Автор: Денис Аветисян
Новая инициатива французского правительства предоставляет уникальный ресурс для сбора данных о предпочтениях пользователей при работе с моделями генерации текста на французском языке.
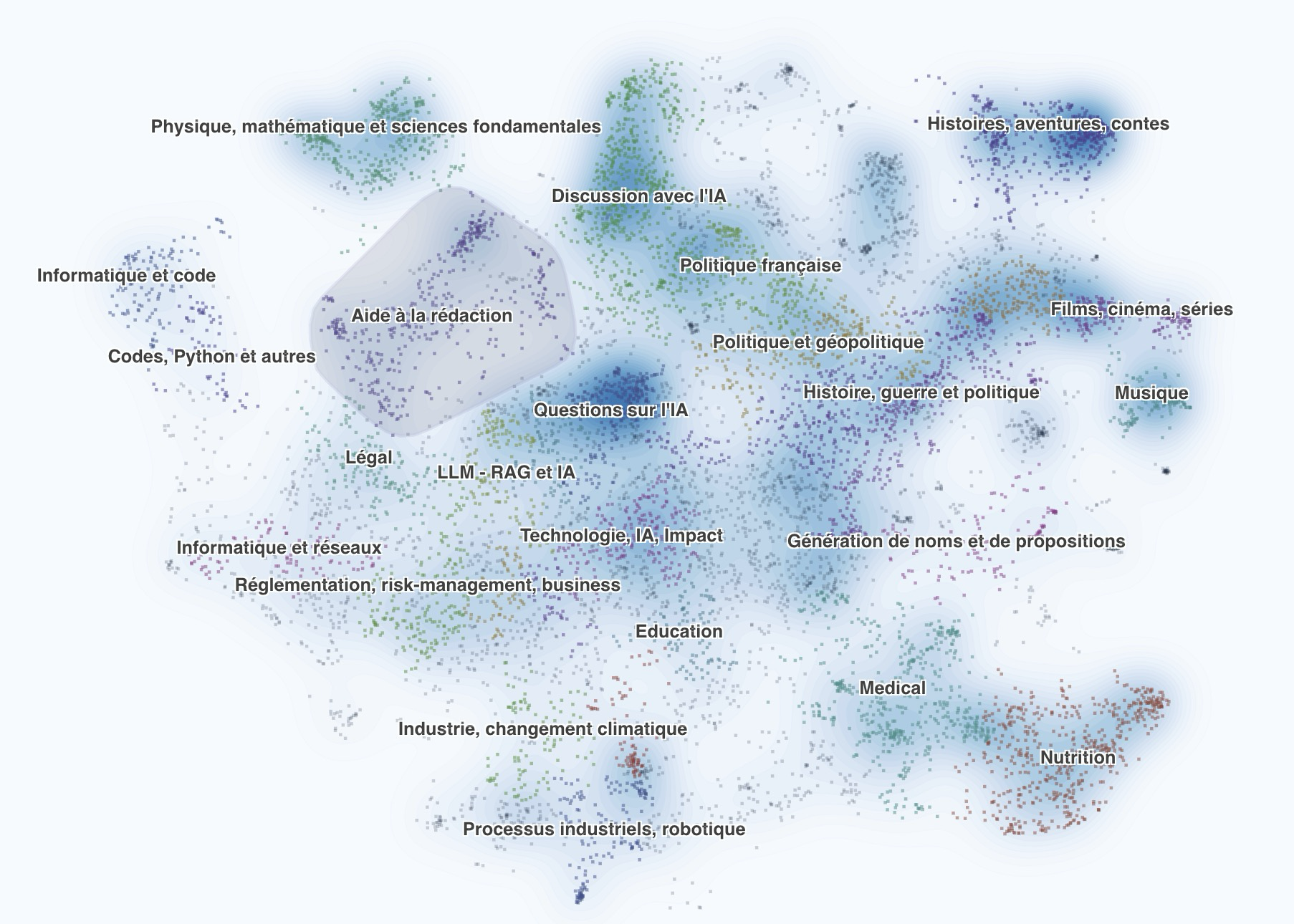
Платформа compar:IA собирает данные о предпочтениях пользователей посредством слепых парных сравнений, способствуя развитию и оценке многоязычных ИИ-систем с открытым исходным кодом.
Несмотря на значительные успехи в области больших языковых моделей (LLM), их производительность и культурная адаптация зачастую снижаются при работе с языками, отличными от английского. В данной работе представлена платформа ‘compar:IA: The French Government’s LLM arena to collect French-language human prompts and preference data’ — цифровой общественный сервис, разработанный правительством Франции для сбора масштабных данных о предпочтениях пользователей на французском языке. Платформа использует метод слепого парного сравнения для получения непредвзятых запросов и оценок, предоставляя ценный открытый ресурс для обучения и оценки многоязычных моделей. Каким образом полученные данные могут способствовать развитию более инклюзивного и эффективного искусственного интеллекта, учитывающего лингвистическое разнообразие?
