Автор: Денис Аветисян
Исследователи предлагают инновационную структуру, позволяющую эффективно сочетать способности к пониманию и генерации контента в мультимодальных системах.

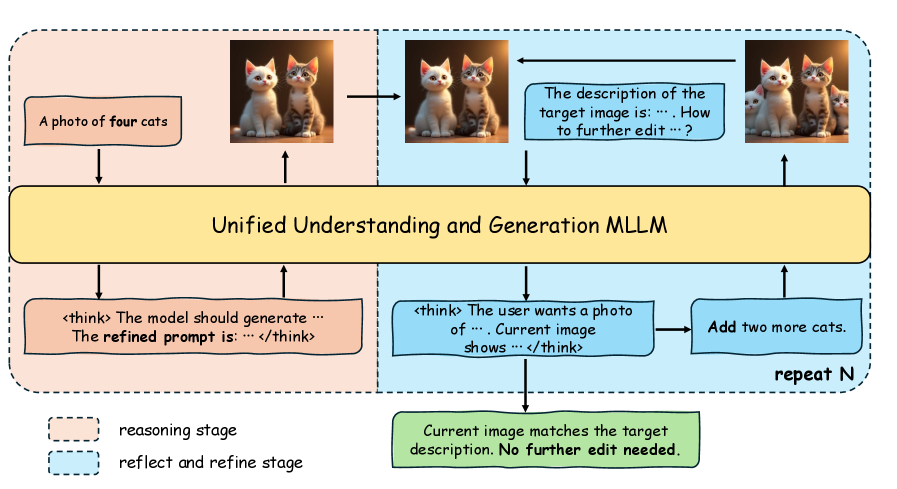
В статье представлена схема Reason-Reflect-Refine (R3), интегрирующая понимание в цикл генерации через итеративное уточнение, что позволяет смягчить противоречие между возможностями понимания и генерации.
В современных мультимодальных моделях часто наблюдается компромисс между способностью к генерации и пониманием данных. В статье ‘Understanding vs. Generation: Navigating Optimization Dilemma in Multimodal Models’ исследуется данная проблема и показано, что её корень может заключаться во внутренней конкуренции между этими двумя функциями. Для решения этой дилеммы авторы предлагают фреймворк Reason-Reflect-Refine (R3), который интегрирует понимание в процесс генерации посредством итеративного уточнения. Может ли подобный подход стать основой для создания нового поколения унифицированных мультимодальных моделей, сочетающих в себе как высокую генеративную способность, так и глубокое понимание данных?
Постижение Смысла: За Гранью Простого Воспроизведения
Современные модели преобразования текста в изображение демонстрируют впечатляющую способность создавать визуально привлекательные изображения, однако часто испытывают трудности при обработке сложных запросов, требующих точной интерпретации и композиционного мышления. Несмотря на достигнутый прогресс в генерации реалистичных пикселей, модели нередко не способны правильно понять взаимосвязи между объектами и их атрибутами, описанными в текстовом запросе. В результате, сгенерированные изображения могут выглядеть правдоподобно, но при этом не соответствовать исходному замыслу или содержать логические несоответствия. Это указывает на необходимость развития моделей, способных не просто генерировать изображения, а понимать смысл и контекст запроса, прежде чем приступить к визуализации.
Современные модели преобразования текста в изображение зачастую демонстрируют приоритет достижения фотореалистичности над смысловой точностью. В результате, генерируемые изображения могут визуально казаться правдоподобными, однако не соответствуют изначальному запросу или его подтексту. Данное несоответствие обусловлено тем, что алгоритмы сосредотачиваются на детальной проработке пикселей, игнорируя при этом более глубокое понимание семантики и композиционного смысла, заключенного в текстовом описании. Это приводит к созданию визуально привлекательных, но концептуально неверных изображений, подчеркивая необходимость развития моделей, способных к более тонкому анализу и интерпретации запросов.
Существующий разрыв между способностью моделей генерировать визуально привлекательные изображения и их умением точно интерпретировать сложные запросы подчеркивает необходимость принципиально нового подхода. Вместо того чтобы просто стремиться к фотореалистичности на уровне отдельных пикселей, современные системы должны уделять первостепенное внимание глубокому пониманию смысла, заключенного в текстовом описании. Такой подход предполагает, что перед визуализацией модель должна не просто распознать ключевые слова, но и установить логические связи между ними, понять намерения пользователя и создать композицию, отражающую именно задуманный результат, а не просто формальное соответствие отдельным элементам запроса. Разработка подобных моделей, способных к семантическому анализу и рассуждениям, является ключевым шагом к созданию действительно интеллектуальных систем генерации изображений.

R3: Рассуждение, Рефлексия и Уточнение — Основа Понимания
В основе фреймворка R3 лежит многоэтапный подход к генерации изображений по текстовому описанию, начинающийся с этапа «Рассуждение» (Reason). Данный этап предполагает расширение исходного запроса с целью создания детализированного плана и концептуальной схемы будущего изображения. Это включает в себя не просто интерпретацию ключевых слов, но и выявление подразумеваемых атрибутов, взаимосвязей между объектами и контекста, необходимых для формирования семантически корректного и визуально связного результата. На этапе «Рассуждения» формируется структурированное представление желаемого изображения, служащее основой для последующих этапов генерации и оценки.
