Автор: Денис Аветисян
Исследователи разработали семейство моделей искусственного интеллекта, способных решать сложные физические задачи, требующие как визуального восприятия, так и логического мышления.
P1-VL: открытая платформа для мультимодального обучения, сочетающая в себе обучение с подкреплением и агентное расширение для достижения передовых результатов в решении задач физических олимпиад.
Переход от символьных манипуляций к полноценному естественнонаучному мышлению остается сложной задачей для больших языковых моделей (LLM). В настоящей работе, посвященной ‘P1-VL: Bridging Visual Perception and Scientific Reasoning in Physics Olympiads’, представлена новая архитектура, объединяющая визуальное восприятие и логические рассуждения для решения олимпиадных задач по физике. Мы демонстрируем, что семейство моделей P1-VL, основанное на обучении с подкреплением и агентном дополнении, достигает передовых результатов на бенчмарке HiPhO, обеспечивая 12 золотых медалей и превосходя другие открытые модели. Не откроет ли это путь к созданию систем искусственного интеллекта, способных к полноценному научному открытию и глубокому пониманию физических законов?
Преодолевая Границы Текстового Понимания: Вызов Рассуждений
Несмотря на впечатляющую способность больших языковых моделей обрабатывать текст, подлинное рассуждение, особенно в задачах, требующих нескольких последовательных шагов, остаётся серьёзным препятствием. Эти модели демонстрируют мастерство в распознавании закономерностей и генерации связных текстов, однако часто не способны к логическому выводу, требующему анализа условий, выстраивания последовательности действий и предвидения последствий. Проблема заключается не в отсутствии информации, а в неспособности эффективно использовать её для решения сложных, многоступенчатых проблем, где требуется не просто вспомнить или перефразировать данные, а применить их для достижения конкретной цели. Это особенно заметно в задачах, где требуется абстрактное мышление и способность к построению гипотез, что выходит за рамки простого сопоставления текстовых фрагментов.
Традиционные методы анализа данных часто сталкиваются с трудностями при одновременной обработке визуальной и текстовой информации, что существенно ограничивает их способность к комплексному решению проблем. Вместо того, чтобы интегрировать эти два типа данных в единую систему, многие подходы рассматривают их раздельно, что препятствует выявлению скрытых взаимосвязей и формированию целостной картины. Например, при анализе графиков или диаграмм, система может распознать отдельные элементы, но не сможет установить связь между ними и соответствующим текстовым описанием, лишаясь возможности делать обоснованные выводы. Эта проблема особенно актуальна в областях, где визуальное представление данных играет ключевую роль, таких как научные исследования, технический анализ или диагностика, где способность к интеграции различных типов информации является критически важной для принятия эффективных решений.
Особенно остро данная неспособность проявляется в областях, требующих одновременного анализа текста и визуальной информации, таких как физика и олимпиады по естественным наукам. Участники этих соревнований часто сталкиваются с задачами, где необходимо не только понять словесное условие, но и интерпретировать графики, диаграммы или изображения, чтобы найти решение. Традиционные методы обработки языка, ориентированные преимущественно на текстовые данные, испытывают трудности при интеграции визуальной информации, что существенно ограничивает их возможности в решении комплексных задач, требующих целостного подхода. Неспособность к эффективному сочетанию текстового и визуального анализа становится критическим фактором, определяющим успех в данных дисциплинах, и подчеркивает необходимость разработки новых подходов к искусственному интеллекту, способных к более глубокому и комплексному пониманию окружающего мира.
Агентное Расширение: Многоагентная Система для Улучшенных Рассуждений
Предлагаемый подход, агентное расширение возможностей, основан на использовании многоагентной системы для решения сложных задач, имитирующей совместное решение проблем человеком. Вместо централизованного подхода, система состоит из нескольких взаимодействующих агентов, каждый из которых может специализироваться на определенном аспекте задачи или применять различные стратегии. Коллективное взаимодействие этих агентов позволяет декомпозировать сложные проблемы на более мелкие, управляемые части, а также агрегировать и оценивать различные решения для достижения более надежного и точного результата. Такая архитектура повышает устойчивость к ошибкам и позволяет эффективно использовать вычислительные ресурсы, распределяя нагрузку между агентами.