Неизбежный Разрыв: Оценка LLM за Пределами Английского
Несмотря на стремительное развитие больших языковых моделей (LLM), надежных и общедоступных критериев оценки, особенно для языков, отличных от английского, ощущается явный недостаток. В то время как новые модели появляются практически ежедневно, объективно измерить их производительность и точность в обработке, например, французского языка, представляется сложной задачей. Существующие методы оценки часто оказываются недостаточно масштабными и прозрачными, что затрудняет проведение достоверных сравнений и целенаправленное улучшение моделей. Этот пробел в инфраструктуре оценки замедляет прогресс в адаптации LLM к специфическим лингвистическим особенностям и культурным нюансам различных языков, лишая их возможности полностью раскрыть свой потенциал за пределами англоязычного пространства.
Существующие методы оценки больших языковых моделей (LLM) часто страдают от недостаточной масштабируемости и прозрачности, что существенно затрудняет проведение достоверных сравнений и целенаправленное улучшение их характеристик. В частности, многие текущие подходы требуют значительных вычислительных ресурсов и ручного труда для проведения оценок, что ограничивает возможность их повторения и расширения. Недостаток прозрачности в процессах оценки, таких как выбор данных для тестирования и метрики, используемые для измерения производительности, не позволяет четко определить сильные и слабые стороны различных моделей. Это, в свою очередь, препятствует разработке более эффективных и специализированных LLM, адаптированных к конкретным лингвистическим особенностям и культурным контекстам, подобно французскому языку, и замедляет прогресс в данной области.
Отсутствие адекватной оценочной инфраструктуры существенно замедляет прогресс в адаптации больших языковых моделей к специфике французского языка и культуры. В то время как модели демонстрируют впечатляющие возможности в обработке английского, их производительность в других языках, включая французский, зачастую не соответствует ожиданиям из-за недостаточной калибровки на специфических лингвистических особенностях и культурных нюансах. Это проявляется в неточностях при работе с идиомами, фразеологизмами, а также в непонимании контекстуальных особенностей французской речи. Разработка специализированных бенчмарков и оценочных метрик, учитывающих эти факторы, является ключевым условием для создания языковых моделей, способных эффективно функционировать и понимать французский язык во всей его сложности и богатстве.
compar:IA: Арена для Французского Языка
Платформа compar:IA представляет собой публичную арену для больших языковых моделей (LLM), предназначенную для систематического сбора оценок пользователей относительно качества генерируемого текста. Особенностью данной платформы является специализация на французском языке, что позволяет создавать и оценивать модели, оптимизированные для обработки и генерации текста на этом языке. Сбор предпочтений осуществляется посредством взаимодействия пользователей с различными LLM и выражения их оценок относительно результатов, что формирует данные для дальнейшего обучения и улучшения моделей.
Платформа compar:IA использует методологию слепого попарного сравнения (Blind Pairwise Comparison) для сбора оценок. В рамках данной методологии пользователям последовательно представляются ответы двух языковых моделей на один и тот же запрос, без указания, какая модель какой ответ сгенерировала. Пользователи выбирают предпочтительный ответ, что позволяет избежать предвзятости, связанной с известностью или репутацией конкретной модели. Принцип работы аналогичен методологии, применяемой в LMSYS Chatbot Arena, и обеспечивает масштабируемость сбора данных благодаря простоте оценки и возможности привлечения большого числа участников.
По состоянию на 7 февраля 2026 года платформа compar:IA собрала более 600 000 текстовых запросов, введенных пользователями, и 250 000 оценок предпочтений. Эти данные представляют собой значительный объем информации, полученной посредством взаимодействия пользователей с различными моделями генерации текста. Объем собранных запросов позволяет проводить статистически значимые исследования, а количество оценок предпочтений обеспечивает надежную основу для обучения и оценки языковых моделей, особенно в контексте французского языка.
Архитектура платформы compar:IA построена на основе FastAPI и SvelteKit, что обеспечивает высокую эффективность сбора данных и взаимодействия с пользователями. FastAPI, как современный высокопроизводительный фреймворк для Python, отвечает за обработку запросов и логику бэкенда, позволяя быстро обрабатывать большое количество взаимодействий пользователей. SvelteKit, используемый для фронтенда, обеспечивает динамичный и отзывчивый пользовательский интерфейс, оптимизированный для быстродействия и минимального размера передаваемых данных. Данная комбинация технологий позволяет платформе эффективно собирать предпочтения пользователей, обеспечивая масштабируемость и надежность системы для обработки сотен тысяч промптов и оценок.
