Автор: Денис Аветисян
В статье представлен всесторонний обзор современных методов глубокого обучения для автоматического определения аккордов в музыкальных произведениях.
Исследование охватывает вопросы синхронизации ритма, аугментации данных и применения генеративных моделей для повышения точности распознавания аккордов.
Несмотря на значительный прогресс в области машинного обучения, автоматическое распознавание аккордов остается сложной задачей. Данная работа, озаглавленная ‘Chord Recognition with Deep Learning’, посвящена всестороннему исследованию современных методов глубокого обучения для решения этой проблемы. Полученные результаты демонстрируют, что применение аугментации данных и синхронизации с ритмом значительно повышает точность распознавания, в то время как использование генеративных моделей не дает существенных улучшений. Какие новые подходы и архитектуры могут привести к дальнейшему качественному скачку в автоматическом анализе гармонии?
Сложность данных: вызов для автоматического распознавания аккордов
Автоматическое распознавание аккордов сталкивается с существенной проблемой — недостатком достоверно размеченных музыкальных данных, что негативно сказывается на эффективности моделей. В отличие от задач, где доступны огромные базы данных, для анализа гармонии часто не хватает качественных примеров, что затрудняет обучение алгоритмов. Ограниченность размеченных данных приводит к тому, что модели испытывают трудности с обобщением и распознаванием аккордов в новых, ранее не встречавшихся музыкальных контекстах. В результате, точность определения аккордов снижается, а системы становятся менее надежными при работе с разнообразным музыкальным материалом. Поэтому, поиск способов преодоления этой проблемы — создание методов, требующих меньше данных для обучения, или разработка эффективных стратегий для увеличения объема размеченных данных — является ключевой задачей в области автоматического анализа музыки.
Традиционные методы машинного обучения, применяемые для распознавания аккордов, часто сталкиваются с проблемой обобщения при ограниченном количестве примеров. Это связано с тем, что алгоритмы, обученные на небольшом наборе данных, испытывают трудности при анализе новых, незнакомых музыкальных фрагментов. В результате, точность предсказаний снижается, а система становится уязвимой к вариациям в исполнении, тембре и других факторах, не учтенных в обучающей выборке. Подобная неспособность к адаптации приводит к неустойчивой работе и снижает надежность автоматического анализа гармонии, что особенно критично в задачах, требующих высокой точности и стабильности.
Ограниченность размеченных музыкальных данных напрямую влияет на способность создаваемых систем к эффективному пониманию и интерпретации музыкальной гармонии. Недостаток точных примеров препятствует обучению алгоритмов, что приводит к неточностям в определении аккордов и снижает общую надежность автоматического распознавания. В результате, системы испытывают трудности с анализом сложных гармонических последовательностей и могут ошибочно интерпретировать музыкальные произведения, особенно в тех случаях, когда встречаются редкие или нестандартные аккордовые прогрессии. Это представляет собой серьезную проблему для развития музыкальных информационных систем, стремящихся к интеллектуальному анализу и пониманию музыки.
Гармонически обоснованная генерация синтетических данных
Проблема недостатка данных в задачах анализа и обработки музыки решается путем генерации синтетических музыкальных данных, основанных на принципах функциональной гармонии. Этот подход позволяет создавать обучающие наборы данных, имитирующие гармонически корректные последовательности аккордов и мелодий, даже при ограниченном количестве реальных музыкальных произведений. Генерация осуществляется с учетом правил построения аккордов и их функциональной роли в тональности, что обеспечивает создание реалистичных и правдоподобных музыкальных фрагментов. Применение принципов функциональной гармонии позволяет избежать создания случайных или диссонирующих последовательностей, повышая качество синтетических данных и их пригодность для обучения моделей машинного обучения.
Модель MusiConGen использует архитектуру автокодировщика (Autoencoder) для генерации реалистичных последовательностей аккордов, основанных на принципах функциональной гармонии. Автокодировщик обучается на существующем наборе гармонически корректных аккордовых прогрессий, сжимая входные данные в латентное пространство и затем реконструируя их. В процессе обучения модель улавливает статистические зависимости между аккордами и правила гармонического движения, что позволяет ей генерировать новые прогрессии, сохраняя музыкальную согласованность и правдоподобность. Использование автокодировщика позволяет модели не только воспроизводить существующие паттерны, но и создавать вариации, расширяя возможности для генерации данных.