Система опирается на большие языковые модели, такие как P1-VL-235B-A22B и P1-VL-30B-A3B, для комплексного анализа данных. Эти модели способны обрабатывать и интегрировать как текстовую, так и визуальную информацию, что позволяет им учитывать различные типы входных данных и выявлять взаимосвязи, которые могли бы быть упущены при использовании только одного типа информации. Интеграция визуальных данных, в частности, расширяет возможности системы в задачах, требующих понимания контекста и распознавания объектов, что значительно повышает точность и надежность получаемых результатов.
В основе предлагаемого подхода лежит система PhysicsMinions, представляющая собой коэволюционную архитектуру, структурирующую процесс решения задач посредством трех ключевых модулей: восприятия, логического вывода и проверки. Данная система обеспечивает надежность и устойчивость получаемых решений за счет непрерывной совместной эволюции этих модулей. Модуль восприятия отвечает за обработку входных данных, модуль логического вывода — за построение цепочки рассуждений, а модуль проверки — за оценку и валидацию полученных результатов. Взаимодействие и коэволюция этих компонентов позволяют PhysicsMinions адаптироваться к различным задачам и обеспечивать более точные и надежные решения по сравнению с традиционными подходами.
Подтверждение Способности к Рассуждениям: HiPhO и За Его Пределами
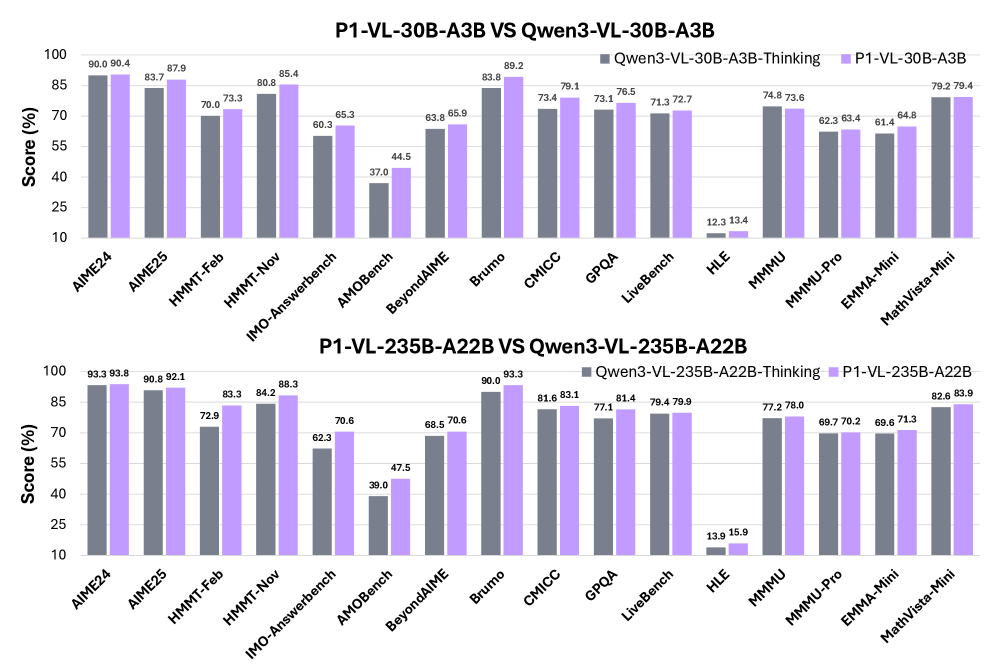
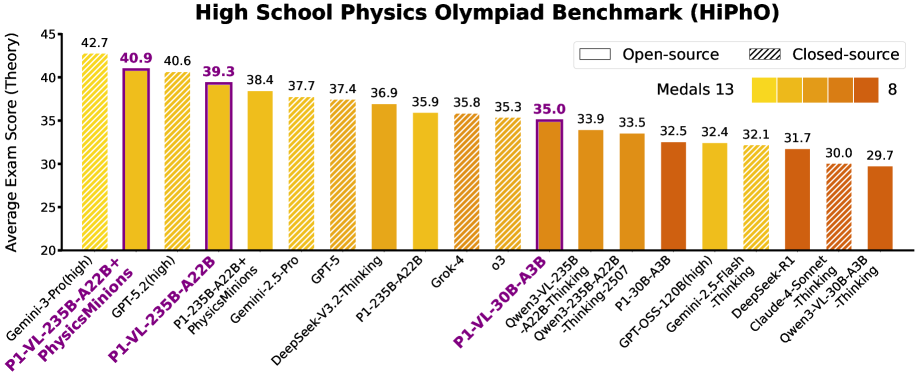
Модели P1-VL-235B-A22B и P1-VL-30B-A3B продемонстрировали передовые результаты на HiPhO, эталонном наборе данных, состоящем из задач физических олимпиад. Этот набор данных используется для оценки способности моделей решать сложные, требующие логического мышления