Стадия “Рефлексия” в рамках фреймворка R3 представляет собой критическую оценку сгенерированного изображения по отношению к исходному текстовому запросу. В процессе рефлексии система анализирует изображение на предмет соответствия семантическому содержанию запроса, выявляя расхождения и области, требующие улучшения. Оценка включает в себя проверку наличия всех элементов, указанных в запросе, а также корректности их взаимосвязей и атрибутов. Выявленные несоответствия фиксируются для последующего этапа “Уточнение”, служа основой для корректировки изображения и повышения его соответствия первоначальным требованиям.
Стадия “Уточнение” (Refine) использует результаты анализа, полученные на стадии “Оценка” (Reflect), для внесения изменений в сгенерированное изображение. Этот процесс включает в себя модификацию параметров генерации или повторную генерацию отдельных элементов изображения с целью повышения соответствия конечному результату исходному запросу и достижения большей семантической точности. Изменения могут касаться как глобальных характеристик изображения, так и деталей, влияющих на точность представления объектов и их взаимосвязей, что позволяет добиться более качественного и соответствующего ожиданиям результата.
BAGEL и Безпотерийное Представление: Сердце Алгоритма
Ядро фреймворка R3 представлено системой BAGEL, обеспечивающей базовые возможности для анализа изображений, их генерации и редактирования. BAGEL выступает в роли центрального вычислительного модуля, принимающего и обрабатывающего входные данные для выполнения всех ключевых операций, связанных с визуальным контентом. Архитектура системы позволяет эффективно решать задачи компьютерного зрения, начиная от распознавания объектов и заканчивая сложным редактированием и синтезом изображений, что делает BAGEL неотъемлемой частью всего рабочего процесса R3.
В основе производительности BAGEL лежит использование ‘Непрерывных токенов без потерь’ (Lossless Continuous Tokens), представляющих собой метод кодирования данных, минимизирующий потерю информации при преобразовании. В отличие от дискретных токенов, которые могут приводить к округлению и потере деталей, непрерывные токены сохраняют критически важные характеристики исходных данных, обеспечивая более точное представление и, как следствие, улучшенное качество обработки изображений, генерации и редактирования. Этот подход позволяет BAGEL сохранять мельчайшие нюансы и текстуры, необходимые для реалистичного и детализированного результата.
В основе генерации высококачественных изображений в BAGEL используются диффузионные архитектуры, которые позволяют создавать детализированные и реалистичные визуальные представления. Для обработки текстовых запросов, поступающих от пользователя, применяется токенизация — процесс преобразования текста в числовые векторы. Эти векторы, представляющие собой последовательность токенов, служат входными данными для диффузионной модели, определяя содержание и характеристики генерируемого изображения. Таким образом, токенизация обеспечивает взаимодействие между текстовым описанием и процессом генерации изображения внутри BAGEL.
Проверка R3: Производительность на Сложных Бенчмарках
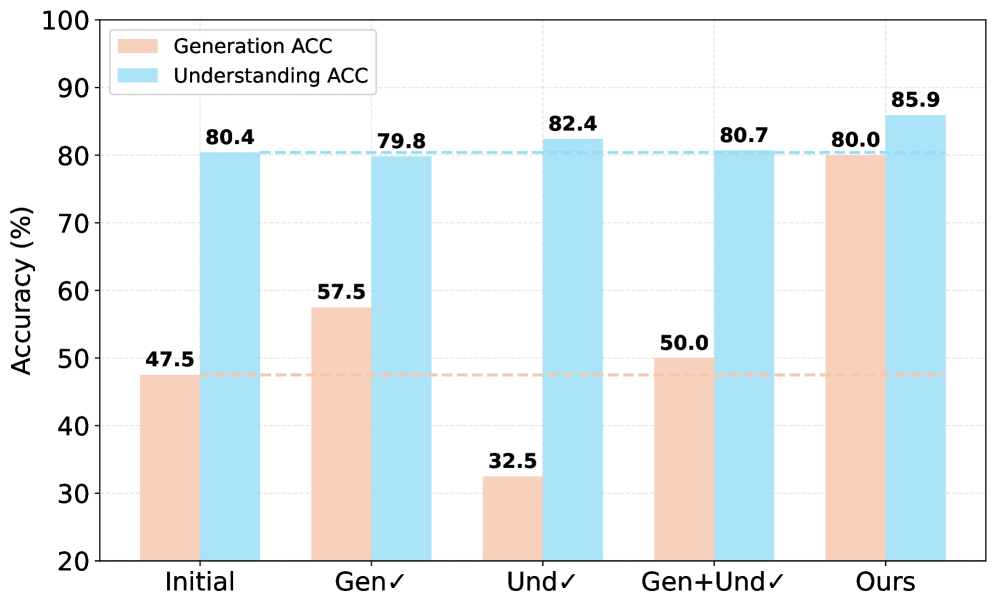
Для всесторонней оценки возможностей новой системы R3 был использован комплексный бенчмарк GenEval++. Этот инструмент специально разработан для проверки моделей преобразования текста в изображения, предъявляя к ним высокие требования по композиционному построению сцен и пониманию сложных текстовых описаний. GenEval++ позволяет выявить, насколько точно модель интерпретирует взаимосвязи между объектами, учитывает их атрибуты и корректно воссоздает их в визуальном представлении. Тщательное тестирование на GenEval++ позволило установить, что R3 демонстрирует выдающиеся результаты в обработке сложных запросов, превосходя существующие аналоги и подтверждая эффективность предложенного подхода к генерации изображений.