Процесс генерации новых музыкальных фраз основан на соблюдении установленных правил последовательностей аккордов (ChordProgression), с учетом корневого тона (Root) и качества аккорда (ChordQuality). Это означает, что генерируемые последовательности не случайны, а строятся в соответствии с принципами гармонии, обеспечивая их музыкальную согласованность и правдоподобность. Алгоритм учитывает как допустимые переходы между аккордами, так и влияние корневого тона и качества аккорда на общую гармоническую структуру фразы, что позволяет создавать музыкально осмысленные и корректные последовательности.
Генерация синтетических данных, основанных на принципах музыкальной теории, направлена на повышение способности обобщения системы распознавания аккордов. Ограниченность обучающих данных часто приводит к снижению точности распознавания в новых, ранее не встречавшихся музыкальных контекстах. Использование правил функциональной гармонии при создании синтетических примеров позволяет расширить обучающую выборку, включив в неё вариации, соответствующие музыкально корректным последовательностям аккордов. Это, в свою очередь, позволяет модели лучше адаптироваться к различным музыкальным стилям и повысить её устойчивость к шумам и вариациям в исполнении, что критически важно для практического применения системы распознавания аккордов.
Архитектура CRNN и ее усовершенствования для точного предсказания
Основная модель, используемая в системе — `CRNN` (Convolutional Recurrent Neural Network) — обучается на комбинированном наборе данных, включающем как реальные музыкальные отрывки, так и синтетически сгенерированные примеры. Использование синтетических данных позволяет значительно увеличить объем обучающей выборки и расширить покрытие различных музыкальных сценариев, что особенно важно для улучшения обобщающей способности модели и повышения точности предсказаний, особенно в случаях, когда реальных данных недостаточно для обучения всем необходимым параметрам. Такой подход позволяет максимизировать производительность системы в целом и обеспечить стабильную работу в различных условиях.
В качестве входных данных для CRNN используется временная-частотная репрезентация аудиосигнала, полученная посредством CQT-преобразования (Constant-Q Transform). CQT обеспечивает логарифмическую шкалу частот, что соответствует принципам человеческого восприятия звука и позволяет эффективно