Автор: Денис Аветисян
Новый бенчмарк SourceBench призван проверить, насколько искусственный интеллект опирается на качественные и проверенные источники информации в интернете.
Представлен комплексный метод оценки надежности веб-источников, используемых большими языковыми моделями для формирования ответов.
Несмотря на растущую способность больших языковых моделей (LLM) отвечать на запросы, опираясь на веб-источники, оценка качества этих источников часто упускается из виду. В данной работе представлена новая методика оценки, получившая название ‘SourceBench: Can AI Answers Reference Quality Web Sources?’, позволяющая измерить качество веб-источников, цитируемых LLM, по широкому спектру запросов. Предложенный комплексный восьмикомпонентный фреймворк охватывает как содержание (актуальность, фактическую точность, объективность), так и характеристики веб-страниц (свежесть, авторитетность, ясность). Каким образом повышение качества цитируемых источников может способствовать созданию более надежных и заслуживающих доверия систем искусственного интеллекта?
Кризис Качества Источников в Эпоху Больших Языковых Моделей
Современные большие языковые модели (БЯМ) всё чаще обращаются к поиску в интернете для расширения своей базы знаний, что формирует зависимость от внешних источников информации. Этот подход позволяет БЯМ предоставлять более актуальные и полные ответы на запросы, однако одновременно создаёт новые вызовы. Вместо того, чтобы полагаться исключительно на данные, встроенные в модель во время обучения, БЯМ динамически извлекают информацию из сети, используя поисковые системы для поиска релевантных фрагментов текста. Этот процесс позволяет моделям адаптироваться к быстро меняющемуся миру информации, но также и делает их уязвимыми к качеству и достоверности найденных источников. Таким образом, способность БЯМ эффективно использовать веб-поиск становится ключевым фактором их производительности и надежности.
Надёжность ответов больших языковых моделей (LLM) напрямую зависит от качества информации, получаемой из внешних источников, однако существующие методы оценки достоверности этих источников сталкиваются с серьёзными трудностями. Автоматизированные системы часто не способны отличить авторитетные публикации от предвзятых или устаревших, что приводит к включению недостоверных данных в процесс обучения моделей. Более того, динамичный характер веб-контента, с постоянными изменениями и появлением новых сайтов, требует непрерывного обновления и переоценки источников, что является сложной задачей. В результате, даже самые передовые LLM могут генерировать ответы, основанные на неточной или вводящей в заблуждение информации, подрывая доверие к искусственному интеллекту и создавая риски распространения дезинформации.
Существует серьезный риск распространения дезинформации и подрыва доверия пользователей к контенту, генерируемому искусственным интеллектом. Поскольку большие языковые модели (LLM) все чаще полагаются на информацию, полученную из сети, качество и достоверность исходных источников становятся критически важными. Если LLM используют недостоверные или предвзятые данные, это неизбежно отразится на точности и объективности генерируемого текста. В результате, пользователи могут столкнуться с ложными утверждениями, манипуляциями и искаженной информацией, что приведет к снижению доверия к технологиям искусственного интеллекта и, как следствие, к их неэффективному использованию в различных сферах жизни.