задачи в области физики. Результаты на HiPhO служат показателем способности моделей к решению проблем, требующих не только знания фактов, но и применения физических принципов для анализа и получения решений. Использование HiPhO в качестве критерия оценки позволяет сопоставить производительность моделей с уровнем, достигнутым участниками олимпиад по физике.
Модель P1-VL-235B-A22B продемонстрировала средний балл в 39.3 на бенчмарке HiPhO, представляющем собой набор задач физических олимпиад. Этот результат превосходит показатели моделей Gemini-2.5-Pro (37.7) и GPT-5 (37.4). Примечательно, что P1-VL-235B-A22B значительно опережает свою базовую модель Qwen3-VL-235B-A22B-Thinking, которая показала средний балл 33.9 на том же бенчмарке HiPhO.
Дополнительная валидация производительности моделей P1-VL-235B-A22B и P1-VL-30B-A3B была проведена на наборе данных FrontierScience-Olympiad. Результаты показали улучшение показателей на 8.0 для модели P1-VL-235B-A22B и на 9.1 для модели P1-VL-30B-A3B, что подтверждает их высокую эффективность в решении сложных задач, аналогичных олимпиадным.
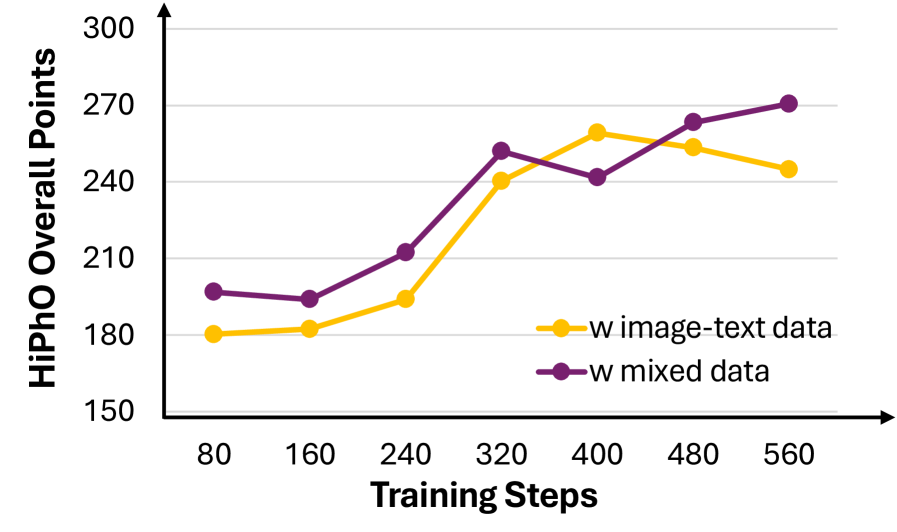
Для обучения моделей P1-VL-235B-A22B и P1-VL-30B-A3B использовалось обучение с подкреплением на основе учебного плана (Curriculum Reinforcement Learning). Данный подход предполагает последовательное увеличение сложности решаемых задач в процессе тренировки. Это позволяет оптимизировать процесс обучения, повышая устойчивость моделей к различным типам задач и улучшая общую производительность, особенно в сложных областях, таких как олимпиады по физике. Постепенное увеличение сложности способствует более эффективному усвоению материала и предотвращает перегрузку модели на начальных этапах обучения.
