остается серьезной проблемой из-за нехватки обучающих данных. В работе ‘daVinci-Agency: Unlocking Long-Horizon Agency Data-Efficiently’ предложен новый подход к синтезу данных, основанный на анализе цепочек Pull Request из реальных проектов разработки программного обеспечения. Такой подход позволяет создавать высококачественные траектории обучения, отражающие естественную эволюцию задач и обеспечивающие эффективное обучение агентов, демонстрируя значительное улучшение производительности — в частности, прирост в 47% на бенчмарке Toolathlon. Возможно ли, используя аналогичные методы, создать обучающие данные для агентов, способных решать еще более сложные и долгосрочные задачи в различных областях?
Вызов Долгосрочного Рассуждения
Современные системы искусственного интеллекта сталкиваются с серьезными трудностями при решении задач, требующих последовательного рассуждения на протяжении длительных цепочек событий. Эта проблема ограничивает их применение в областях, где необходим анализ сложных ситуаций и прогнозирование последствий действий на большом временном горизонте, таких как долгосрочное планирование, научные исследования и принятие стратегических решений. В отличие от человека, способного удерживать в памяти и анализировать множество взаимосвязанных факторов, ИИ часто теряет контекст и допускает ошибки, когда последовательность действий становится слишком длинной и сложной. Неспособность эффективно обрабатывать длинные последовательности ограничивает потенциал искусственного интеллекта в решении реальных задач, требующих глубокого понимания причинно-следственных связей и способности предвидеть отдаленные последствия.
Традиционные подходы к искусственному интеллекту часто оказываются неспособными адекватно учитывать взаимосвязи, возникающие в задачах, требующих долгосрочного планирования и рассуждений. Ограничения возникают из-за того, что алгоритмы, разработанные для обработки краткосрочных данных, испытывают трудности с сохранением и анализом информации на протяжении длительных последовательностей. Это приводит к несогласованности в принятых решениях и, как следствие, к ошибкам, особенно в ситуациях, где каждое действие влияет на последующие шаги. Неспособность улавливать эти скрытые зависимости значительно снижает эффективность систем ИИ в решении сложных задач, требующих стратегического мышления и прогнозирования последствий на большом временном горизонте.
Для полноценного освоения задач, требующих долгосрочного планирования и рассуждений, необходимо создание специализированных наборов данных. Эти данные должны не просто демонстрировать последовательность действий, но и отражать сложные взаимосвязи между событиями, происходящими на разных этапах. Обычные наборы данных часто оказываются недостаточными, поскольку не учитывают динамику многошаговых рассуждений и не позволяют искусственному интеллекту эффективно выявлять скрытые зависимости. Поэтому, разработка данных, специально предназначенных для моделирования долгосрочных зависимостей, является ключевым шагом на пути к созданию систем искусственного интеллекта, способных к последовательному и логичному мышлению в сложных сценариях.
daVinci-Agency: Новая Парадигма Синтеза Данных
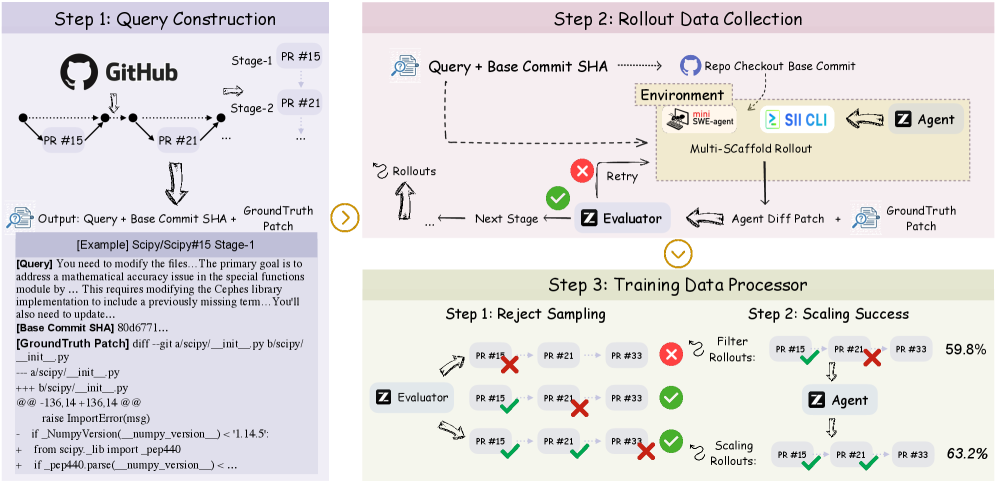
daVinci-Agency использует эволюцию запросов на внесение изменений (Pull Requests, PR) в реальных проектах разработки программного обеспечения в качестве источника для построения задач с горизонтом планирования на длительный срок. Процесс извлечения данных основан на анализе последовательности изменений, вносимых в PR, и их взаимосвязей. Вместо синтетических данных, daVinci-Agency использует исторические данные о разработке, что позволяет создавать цепочки задач, отражающие реальные сценарии и зависимости, возникающие в процессе разработки программного обеспечения. Этот подход позволяет генерировать обучающие данные с присущей им долгосрочной согласованностью, поскольку каждая стадия задачи логически вытекает из предыдущей, как это происходит в реальных проектах.
