Автор: Денис Аветисян
Новый подход позволяет эффективно обучать модели при гетерогенности данных и архитектур, сохраняя конфиденциальность и снижая затраты на связь.
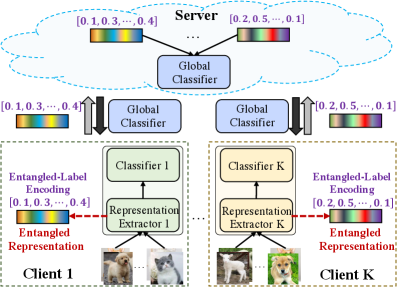
Предложена структура Federated Representation Entanglement (FedRE) для решения проблемы разнородности моделей в федеративном обучении.
Несмотря на успехи федеративного обучения в сохранении конфиденциальности данных, гетерогенность моделей и распределений данных между клиентами остается серьезной проблемой. В данной работе представлена новая структура ‘FedRE: A Representation Entanglement Framework for Model-Heterogeneous Federated Learning’, использующая концепцию запутанных представлений для эффективной агрегации знаний от разнородных клиентов. Предложенный подход позволяет достичь баланса между производительностью модели, защитой от атак инверсии представлений и снижением коммуникационных издержек. Сможет ли данная методика стать основой для создания более устойчивых и эффективных систем федеративного обучения в реальных условиях?
Вызов Распределенного Обучения: Эхо Неоднородности
Федеративное обучение, или FL, представляет собой перспективный подход к созданию моделей машинного обучения, позволяющий обучать их на децентрализованных данных, хранящихся непосредственно на устройствах пользователей, без необходимости обмена этими данными. Однако, существенной проблемой является статистическая неоднородность, когда распределения данных у разных участников (клиентов) значительно отличаются. Эта гетерогенность приводит к тому, что модель, обученная на усредненных обновлениях от всех клиентов, может демонстрировать существенно худшую производительность для тех клиентов, чьи данные существенно отличаются от общего распределения. В результате, возникает необходимость в разработке более устойчивых алгоритмов, способных эффективно учитывать различия в локальных наборах данных и поддерживать высокую точность глобальной модели, несмотря на эту статистическую неоднородность.
Традиционные алгоритмы федеративного обучения, такие как FedAvg, часто демонстрируют снижение эффективности при работе с клиентами, обладающими существенно различающимися распределениями данных. Эта проблема, известная как статистическая гетерогенность, приводит к постепенному отклонению локальных моделей от глобальной, что проявляется в виде “дрейфа” модели. В результате, глобальная модель, агрегированная из этих локальных, может демонстрировать значительно худшую производительность на данных, отличных от тех, на которых обучались отдельные клиенты. Происходит снижение обобщающей способности, поскольку модель переобучается на специфических особенностях локальных наборов данных, теряя способность к адекватной классификации или прогнозированию на новых, ранее не встречавшихся данных. Эта тенденция особенно выражена в сценариях, где данные клиентов сильно различаются по количеству, качеству и представленности различных классов или категорий.
В связи с ограничениями традиционных методов федеративного обучения, таких как FedAvg, при работе с гетерогенными данными, возникает потребность в разработке более устойчивых подходов. Исследования направлены на создание алгоритмов, способных эффективно согласовывать разнообразные локальные наборы данных, избегая отклонения модели от оптимального состояния. Новые стратегии включают в себя адаптивные механизмы взвешивания, позволяющие учитывать вклад каждого клиента с учетом особенностей его данных, а также методы нормализации и регуляризации, направленные на снижение влияния выбросов и повышение обобщающей способности глобальной модели. Акцент делается на разработку алгоритмов, которые не только обеспечивают сходимость, но и гарантируют высокую точность и стабильность обучения в условиях значительной статистической неоднородности данных, что является ключевым фактором для успешного применения федеративного обучения в реальных сценариях.