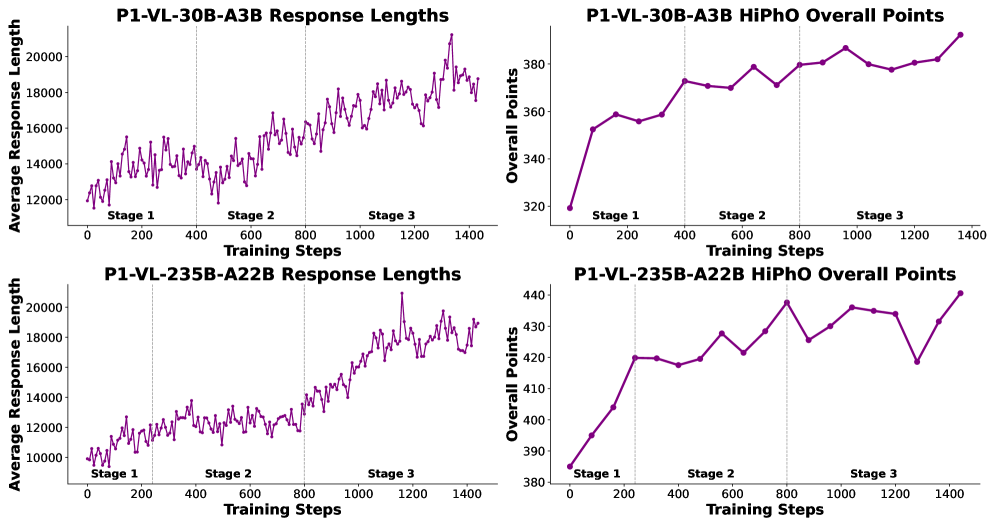
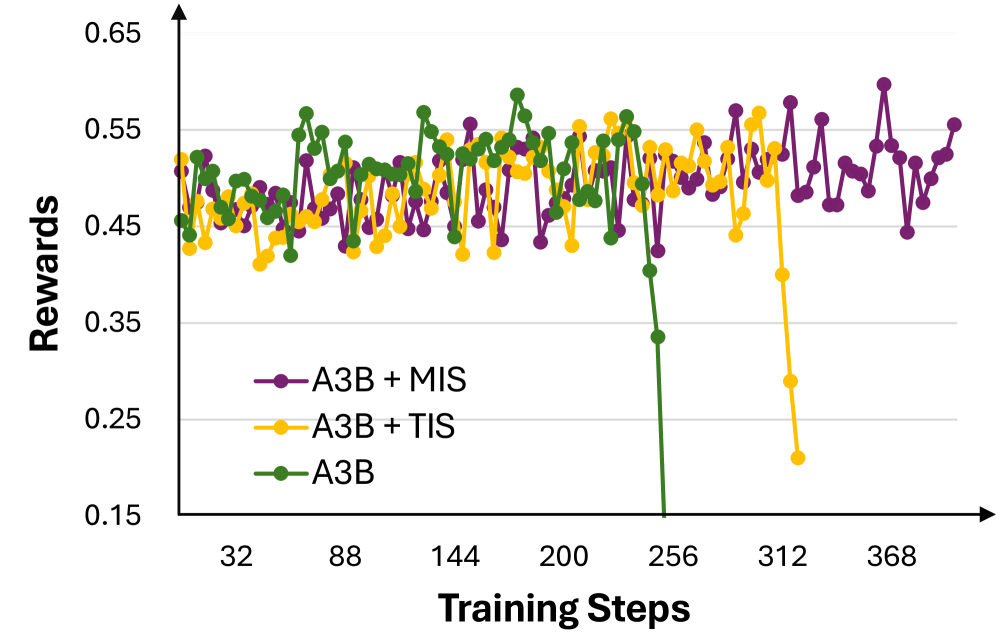
Стабилизация Обучения с Подкреплением: Преодоление Разрыва Между Обучением и Инференсом
Существенной проблемой при применении обучения с подкреплением по учебному плану является несоответствие между условиями обучения и развертывания (Training-Inference Mismatch). Это несоответствие возникает из-за различий в распределении состояний и действий между средой, используемой во время обучения, и средой, в которой модель применяется на практике. В результате, политика, обученная в контролируемой среде, может демонстрировать нестабильное поведение и снижение производительности при развертывании в реальных условиях, где распределение данных может существенно отличаться от обучающего. Это особенно критично для систем, требующих высокой надежности и предсказуемости.
Для стабилизации обучения с подкреплением и снижения влияния расхождения между этапами обучения и применения, используется метод маскированной оценки важности (Masked Importance Sampling). Данная техника позволяет смягчить последствия этого расхождения путем взвешивания траекторий обучения на основе вероятности их появления в процессе применения. Маскирование ограничивает вес траекторий, выходящих за рамки допустимых действий в процессе применения, что предотвращает переобучение на нереалистичных сценариях и способствует более надежной и консистентной работе модели в реальных условиях. P(a|s) — вероятность действия a в состоянии s.
Обеспечение высокой производительности моделей в процессе обучения само по себе недостаточно для надежного функционирования в реальных условиях. Стабильность и согласованность работы в практических приложениях достигаются за счет минимизации расхождений между данными, используемыми для обучения, и данными, поступающими в процессе эксплуатации. Это требует применения методов, гарантирующих, что модель сохраняет свою эффективность при изменении входных данных и не демонстрирует непредсказуемого поведения, что критически важно для систем, работающих в динамичной среде и требующих высокой степени надежности и предсказуемости.