Парадигма daVinci-Agency использует семантические зависимости, обнаруженные в запросах на включение изменений (pull requests) в реальных проектах разработки программного обеспечения, для моделирования сложных задач. Анализ этих зависимостей позволяет выявить последовательность действий и взаимосвязи между различными частями кода, что, в свою очередь, дает возможность создавать обучающие данные, обладающие внутренней согласованностью на протяжении длительных временных горизонтов. В отличие от синтетических данных, генерируемых случайным образом, данные, полученные из PR, отражают реальные сценарии разработки и обеспечивают логическую последовательность шагов, необходимую для обучения моделей, способных решать сложные, многоэтапные задачи.
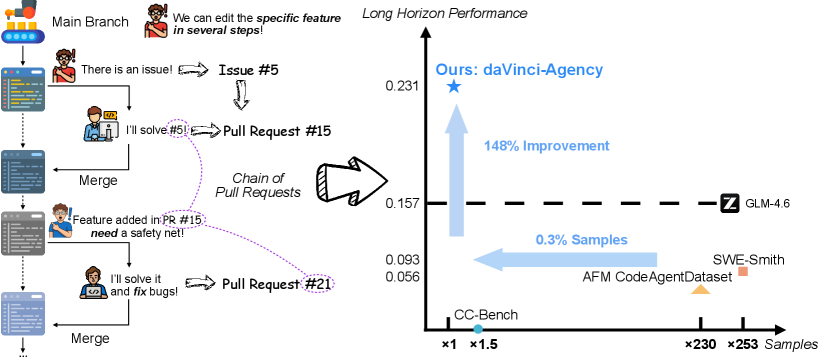
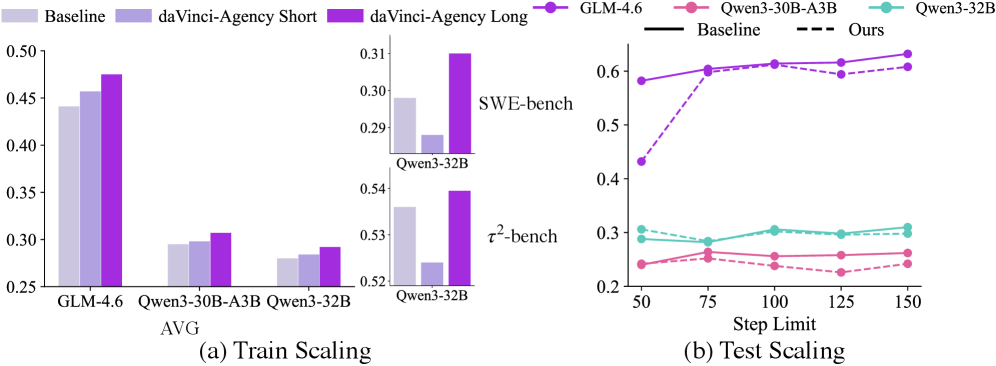
В основе daVinci-Agency лежит процесс, включающий в себя два ключевых этапа: Формулирование запросов и Построение цепочек PR. Формулирование запросов преобразует данные из pull request (PR) в формат, пригодный для обучения моделей искусственного интеллекта. Далее, построение цепочек PR создает многошаговые задачи, используя семантические зависимости между PR. В результате применения данной методологии, на бенчмарке Toolathlon зафиксировано относительное увеличение производительности на 47% по сравнению с существующими подходами.
Обеспечение Качества Данных и Обучения Модели
Для обеспечения качества генерируемых данных используется метод отбора проб (Rejection Sampling), который позволяет отфильтровывать образцы низкого качества. Этот процесс включает в себя оценку каждого сгенерированного образца на соответствие заданным критериям качества, таким как согласованность, релевантность и отсутствие ошибок. Образцы, не соответствующие этим критериям, отбрасываются, что гарантирует использование для обучения моделей только высококачественного набора данных. Применение данного метода необходимо для повышения надежности и эффективности обученных моделей, а также для минимизации влияния некачественных данных на конечные результаты.