анализировать музыкальные гармонии. В отличие от традиционного FFT, CQT обеспечивает постоянное разрешение по частоте, что особенно важно для анализа гармонических структур в музыке. Полученная временная-частотная карта представляет собой матрицу, где каждая строка соответствует определенной частоте, а каждый столбец — определенному моменту времени, и служит входным сигналом для последующей обработки нейронной сетью.
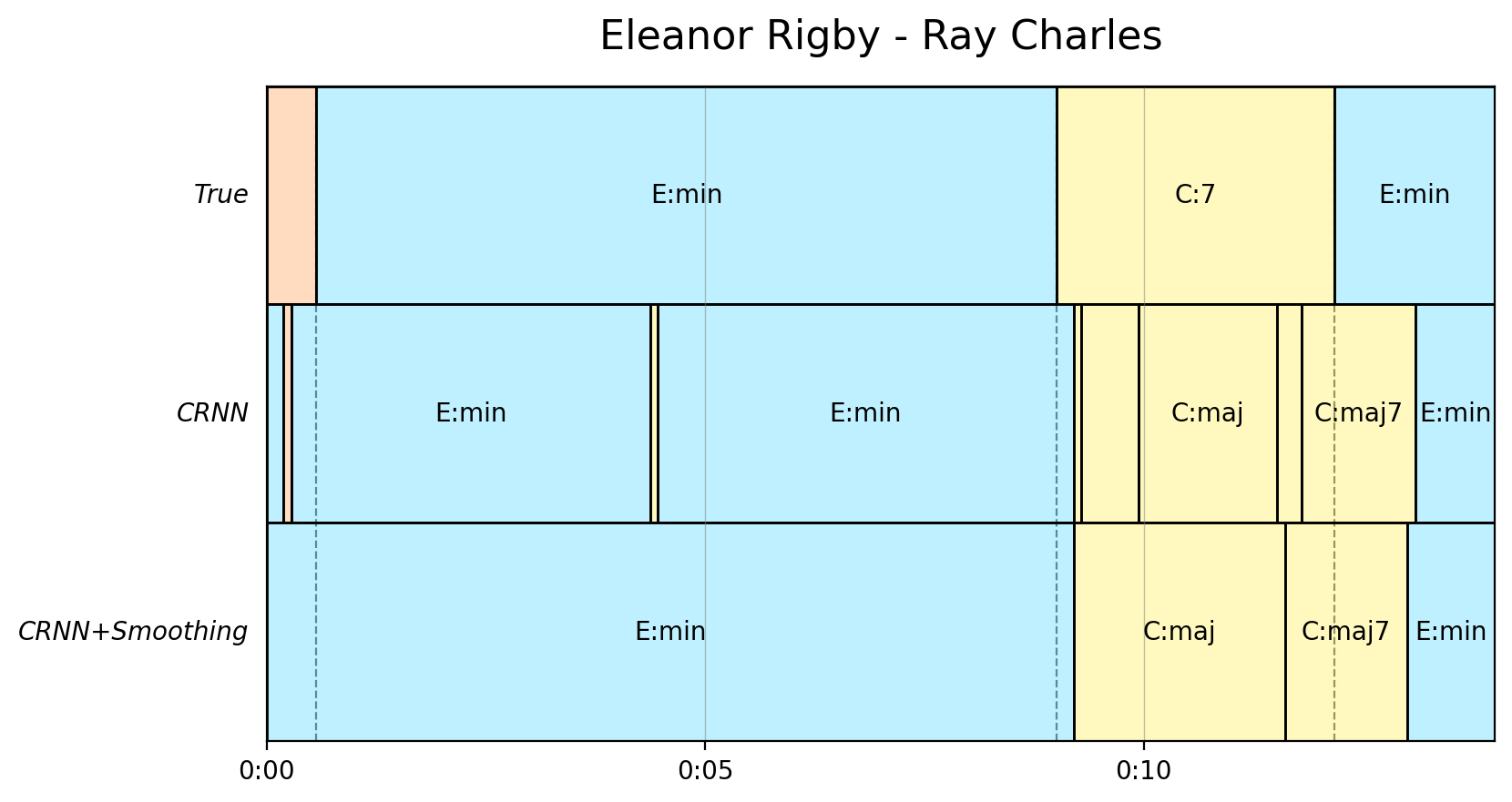
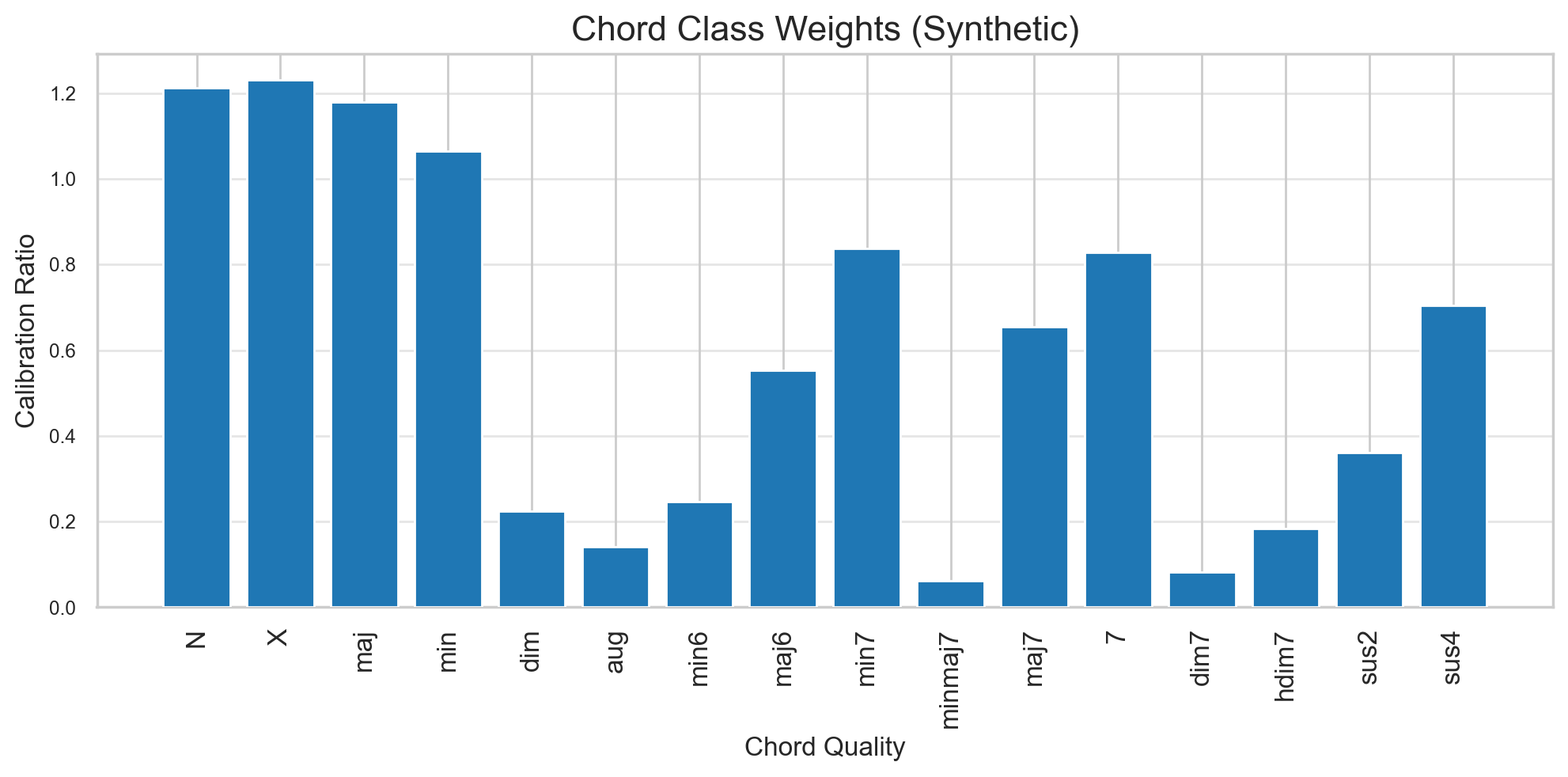
Для решения проблемы дисбаланса классов в распределении аккордов, обусловленного неравномерным представлением различных аккордов в обучающей выборке, используется функция потерь `WeightedLoss`. Эта функция назначает больший вес редким классам, что позволяет модели уделять им больше внимания во время обучения и снижает влияние доминирующих классов. Дополнительно, для сглаживания предсказаний во времени и повышения их согласованности применяется скрытая марковская модель (HMM). HMM учитывает временную зависимость между последовательными предсказаниями аккордов, моделируя вероятность перехода между ними и обеспечивая более плавные и правдоподобные последовательности аккордов в выходных данных.