Многогранная Система Оценки: Архитектура Надежности
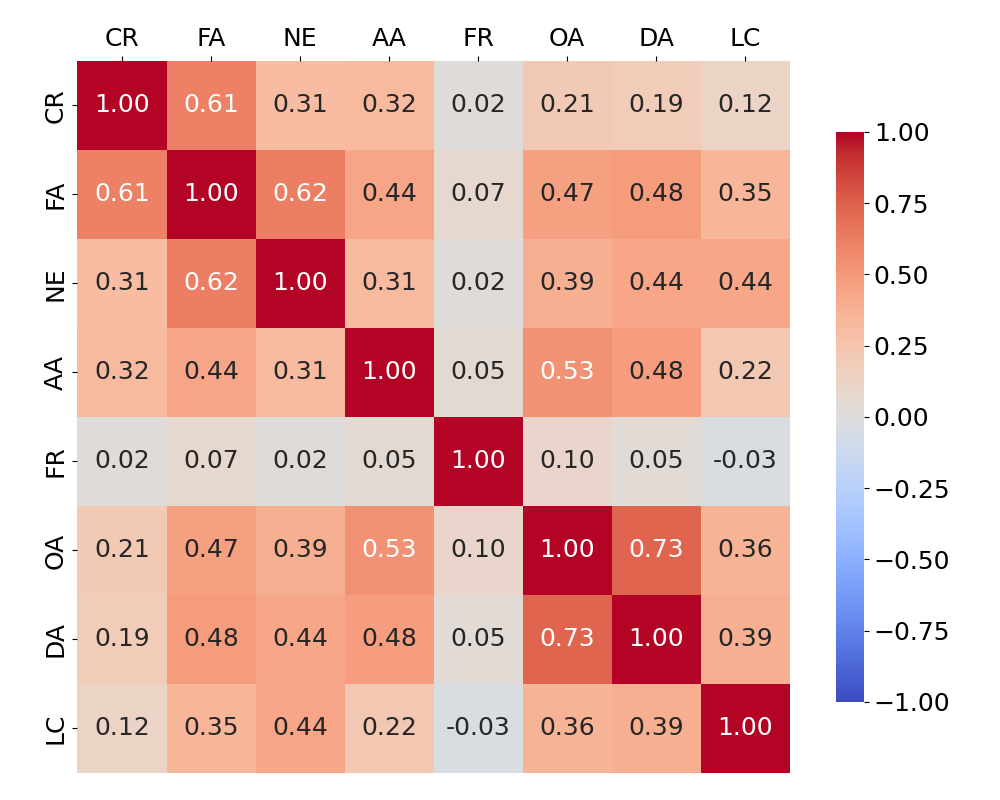
Предлагаемая Многофакторная Система Оценки (Multi-Facet Scoring Framework) представляет собой комплексную методологию для оценки веб-источников, основанную на анализе по нескольким измерениям. Вместо использования единого показателя, система оценивает источники по различным критериям, позволяя получить более детализированную и точную картину качества информации. Оценка производится по нескольким независимым параметрам, что позволяет выявить сильные и слабые стороны каждого источника и сформировать комплексный балл, отражающий его надежность и релевантность. Данный подход обеспечивает более гибкую и информативную оценку, чем традиционные методы, основанные на едином показателе или ограниченном наборе критериев.
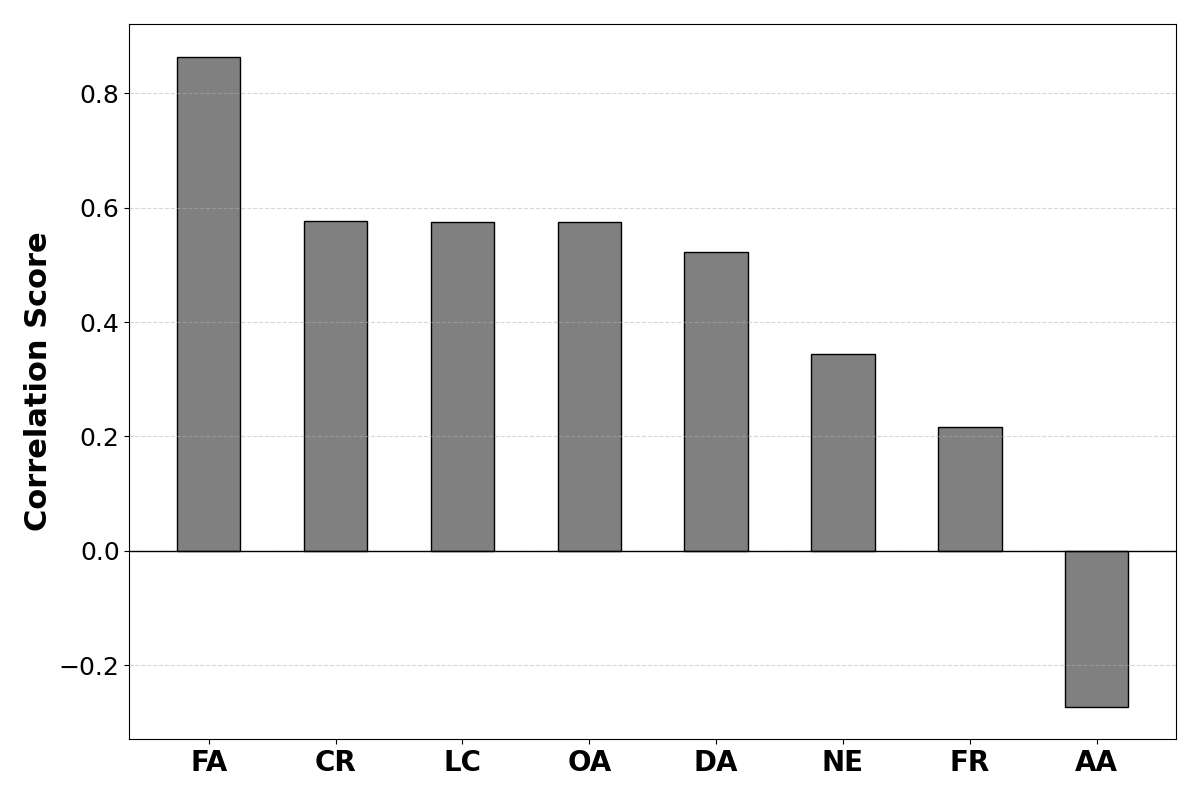
Многофакторная система оценки источников информации включает в себя следующие ключевые метрики: фактическая точность, определяющая соответствие представленных данных действительности; соответствие контента запросу или теме; объективность, отражающая отсутствие предвзятости и субъективных оценок; актуальность, указывающая на своевременность и современность информации; организация, характеризующая логическую структуру и удобство восприятия; подотчетность автора, подразумевающая наличие информации об авторе и его квалификации; авторитетность домена, оцениваемая на основе репутации и надежности веб-ресурса; и ясность оформления, влияющая на удобство чтения и понимания контента.