Обучение агентивных систем осуществляется на основе отфильтрованных данных с использованием архитектуры GLM-4.6. GLM-4.6 представляет собой модель генеративного типа, оптимизированную для эффективного обучения с подкреплением и решения сложных задач. Использование данной архитектуры позволяет агентам более эффективно усваивать информацию из отфильтрованного набора данных, что способствует повышению их производительности и точности в процессе выполнения задач. Особенностью GLM-4.6 является способность к эффективной обработке больших объемов данных и адаптации к различным типам задач, что делает её подходящей для обучения агентивных систем, требующих высокого уровня интеллекта и автономности.
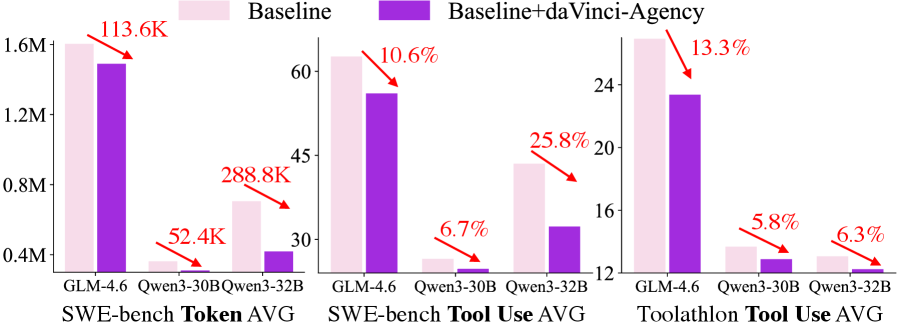
В ходе тестирования на бенчмарке SWE-bench, разработанные агентские системы продемонстрировали значительное повышение эффективности. В частности, зафиксировано снижение объема использованных токенов на 113.6K и уменьшение частоты вызова инструментов на 25.8%. Данные результаты обусловлены превосходством систем в областях декомпозиции задач — разбиении сложных проблем на последовательность более простых шагов — и вызове инструментов, позволяющем эффективно использовать внешние ресурсы для решения поставленных задач.
Достижение Надежной Долгосрочной Производительности
Синтезированные данные и обученные агенты демонстрируют заметно улучшенную долгосрочную согласованность при решении задач, требующих планирования на большом горизонте. Это существенный прорыв по сравнению с предыдущими методами, которые часто сталкивались с проблемой “забывания” начальных целей или накопления ошибок по мере увеличения продолжительности задачи. Новый подход позволяет агентам сохранять когерентность действий на протяжении длительных периодов времени, эффективно справляясь со сложными, многоэтапными процессами. В отличие от традиционных систем, которые склонны к колебаниям и непредсказуемому поведению в долгосрочной перспективе, представленное решение обеспечивает стабильные и надежные результаты, что критически важно для применения в реальных сценариях, требующих устойчивого и предсказуемого поведения.
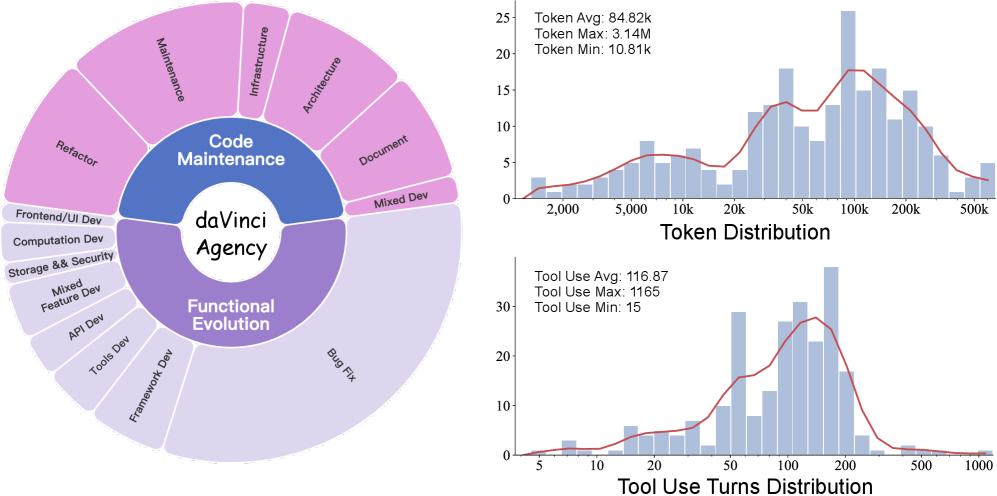
Данный подход позволяет моделировать эволюцию процессов на разных стадиях, учитывая динамические взаимосвязи между отдельными фазами сложной задачи. В отличие от традиционных методов, фокусирующихся на изолированном анализе каждого этапа, представленная система способна отслеживать изменения и зависимости во времени. Это достигается за счет значительно расширенной траектории обучения — до 84.82 тысяч токенов — что позволяет моделям лучше адаптироваться к изменяющимся условиям и демонстрировать более стабильные результаты в долгосрочной перспективе. Таким образом, система не просто решает задачу, а «обучается» понимать её внутреннюю динамику и предвидеть развитие событий на различных этапах.