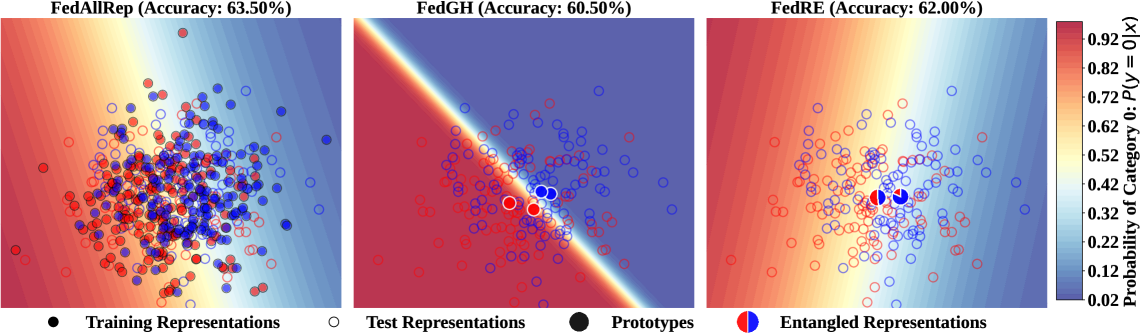
Запутанные Представления: Новый Горизонт Федеративного Обучения
В FedRE используется механизм запутанных представлений (entangled representations) для объединения локальных знаний от множества клиентов в единое межклассовое представление. Этот подход позволяет каждому клиенту генерировать признаки, отражающие его локальные данные, и затем агрегировать эти признаки с учетом вкладов других клиентов. В результате формируется общее представление, которое содержит информацию из различных источников, но при этом сохраняет вклад каждого клиента. Ключевой особенностью является не обмен полными параметрами модели, а передача этих запутанных представлений, что снижает коммуникационные издержки и повышает уровень конфиденциальности данных.
В FedRE для агрегации вкладов от различных клиентов используется механизм Representation Extractor, генерирующий признаки (features). Эти признаки комбинируются с использованием случайных или нормализованных случайных весов. Случайные веса присваиваются каждому клиенту, определяя его вклад в итоговое представление. Нормализация случайных весов обеспечивает сопоставимость масштабов признаков, полученных от разных клиентов, что способствует стабильности и эффективности процесса обучения. Итоговое представление формируется как взвешенная сумма признаков, где веса определяются указанными случайными или нормализованными случайными значениями.
В FedRE, для снижения нагрузки на канал связи и повышения конфиденциальности, вместо передачи полных параметров модели между клиентами и сервером, происходит обмен лишь «запутанными» представлениями (entangled representations). Этот подход значительно уменьшает объем передаваемых данных, поскольку представления являются сжатой формой знаний, извлеченной из локальных данных каждого клиента. Вместо обмена $n$ параметрами модели (где $n$ — общее количество параметров), клиенты передают лишь векторы признаков, сформированные Representation Extractor, что особенно важно в условиях ограниченной пропускной способности сети и повышенных требований к приватности данных пользователей. Это позволяет снизить риски, связанные с утечкой информации о локальных данных, поскольку полные параметры модели, содержащие более детальную информацию, не передаются.
Кросс-категорийное обучение, используемое в FedRE, предполагает использование информации из нескольких категорий данных для улучшения процесса обучения и обобщающей способности модели. Вместо обучения на данных только одной категории, модель получает сигналы из различных категорий, что позволяет ей выявлять более общие признаки и связи. Это особенно полезно в условиях ограниченного количества данных в каждой отдельной категории, поскольку позволяет модели использовать знания, полученные из других категорий, для улучшения производительности. В результате, модель становится более устойчивой к новым, ранее не встречавшимся данным и демонстрирует лучшую обобщающую способность на различных задачах, что повышает ее практическую ценность и надежность.

Эмпирическая Валидация: Подтверждение Эффективности
Для оценки эффективности FedRE проводились эксперименты на общедоступных наборах данных CIFAR-10, CIFAR-100 и TinyImageNet. Результаты показали устойчивое повышение точности по сравнению с базовыми алгоритмами федеративного обучения (FL) на всех трех наборах данных. В частности, наблюдалось улучшение показателей как на сбалансированных, так и на несбалансированных наборах данных, что подтверждает общую применимость FedRE в различных сценариях FL. Количественная оценка прироста производительности была проведена с использованием стандартных метрик точности, и результаты демонстрируют статистически значимое улучшение по сравнению с существующими подходами.