Предлагаемый многофакторный подход к оценке источников веб-контента направлен на выявление тонкостей, определяющих его качество. В отличие от упрощенных метрик, учитывающих лишь отдельные аспекты, данная методика комплексно анализирует такие параметры, как фактическая точность, релевантность, объективность, актуальность, структура, ответственность автора, авторитетность домена и ясность оформления. Такой подход позволяет получить более надежный сигнал для больших языковых моделей (LLM), поскольку учитывает широкий спектр характеристик, влияющих на достоверность и полезность информации, что повышает точность и качество генерируемых ответов и снижает вероятность использования ненадежных источников.
SourceBench: Испытание на Верность Источникам
SourceBench — это новый эталон, предназначенный для оценки способности больших языковых моделей (LLM) различать и приоритизировать высококачественные веб-источники. В отличие от существующих методов оценки, которые фокусируются на точности генерируемого текста, SourceBench непосредственно измеряет, насколько LLM способны идентифицировать и использовать надежные источники информации при формировании ответов. Эталон включает в себя набор вопросов, требующих от LLM поиска информации в сети, и последующего анализа качества используемых источников на основе различных критериев, таких как авторитетность домена, актуальность информации и объективность представленных данных. Результаты оценки, полученные с помощью SourceBench, позволяют количественно оценить способность LLM к критической оценке информации и ответственному использованию веб-ресурсов.
Для оценки источников, используемых в ответах больших языковых моделей (LLM), SourceBench применяет многофакторную систему оценки (Multi-Facet Scoring Framework). Эта система количественно определяет качество источников по нескольким параметрам, включая достоверность информации, авторитетность домена и объективность контента. Каждому источнику присваивается числовой балл, отражающий его общую надежность и полезность. Полученные баллы позволяют объективно сравнивать различные источники и оценивать, насколько эффективно LLM используют качественные источники при формировании ответов. Система обеспечивает воспроизводимую и стандартизированную метрику для оценки качества ссылок, что позволяет проводить сравнительный анализ между различными LLM и методами поиска информации.
Первичные результаты тестирования SourceBench демонстрируют, что GPT-5 достигает наивысшего общего балла, превосходя другие большие языковые модели (LLM) и поисковые инструменты. Однако, анализ показал, что LLM, включая GPT-5, не всегда последовательно отдают предпочтение источникам с более высоким рейтингом качества, определяемым Multi-Facet Scoring Framework. Это указывает на существенный пробел в способности моделей к логическому обоснованию и выбору наиболее надежных источников информации при формировании ответов.
Автоматизированная Оценка: Эхо Человеческой Экспертизы
Разработана автоматизированная система оценки веб-источников, основанная на усовершенствованной языковой модели. Система, прошедшая тонкую настройку, способна присваивать баллы источникам информации в соответствии с многофакторной системой оценки — Multi-Facet Scoring Framework. Этот подход позволяет учитывать различные аспекты качества, такие как достоверность, полноту и релевантность представленных данных. Благодаря этому, автоматизированная оценка становится возможной в больших масштабах, обеспечивая объективную и последовательную проверку веб-ресурсов на предмет их соответствия высоким стандартам качества и надежности информации.