В ходе всестороннего тестирования, фреймворк R3 продемонстрировал передовые результаты на бенчмарке GenEval++, достигнув показателя в 0.962. Этот результат свидетельствует о значительном превосходстве R3 над существующими моделями в генерации изображений по сложным текстовым запросам. Достижение столь высокого балла указывает на способность системы точно интерпретировать и визуализировать даже самые детализированные и многокомпонентные описания, что подтверждает эффективность предложенного подхода к генерации изображений и открывает новые перспективы в области искусственного интеллекта.
Исследования показали, что разработанная система демонстрирует выдающиеся способности в задачах, требующих пространственного мышления и понимания взаимосвязей между объектами. В частности, при решении задач навигации по лабиринтам, система успешно определяет оптимальный путь и генерирует соответствующие визуализации, демонстрируя глубокое понимание структуры и логики пространства. Способность к эффективному анализу и представлению пространственных отношений является ключевым преимуществом данной архитектуры и открывает возможности для применения в различных областях, таких как робототехника, виртуальная реальность и создание интеллектуальных систем навигации.
Результаты исследований подтверждают, что многоступенчатый подход, реализованный в R3 — включающий этапы рассуждения, рефлексии и уточнения — значительно повышает качество и точность генерируемых изображений, особенно в сложных ситуациях. Модель достигает практически оптимальной производительности всего за два цикла рефлексии и уточнения, в то время как базовые модели требуют трех циклов для достижения сопоставимых результатов. Данная эффективность свидетельствует о том, что последовательное применение этапов рассуждения и самоанализа позволяет R3 более эффективно решать сложные задачи генерации изображений, требующие понимания контекста и детального исполнения.

Представленная работа акцентирует внимание на необходимости преодоления дихотомии между генерацией и пониманием в мультимодальных моделях. Авторы предлагают подход Reason-Reflect-Refine (R3), который позволяет итеративно уточнять процесс генерации, интегрируя в него элементы понимания. Этот подход, по сути, стремится к созданию моделей, способных не просто воспроизводить данные, но и осмысливать их. Ян Лекун однажды заметил: «Машинное обучение — это не просто аппроксимация функций, это поиск инвариантных представлений». В контексте данной статьи, инвариантные представления формируются через итеративный процесс R3, где модель, подобно математическому пределу, стремится к устойчивому пониманию, даже когда сложность входных данных неограниченно возрастает. Пусть N стремится к бесконечности — что останется устойчивым? В данном случае — способность модели к осмысленному взаимодействию с данными.
Куда Далее?
Представленная работа, несмотря на элегантность предложенной схемы Reason-Reflect-Refine, лишь обозначает границы проблемы, а не решает её окончательно. Вопрос о том, что именно подразумевается под “пониманием” в контексте мультимодальных моделей, остаётся открытым. Простое улучшение метрик генерации, даже с привлечением механизмов самооценки, не гарантирует истинного интеллектуального прогресса. Вспомним, что оптимизация без анализа — это самообман и ловушка для неосторожного разработчика.
Перспективы дальнейших исследований лежат, вероятно, в области формализации понятия “понимания” и разработки метрик, способных измерять не просто правдоподобие сгенерированного контента, а его соответствие логическим и причинно-следственным связям. Необходимо уделить внимание вопросам интерпретируемости моделей, чтобы понять, на каких основаниях они принимают решения и как можно гарантировать их устойчивость к предвзятости и манипуляциям.
В конечном счете, задача состоит не в создании моделей, которые просто имитируют интеллект, а в разработке систем, способных к истинному обучению и адаптации. Путь к этому лежит через строгое математическое обоснование алгоритмов и тщательный анализ их ограничений. Иначе, все усилия по улучшению генерации останутся лишь красивой, но бесполезной иллюзией.
Оригинал статьи: https://arxiv.org/pdf/2602.15772.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, планирующий путешествия: новый подход к сложным задачам
- Искусственный интеллект и квантовая физика: кто кого?
- Таблицы оживают: Искусственный интеллект осваивает структурированные данные
- Большие языковые модели как судьи перевода: бюджет на размышления и калибровка реальности.
- Квантовый импульс для нейросетей: новый подход к распознаванию изображений
- Саморедактирование научных статей: новый взгляд на качество и влияние
- Гендерные стереотипы в найме: что скрывают языковые модели?
- Искусственный интеллект в действии: как расширяется сфера возможностей?
- Языковые модели диффузии: новый уровень эффективности
- Музыка, созданная ИИ: кто мы есть, когда слушаем?
2026-02-18 22:49