Постоянное улучшение как процесса синтеза данных, так и обучения моделей позволило добиться устойчивой и надёжной работы в задачах, требующих длительных рассуждений. В ходе итеративных циклов доработки, алгоритмы не только адаптируются к новым данным, но и оптимизируют внутренние параметры, что обеспечивает стабильность результатов на протяжении всего процесса решения сложных задач. Такой подход позволяет преодолеть ограничения, свойственные традиционным методам, и гарантирует, что система сохраняет свою эффективность даже в условиях неопределенности и изменяющихся требований. В результате, разработанные модели демонстрируют значительное превосходство в сценариях, где важна последовательность и точность на протяжении длительного периода времени.
Исследование представляет собой элегантное решение проблемы долгосрочного планирования в агентах, используя цепочки Pull Request как источник данных для обучения. Этот подход демонстрирует математическую дисциплину в организации хаоса реальных проектов разработки программного обеспечения. Тим Бернерс-Ли однажды сказал: «Веб — это не просто набор связанных страниц, а платформа для обмена знаниями». Аналогично, daVinci-Agency создает платформу для обмена знаниями между этапами разработки, позволяя агентам эффективно обучаться на данных, полученных из естественной эволюции кода, и демонстрируя принципиальную возможность построения доказуемо корректных агентов для сложных задач.
Куда Ведет Эта Дорога?
Представленный подход, используя цепочки Pull Request как источник данных для обучения агентов, безусловно, элегантен в своей простоте. Однако, стоит признать, что сама идея синтеза данных, даже основанная на реальных процессах разработки, остается лишь приближением к истинной проблеме — созданию агента, способного к автономному рассуждению и решению сложных задач. Очевидным ограничением является зависимость от качества исходных данных — насколько репрезентативны цепочки Pull Request для всех аспектов разработки программного обеспечения? И, что более важно, как избежать запечатления в обученном агенте тех же самых ошибок и неоптимальных решений, которые присутствуют в коде, написанном людьми?
Дальнейшие исследования, вероятно, должны быть направлены на разработку более строгих методов оценки качества синтезированных данных и на интеграцию формальных методов верификации в процесс обучения агента. Попытки «обучить» агента на неполных или противоречивых данных неизбежно приведут к созданию системы, чье поведение будет непредсказуемым, а надежность — сомнительной. Следовательно, вопрос не в том, чтобы увеличить объем данных, а в том, чтобы обеспечить их математическую чистоту и непротиворечивость.
В конечном итоге, истинный прогресс в области агентного программирования заключается не в создании все более сложных алгоритмов машинного обучения, а в разработке новых языков и инструментов, позволяющих формально описать задачу и гарантированно получить корректное решение. В противном случае, все эти сложные модели останутся лишь искусно замаскированными эвристиками, которые рано или поздно дадут сбой.
Оригинал статьи: https://arxiv.org/pdf/2602.02619.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Самообучающиеся агенты: новый подход к автономным системам
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Квантовые хроники: Последние новости в области квантовых исследований и разработки.
- Квантовые Загадки: От «Призрачного Действия на Расстоянии» к Суперкомпьютерам
- BOOM: Визуальный перевод лекций: новый уровень доступности
- Робот-манипулятор: обучение взаимодействию с миром с помощью зрения от первого лица
- Взлом языковых моделей: эволюция атак, а не подсказок
- Третья Разновидность ИИ: Как модели, думающие «про себя», оставят позади GPT и CoT
- Искусственный интеллект, который знает, когда ему нужна подсказка
2026-02-04 10:24