На гетерогенном наборе данных TinyImageNet, включающем модели с различной архитектурой, алгоритм FedRE достиг точности 6.26%. Данный результат демонстрирует превосходство над показателями, достигнутыми алгоритмами LG-FedAvg, FedGH и FedKD в аналогичных условиях. Сравнение производительности показывает, что FedRE эффективно справляется с задачами обучения в условиях высокой разнородности моделей, обеспечивая более высокую точность классификации изображений по сравнению с рассмотренными альтернативными подходами к федеративному обучению.
Использование запутанных представлений ($entangled\ representations$) в FedRE способствует более эффективной передаче знаний между участниками федеративного обучения, особенно в условиях высокой статистической неоднородности данных. Степень этой неоднородности моделируется с помощью распределения Дирихле ($Dirichlet\ Distribution$), где более высокие значения параметров указывают на большую разницу в распределениях данных между клиентами. Запутанные представления позволяют агрегировать информацию таким образом, чтобы снизить влияние этой неоднородности, обеспечивая более быструю сходимость и повышение точности модели по сравнению с традиционными методами федеративного обучения, где информация передается в виде локальных весов или градиентов.
В ходе экспериментов было установлено, что FedRE демонстрирует значительное снижение объема передаваемых данных по сравнению с алгоритмом FedAvg. В частности, снижение коммуникационной нагрузки позволяет сократить время обучения и развертывания моделей федеративного обучения. Это достигается за счет оптимизации процесса обмена информацией между клиентами и сервером, что особенно важно при работе с большим количеством участников и ограниченной пропускной способностью сети. Наблюдаемое сокращение объема передаваемых данных напрямую влияет на скорость сходимости алгоритма и позволяет более эффективно использовать ресурсы вычислительной инфраструктуры.
В ходе оценки устойчивости FedRE к атакам инверсии представлений был достигнут показатель PSNR (Peak Signal-to-Noise Ratio) в 9.66. Данный показатель свидетельствует о повышенном уровне защиты конфиденциальности по сравнению со стандартными методами, использующими непосредственно представления данных или прототипы. Более высокий PSNR указывает на меньшую искаженность восстановленных данных в результате атаки, что подтверждает эффективность предложенного подхода к защите частной информации в условиях федеративного обучения.

Перспективы и Влияние: Архитектура Будущего
Разработанный фреймворк FedRE предоставляет значительные возможности для развертывания федеративного обучения в условиях ограниченных ресурсов. Снижая затраты на коммуникацию между участниками и усиливая защиту конфиденциальных данных, он позволяет эффективно обучать модели даже на устройствах с низкой пропускной способностью сети и ограниченной вычислительной мощностью. Это открывает перспективы для применения федеративного обучения в таких областях, как мобильные устройства, интернет вещей и периферийные вычисления, где традиционные подходы оказываются непрактичными из-за высоких требований к ресурсам и вопросам конфиденциальности. Таким образом, FedRE способствует демократизации машинного обучения, делая его доступным для более широкого круга устройств и сценариев использования.
Разработанная система FedRE продемонстрировала впечатляющие результаты на стандартном наборе данных TinyImageNet, состоящем из однородных моделей. В ходе сравнительного анализа, платформа превзошла существующие базовые решения, подтвердив свою эффективность и конкурентоспособность. Полученные данные свидетельствуют о том, что предложенный подход к федеративному обучению не только снижает коммуникационные издержки и повышает конфиденциальность, но и обеспечивает высокую точность модели даже в условиях ограниченных ресурсов, открывая перспективы для широкого применения в различных задачах машинного обучения.
Разработанная платформа FedRE обладает значительным потенциалом для масштабирования и адаптации к более сложным задачам машинного обучения. В то время как текущая реализация демонстрирует эффективность на наборе данных TinyImageNet, архитектура позволяет интегрировать различные типы данных, включая изображения высокой четкости, аудиосигналы и текстовые данные. Кроме того, платформа не ограничивается определенными моделями; ее можно адаптировать для работы с глубокими нейронными сетями различной сложности, трансформерами и другими современными архитектурами. Это расширение функциональности открывает возможности для применения FedRE в широком спектре областей, таких как медицинская диагностика, обработка естественного языка и компьютерное зрение, что делает ее универсальным инструментом для децентрализованного обучения с сохранением конфиденциальности.