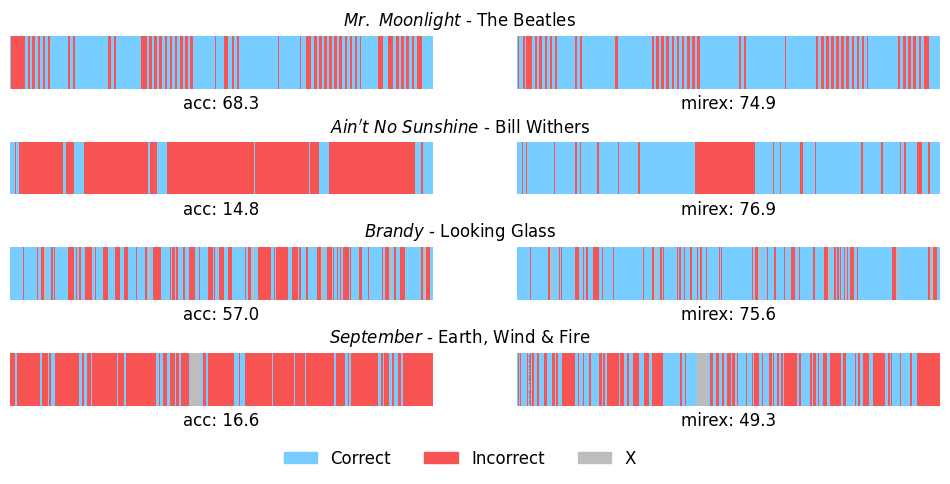
Для повышения интерпретируемости предсказаний аккордов в нашей системе, применяется процедура синхронизации с тактами (BeatSynchronisation). Данный процесс заключается в выравнивании предсказаний аккордов по временной шкале с моментами ударов (beat timings) посредством использования кросс-корреляции (CrossCorrelation). Применение данной техники позволило достичь пикового результата в рамках оценки Mirex, составившего 90.4%, что свидетельствует о значительном улучшении точности и согласованности предсказаний с ритмической структурой музыкального произведения.
Повышенная производительность и перспективы музыкального анализа
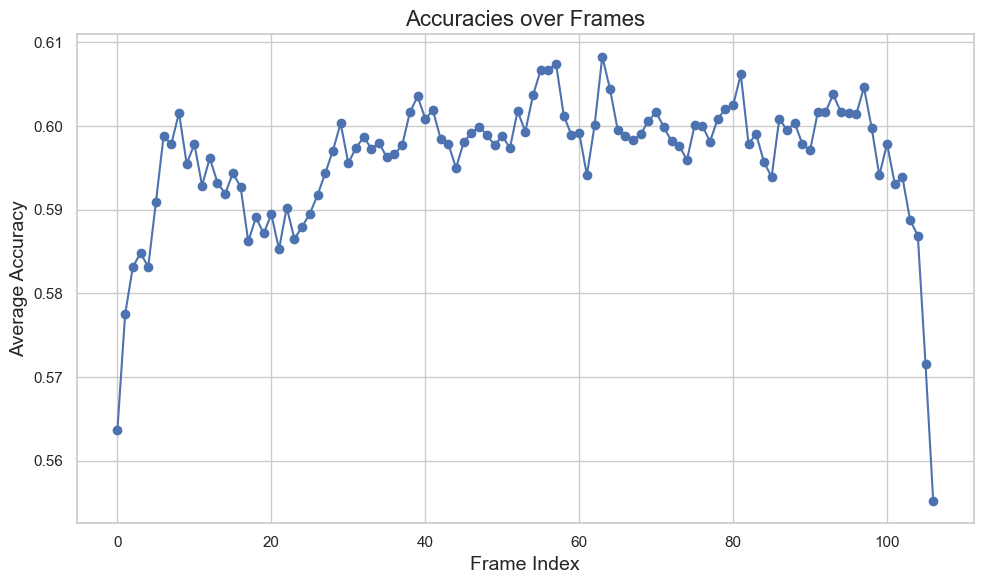
Интеграция синтетических данных в процесс обучения, наряду с усовершенствованием архитектуры модели, позволила добиться значительного повышения точности и устойчивости алгоритмов распознавания аккордов. Результаты показывают, что при использовании комбинированного набора данных, включающего как реальные, так и сгенерированные музыкальные фрагменты, общая точность распознавания достигает 64.3%. Такое улучшение свидетельствует о перспективности подхода, позволяющего преодолеть ограничения, связанные с недостаточным количеством размеченных данных, и открывает возможности для создания более надежных и эффективных систем автоматического анализа музыкального контента. Это, в свою очередь, способствует развитию новых методов транскрипции и гармонического анализа музыки с использованием машинного обучения.