Сбор данных о предпочтениях пользователей, осуществляемый посредством платформы compar:IA, формирует ценный набор данных Preference Votes, критически важный для обучения и оценки больших языковых моделей (LLM). Данный набор данных содержит информацию о том, какой из двух предложенных LLM ответов предпочтителен для конкретного запроса, что позволяет количественно оценить качество генерации текста. Объем собранных данных, превышающий 250,000 голосов на февраль 7, 2026 года, обеспечивает статистическую значимость оценок и позволяет обучать модели ранжированию ответов в соответствии с человеческими предпочтениями. Использование Preference Votes в качестве сигнала обучения позволяет LLM оптимизироваться не только по метрикам правдоподобия, но и по степени соответствия ожиданиям пользователей, что является ключевым фактором для создания полезных и эффективных моделей.
Статистика Превыше Всего: От Голосов к Лидерству
В основе нашей системы оценки лежит модель Брэдли-Терри, статистический метод, преобразующий необработанные данные о предпочтениях в ранжированный список больших языковых моделей (LLM). Данная модель использует парные сравнения для определения относительной производительности каждой LLM, оценивая вероятность того, что один LLM будет предпочтен другому. Результатом является шкала, позволяющая объективно сопоставить различные модели и определить их позиции в рейтинге, основываясь на статистической значимости выявленных предпочтений. P(i > j) = \frac{e^{\beta \theta_i}}{e^{\beta \theta_i} + e^{\beta \theta_j}} — формула, описывающая вероятность предпочтения модели i над моделью j, где \theta_i — параметр, характеризующий качество модели i, а β — параметр масштаба.
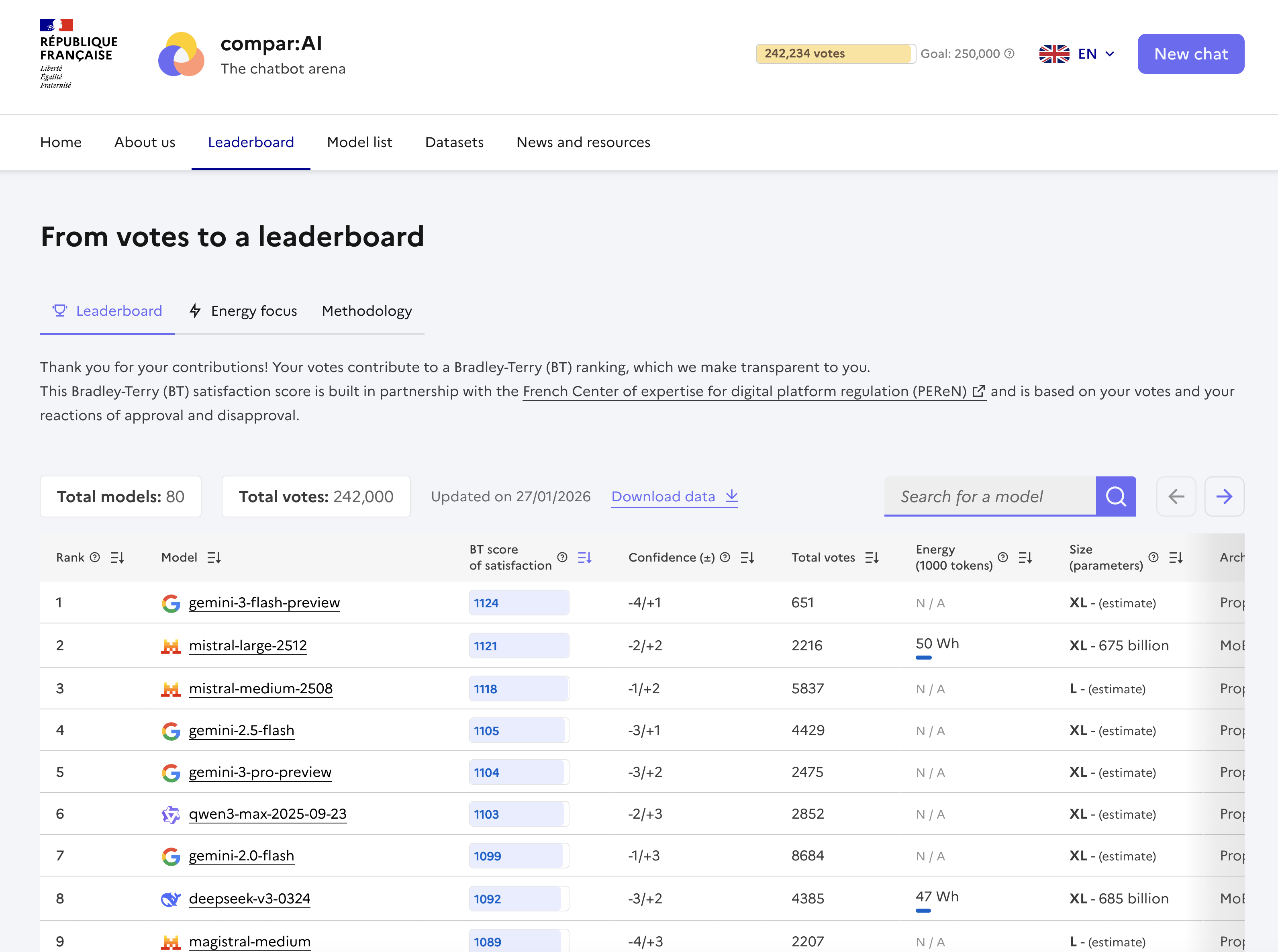
В основе оценки производительности моделей лежит обработка 250 000 голосов, полученных посредством платформы compar:IA. Данные голоса представляют собой результаты сравнения моделей пользователями, и модель Брэдли-Терри используется для количественной оценки относительной производительности каждой модели. Каждый голос фиксирует предпочтение пользователя между двумя моделями для конкретного запроса, и эти данные агрегируются для вычисления оценок, отражающих вероятность того, что одна модель будет предпочтена другой. В результате анализа предпочтений формируется ранжированный список моделей, позволяющий объективно сопоставить их сильные и слабые стороны.
Набор данных, используемый для оценки языковых моделей, характеризуется значительным преобладанием запросов на французском языке. Из общего объема собранных данных 89.14% составляют промпты, сформулированные на французском языке. Данное распределение отражает стратегический выбор, направленный на оценку производительности моделей в обработке и генерации текста на конкретном языке, и необходимо учитывать при интерпретации результатов ранжирования и сравнения моделей.