Дальнейшие исследования будут направлены на разработку адаптивных стратегий взвешивания, позволяющих динамически регулировать вклад отдельных моделей в процессе федеративного обучения. Особое внимание уделяется изучению теоретических свойств запутанных представлений — концепции, предполагающей, что информация от различных участников может быть объединена таким образом, чтобы максимизировать эффективность обучения и минимизировать потерю информации. Понимание этих свойств позволит создать более устойчивые и эффективные алгоритмы, способные адаптироваться к гетерогенности данных и вычислительных ресурсов, а также обеспечить оптимальное использование пропускной способности сети. Предполагается, что применение более тонких механизмов взвешивания и глубокий анализ структуры запутанных представлений значительно улучшат сходимость и обобщающую способность федеративных моделей, открывая новые возможности для их применения в различных областях, включая обработку изображений, анализ текста и прогнозирование временных рядов.
Разработка FedRE вносит значительный вклад в развитие ответственного и масштабируемого машинного обучения, обеспечивая более эффективное взаимодействие между участниками процесса обучения и одновременно гарантируя защиту конфиденциальности данных. Данная система позволяет преодолеть традиционные компромиссы между точностью модели, скоростью обучения и уровнем приватности, что особенно важно в контексте все более строгих нормативных требований и растущего общественного внимания к вопросам защиты персональных данных. Благодаря акценту на совместной работе и конфиденциальности, FedRE открывает новые возможности для применения машинного обучения в чувствительных областях, таких как здравоохранение и финансы, где обеспечение безопасности данных является первостепенной задачей. Таким образом, данная разработка не только улучшает технические характеристики федеративного обучения, но и способствует созданию более надежных и этичных систем искусственного интеллекта.

Предложенный в работе подход FedRE к федеративному обучению демонстрирует понимание систем как развивающихся экосистем, а не статичных конструкций. Создание запутанных представлений для преодоления неоднородности моделей и данных напоминает работу садовника, который прививает различные сорта, чтобы создать более устойчивый сад. Как заметил Кен Томпсон: «В конечном итоге, самая большая проблема в программировании — это сложность. Чем сложнее система, тем труднее в ней разобраться и тем выше вероятность ошибок.» Именно поэтому стремление к балансу между производительностью, конфиденциальностью и коммуникационной эффективностью, как это реализовано в FedRE, является не просто техническим решением, а признанием органической природы систем, требующих постоянного внимания и адаптации к изменяющимся условиям.
Что дальше?
Предложенный в данной работе каркас FedRE, безусловно, представляет собой шаг к обузданию разнородности в федеративном обучении. Однако, каждая успешная интеграция представлений — это лишь отсрочка неизбежного. Вместо того, чтобы стремиться к идеальному представлению, возможно, стоит признать, что каждая модель, каждый участник, несет в себе зерно несоответствия, которое и является источником устойчивости системы в целом. Попытки «выровнять» все лишь создают новые, более хрупкие точки отказа.
Ключевым вопросом остается не столько оптимизация обмена информацией, сколько понимание пределов его необходимости. Каждый деплой — маленький апокалипсис, обнажающий новые векторы атак и утечек. Представления, как и любая другая форма знания, подвержены инверсии. Бесполезно строить стены, если не понимаешь, как работает подкоп. Поиск баланса между приватностью и коммуникационной эффективностью — это вечное хождение по лезвию бритвы, а документация о том, где именно это лезвие находится, пишется редко.
Будущие исследования, вероятно, столкнутся с необходимостью переосмысления самой концепции «общей модели». Возможно, более перспективным путем является развитие методов, позволяющих моделям сосуществовать в состоянии контролируемого хаоса, обмениваясь не представлениями, а лишь сигналами о своей текущей неустойчивости. Иначе говоря, вместо строительства единой экосистемы, необходимо научиться выращивать множество маленьких, устойчивых к сбоям.
Оригинал статьи: https://arxiv.org/pdf/2511.22265.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
2025-12-01 18:29