Достижения в области распознавания аккордов открывают новые перспективы для углубленного анализа музыкальных произведений. Повышенная точность алгоритмов позволяет автоматизировать процесс транскрипции музыки, преобразуя аудиозаписи в нотные записи с высокой степенью достоверности. Кроме того, стало возможным проведение автоматического гармонического анализа, выявление ключевых аккордов, тональностей и прогрессий, что значительно упрощает задачу изучения музыкальной структуры и выявления закономерностей. Данные инструменты, в свою очередь, предоставляют бесценную помощь композиторам, музыковедам и всем, кто стремится к более глубокому пониманию музыкального искусства, способствуя как созданию новых произведений, так и анализу уже существующих.
Исследование продемонстрировало, что комбинирование синтетических данных с функцией взвешенных потерь позволило добиться повышения точности распознавания аккордов на 0.6%. Особенно заметный эффект наблюдался при распознавании минорных септаккордов (min7), где использование синтетических данных привело к увеличению полноты (recall) на 13%. Данный результат свидетельствует о том, что искусственно сгенерированные данные способны эффективно дополнять существующие наборы, улучшая способность моделей машинного обучения к идентификации сложных гармонических структур и, следовательно, открывая новые возможности для автоматического анализа музыкальных произведений.
Недостаток размеченных музыкальных данных долгое время являлся серьезным препятствием для развития машинного обучения в области анализа гармонии. Представленное исследование демонстрирует, что преодоление этой проблемы, посредством генерации синтетических данных, открывает новые возможности для более глубокого понимания музыкальных закономерностей. Использование синтетических данных позволило существенно увеличить объем обучающей выборки, что, в свою очередь, привело к повышению точности распознавания аккордов и более надежному анализу гармонических структур. Это, в перспективе, может привести к созданию автоматизированных систем транскрипции музыки и углубленному изучению принципов построения музыкальных произведений с использованием алгоритмов машинного обучения.
Исследование, посвященное автоматическому распознаванию аккордов с использованием глубокого обучения, подчеркивает важность не только сложности моделей, но и их способности к обобщению. В стремлении к повышению точности, авторы обращаются к методам аугментации данных и генеративным моделям, стремясь преодолеть ограничения существующих подходов. В этой работе явно прослеживается стремление к редукции — к поиску наиболее эффективных и лаконичных решений. Как заметил Роберт Тарьян: «Простота — это форма интеллекта, а не ограничение». Эта фраза отражает суть представленного исследования: стремление к элегантности и эффективности в сложных алгоритмах обработки музыкальной информации.
Что дальше?
Исследование, посвященное автоматическому распознаванию аккордов посредством глубокого обучения, обнажает не столько новые возможности, сколько устоявшиеся ограничения. Очевидно, что акцент на увеличении объёма данных и сложности моделей лишь отодвигает фундаментальную проблему: извлечение сути музыкальной гармонии требует не просто распознавания паттернов, а понимания их контекста и эмоциональной окраски. Добавление новых слоёв к нейронной сети напоминает наслоение лака на трещину — проблема не исчезает, она лишь скрывается.
Вместо бесконечной гонки за точностью, представляется более продуктивным поиск принципиально иных подходов. Следует обратить внимание на методы, имитирующие когнитивные процессы человека при восприятии музыки — внимание к тембру, динамике, и, что наиболее важно, к ожиданию разрешения гармонического напряжения. Генеративные модели, хотя и демонстрируют определённый потенциал, пока остаются лишь инструментом для создания вариаций, а не для глубокого понимания музыкального языка.
В конечном итоге, истинный прогресс в области автоматического распознавания аккордов заключается не в создании все более совершенных алгоритмов, а в признании ограниченности машинного интеллекта перед лицом искусства. Попытка свести гармонию к математической формуле — упражнение в тщеславии. Задача состоит не в том, чтобы научить машину «слышать» аккорды, а в том, чтобы понять, что музыка — это не просто звук, а отражение человеческой души.
Оригинал статьи: https://arxiv.org/pdf/2512.22621.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Квантовые прорывы: Хорошее, плохое и смешное
- Метаболический профиль СДВГ: новый взгляд на диагностику
- Квантовые вычисления: от шифрования армагеддона до диверсантов космических лучей — что дальше?
- Квантовая криптография: от теории к практике
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Робот, который видит, понимает и действует: новая эра общего назначения
2025-12-31 15:31