Собранные данные о предпочтениях пользователей, включающие 250 000 оценок, не ограничиваются прямой оценкой моделей. Они служат основой для передовых методов обучения, таких как Direct Preference Optimization (DPO) и Reinforcement Learning from Human Feedback (RLHF). DPO позволяет напрямую оптимизировать языковые модели на основе предпочтений пользователей, минимизируя расхождения между предсказанными и предпочтительными ответами. RLHF, в свою очередь, использует эти предпочтения в качестве сигнала вознаграждения для обучения моделей с подкреплением, улучшая их способность генерировать ответы, соответствующие ожиданиям пользователей. Использование данных предпочтений в этих методах позволяет создавать более эффективные и ориентированные на пользователя языковые модели.
Для обеспечения доступности данных и воспроизводимости результатов, полные данные диалогов (Conversation Data) и полученные оценки моделей опубликованы под лицензией Etalab 2.0. Эта лицензия открытого исходного кода позволяет свободно использовать, распространять и модифицировать данные для исследовательских и других целей, при условии указания авторства и сохранения условий лицензии. Публикация данных под открытой лицензией способствует прозрачности оценочного процесса и позволяет другим исследователям проверять и расширять наши результаты, а также использовать данные для разработки и улучшения языковых моделей.
Эффект и Перспективы: К Открытой и Устойчивой Оценке LLM
Платформа compar:IA получила признание со стороны Digital Public Goods Alliance, что подтверждает её приверженность принципам открытого доступа и общественной пользы. Данное признание является важным свидетельством того, что разработка и распространение платформы соответствуют высоким стандартам цифровых общественных благ, способствующих развитию инклюзивного и устойчивого искусственного интеллекта. Подчеркивая важность открытости и прозрачности, compar:IA стремится предоставить исследователям и разработчикам инструменты для оценки больших языковых моделей, способствуя тем самым более ответственному и полезному применению этих технологий в различных сферах.
Платформа обеспечивает широкую доступность своих наборов данных для исследователей и разработчиков, распространяя их через популярные ресурсы Hugging Face и data.gouv.fr. Этот подход гарантирует, что ценные ресурсы для оценки больших языковых моделей будут доступны широкому кругу специалистов, способствуя дальнейшему развитию и инновациям в области искусственного интеллекта. По состоянию на текущий момент, запросы на доступ к набору данных, размещенному на Hugging Face, составили 778 уникальных пользователей, что свидетельствует о значительном интересе и востребованности платформы в научном сообществе.