К Общей Интеллектуальной Системе: Последствия и Перспективы
Успешное применение подхода агентного усиления демонстрирует значительный потенциал многоагентных систем в повышении способности к рассуждению в сложных областях. Исследование показало, что распределение когнитивной нагрузки между несколькими взаимодействующими агентами позволяет решать задачи, непосильные для отдельных моделей. Вместо того, чтобы полагаться на единый, всеобъемлющий алгоритм, система, состоящая из специализированных агентов, способных к совместной работе и обмену информацией, демонстрирует повышенную эффективность и гибкость. Этот подход открывает путь к созданию искусственного интеллекта, способного не только решать конкретные задачи, но и адаптироваться к новым условиям и находить инновационные решения в широком спектре областей, приближая нас к созданию действительно общего искусственного интеллекта.
Открытые модели, такие как P1-VL-235B-A22B и P1-VL-30B-A3B, представляют собой ценную основу для дальнейших исследований и разработок в области искусственного интеллекта. В отличие от закрытых систем, эти модели позволяют широкому кругу специалистов и энтузиастов не только изучать их внутреннюю работу, но и адаптировать их под конкретные задачи, а также вносить улучшения и дополнения. Такая открытость способствует развитию коллективного интеллекта и значительно ускоряет темпы инноваций, поскольку позволяет избежать дублирования усилий и использовать накопленный опыт всего сообщества. Благодаря доступности и возможности модификации, эти модели становятся ключевым инструментом для расширения границ возможного в сфере ИИ и создания более мощных и универсальных систем.