В настоящее время ведется активное исследование методов оценки энергопотребления при работе языковых моделей, используя платформу Ecologits. Данный подход направлен на продвижение принципов устойчивого развития в области искусственного интеллекта. Исследователи стремятся к созданию инструментов, позволяющих измерять и оптимизировать расход энергии, необходимой для выполнения задач, таких как генерация текста или ответы на вопросы. Такой анализ позволит не только снизить экологическую нагрузку от использования больших языковых моделей, но и способствовать разработке более эффективных и экономичных алгоритмов, что особенно важно в контексте растущей вычислительной мощности, необходимой для обучения и функционирования этих систем.
К февралю 7, 2026 года платформа привлекла свыше 300 000 уникальных посетителей, что свидетельствует о растущем интересе к объективной оценке больших языковых моделей. Этот значительный трафик указывает на то, что сообщество исследователей и разработчиков активно использует ресурсы платформы для анализа и совершенствования ИИ-систем. Такой масштабный охват позволяет получать разнообразные данные и формировать более полное представление о возможностях и ограничениях различных моделей, способствуя развитию более надежных и полезных инструментов искусственного интеллекта. Данный показатель подтверждает важность создания открытых и доступных площадок для оценки ИИ, позволяющих обеспечить прозрачность и стимулировать инновации в этой быстро развивающейся области.
В будущем планируется значительное расширение возможностей платформы за счет внедрения реакции на уровне отдельных сообщений. Такой подход позволит получать более детальную и точную обратную связь о качестве ответов языковых моделей, выходя за рамки общей оценки. Параллельно ведется работа по расширению охвата оценки на другие, недостаточно представленные языки, что позволит обеспечить более справедливую и инклюзивную оценку производительности моделей для глобального сообщества пользователей. Это позволит не только улучшить качество существующих моделей, но и стимулировать развитие технологий обработки естественного языка для более широкого круга языков и культур.
Наблюдатель отмечает, что инициатива compar:IA, представляющая собой арену для сбора данных о предпочтениях пользователей на французском языке, неизбежно столкнется с суровой реальностью продакшена. Ведь любая, даже самая тщательно спроектированная система, в конечном итоге будет подвержена сбоям и несоответствиям. Как заметила Ада Лавлейс: «Я уверена, что этот вычислительный механизм может выполнять любую операцию, которую мы можем предписать ему сделать». Однако, даже если механизм и способен выполнять предписанное, это не гарантирует его безошибочной работы в реальных условиях. Сбор данных о предпочтениях — лишь первый шаг, а вот обеспечение их достоверности и устойчивости к внешним факторам — задача куда более сложная. И, как это часто бывает, элегантная теория столкнется с необходимостью адаптации к суровой практике.
Что дальше?
Инициатива compar:IA, безусловно, добавляет ещё один слой к сложной картине оценки больших языковых моделей. Сбор данных о предпочтениях на французском языке — шаг полезный, хотя и неизбежно обречённый на устаревание. Ведь пока энтузиасты аккуратно собирают данные о «предпочтительном» ответе, продакшен уже генерирует новую порцию ошибок, требующих новой разметки. Этот цикл знаком — «революция» сегодня, технический долг завтра.
Вопрос не в количестве данных, а в их применимости. Собранные предпочтения — лишь снимок текущего состояния языка и ожиданий пользователей. По мере развития моделей и изменения запросов, ценность этих данных будет постепенно снижаться. Интересно, будет ли кто-то отслеживать «срок годности» этих предпочтений, или они превратятся в ещё один архив «воспоминаний о лучших временах»?
В конечном счёте, настоящая проблема не в оптимизации моделей под существующие предпочтения, а в создании систем, способных адаптироваться к изменениям этих предпочтений. И, конечно, в том, чтобы смириться с тем, что чинить продакшен — это не решение, а лишь продление его страданий.
Оригинал статьи: https://arxiv.org/pdf/2602.06669.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Химический синтез под контролем искусственного интеллекта: новые горизонты
- Искусственный нос будущего: как квантовая механика и машинное обучение распознают запахи
- Внимание на границе: почему трансформеры нуждаются в «поглотителях»
- Внимание в сети: Новый подход к ускорению больших языковых моделей
- Язык тела под присмотром ИИ: архитектура и гарантии
- S-Chain: Когда «цепочка рассуждений» в медицине ведёт к техдолгу.
- Квантовый поиск: новый взгляд на оптимизацию
- Квантовый дозор: Новая система обнаружения аномалий для умных сетей
- Квантовый Переворот: От Теории к Реальности
- Границы Разума: Управление Саморазвивающимися ИИ
2026-02-10 02:48