В рамках исследования, агентская система PhysicsMinions, использующая модель P1-VL-235B-A22B, продемонстрировала впечатляющие результаты в решении задач HiPhO, достигнув среднего балла в 40.9. Этот показатель превзошел результат, показанный моделью GPT-5.2 (40.6), что позволило P1-VL-235B-A22B занять второе место в общем зачете. Достигнутый успех подтверждает эффективность подхода, основанного на создании агентов, и указывает на потенциал открытых моделей в решении сложных научных задач, требующих глубокого понимания физических принципов и логического мышления.
Данное исследование открывает перспективы для создания более универсальных и устойчивых систем искусственного интеллекта, способных решать широкий спектр сложных задач. Преодолевая ограничения, присущие моделям с закрытым исходным кодом, разработанный подход демонстрирует потенциал для построения ИИ, адаптирующегося к новым вызовам и обогащающегося за счет коллективных усилий научного сообщества. Возможность расширения и модификации открытых моделей, таких как P1-VL, позволяет создавать решения, которые не только эффективны в текущий момент, но и способны к дальнейшему развитию и совершенствованию, обеспечивая долгосрочный прогресс в области искусственного интеллекта и его применений.
Представленная работа демонстрирует стремление к созданию систем, способных не просто «работать» на тестовых примерах, но и демонстрировать глубокое понимание физических принципов. Как однажды заметил Джон Маккарти: «Искусственный интеллект — это не создание машин, которые мыслят как люди, а создание машин, которые мыслят». P1-VL, используя комбинацию обучения с подкреплением и мультимодального восприятия, стремится к построению алгоритмов, способных к масштабируемому решению задач олимпиадного уровня. Этот подход подчёркивает важность не только успешного прохождения тестов, но и внутренней логики и доказуемости алгоритма, что соответствует принципам элегантности и математической чистоты кода.
Куда Далее?
Представленные модели P1-VL, безусловно, демонстрируют впечатляющую способность к решению олимпиадных задач по физике, однако важно помнить о фундаментальной природе проблемы. Успех, достигнутый за счет обучения с подкреплением и многомодального восприятия, не является доказательством истинного “понимания” физических принципов. Скорее, это изящное, но все же приближение к решению, основанное на статистических закономерностях, выявленных в обучающих данных. Эвристики, лежащие в основе алгоритмов агентного дополнения, остаются компромиссом между точностью и вычислительной сложностью.
Будущие исследования должны быть сосредоточены на создании моделей, способных к более глубокому логическому выводу, а не просто к распознаванию паттернов. Необходимо разработать методы, позволяющие верифицировать корректность решений, а не только оценивать их результативность на тестовых примерах. Особенно интересным представляется направление, связанное с интеграцией символьных вычислений и нейронных сетей, позволяющее создавать системы, сочетающие в себе гибкость и адаптивность последних с дедуктивной строгостью первых.
В конечном счете, задача состоит не в том, чтобы создать машину, способную решать олимпиадные задачи, а в том, чтобы понять, что на самом деле означает “понимание” в контексте научного мышления. Именно эта философская дилемма, а не просто достижение новых рекордов производительности, должна определять направление будущих исследований.
Оригинал статьи: https://arxiv.org/pdf/2602.09443.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Внимание в сети: Новый подход к ускорению больших языковых моделей
- Химический синтез под контролем искусственного интеллекта: новые горизонты
- Внимание на границе: почему трансформеры нуждаются в «поглотителях»
- Искусственный нос будущего: как квантовая механика и машинное обучение распознают запахи
- S-Chain: Когда «цепочка рассуждений» в медицине ведёт к техдолгу.
- Язык тела под присмотром ИИ: архитектура и гарантии
- Квантовый дозор: Новая система обнаружения аномалий для умных сетей
- Видео-Мыслитель: гармония разума и визуального потока.
- Генетическая приоритизация: новый взгляд на отбор генов
- Границы Разума: Управление Саморазвивающимися ИИ
2026-02-12 00:13