Разработанная система автоматизированной оценки, основанная на больших языковых моделях, демонстрирует высокую степень соответствия с экспертными оценками качества веб-источников. Это означает, что алгоритм способен эффективно воспроизводить суждения человека относительно достоверности, актуальности и полезности информации. Важно отметить, что подобный подход позволяет значительно масштабировать процесс оценки, преодолевая ограничения, связанные с трудоемкостью и субъективностью ручной проверки. В результате, становится возможным оперативно и объективно оценивать огромные объемы данных, что особенно актуально в контексте быстрорастущего информационного потока и необходимости выявления надежных источников.
Исследования подтвердили, что модель GPT-5 демонстрирует наименьшее количество пересечений с существующими результатами поиска, что указывает на способность обнаруживать уникальные и качественные источники информации, ранее скрытые от широкого доступа. Установлена высокая корреляция между оценками, полученными с помощью SourceBench, и качеством ответов на вопросы в датасете HotpotQA, что подчеркивает критическую важность фактической точности при формировании ответов. Данные результаты свидетельствуют о том, что способность модели находить и использовать нетривиальные источники напрямую влияет на достоверность и надежность предоставляемой информации, открывая новые возможности для улучшения систем поиска и ответов на вопросы.
Будущее Доверия: Экосистема Надежной Информации
В будущем планируется интеграция SourceBench и LLM-основанного оценщика непосредственно в процессы обучения больших языковых моделей (LLM). Эта интеграция направлена на повышение значимости высококачественных источников информации при формировании ответов. Идея заключается в том, чтобы модели не просто генерировали текст, но и активно учитывали надежность и достоверность источников, из которых он получен. Посредством этого подхода, обучение LLM будет смещено в сторону приоритезации проверенных данных, что, в свою очередь, должно способствовать созданию более точных, надежных и объективных ответов. Внедрение подобной системы позволит значительно улучшить качество информации, предоставляемой языковыми моделями, и укрепить доверие к ним как к источникам знаний.
Исследования моделей DeepSeek продемонстрировали наивысшую эффективность при сочетании качественного веб-поиска и логического мышления, что открывает новые возможности для понимания взаимосвязи между этими двумя ключевыми аспектами работы больших языковых моделей. Углубленное изучение архитектуры и принципов работы DeepSeek позволит выявить, каким образом оптимизированный поиск релевантной информации влияет на способность модели к рассуждениям и принятию обоснованных решений. Анализ этого взаимодействия может привести к разработке более эффективных алгоритмов обучения, способных значительно повысить точность, надежность и объективность информации, предоставляемой искусственным интеллектом. Понимание этой синергии между поиском и рассуждением станет краеугольным камнем в создании более доверенной информационной экосистемы, основанной на принципах искусственного интеллекта.
Конечная цель исследований заключается в создании надежной информационной экосистемы на основе искусственного интеллекта, где языковые модели (LLM) последовательно предоставляют точную, достоверную и непредвзятую информацию. Это требует не просто улучшения алгоритмов, но и фундаментального переосмысления подхода к обучению LLM, акцентируя внимание на качестве источников и способности к критическому анализу данных. Достижение этой цели позволит минимизировать распространение дезинформации, повысить доверие к автоматизированным системам обработки информации и открыть новые возможности для использования ИИ в сферах, требующих высокой степени ответственности и объективности — от научных исследований и журналистики до принятия важных политических и экономических решений.
Исследование представляет собой не просто оценку источников, но и попытку предвидеть их неизбежное устаревание. Авторы, создавая SourceBench, словно провидцы, пытаются зафиксировать текущее качество веб-ресурсов, понимая, что эта «карта» быстро потеряет свою актуальность. Как будто каждый выбор метрики — это прогноз о будущей уязвимости системы. В этой работе явно прослеживается убеждение, что архитектура любой системы несет в себе семена будущего сбоя. В связи с этим, уместно вспомнить слова Давида Гильберта: «В каждом кроне скрыт страх перед хаосом». Ибо, несмотря на стремление к идеальной оценке, энтропия неизбежно внесет свои коррективы, и даже самый надежный источник со временем утратит свою ценность.
Что дальше?
Представленная работа, словно опытный садовник, обращает внимание на корни, а не на цветы. Оценка достоверности источников — это не просто техническая задача, а признание того, что любая система — это лишь эхо прошлого, и каждое её утверждение — обещание, данное тем, кто создал эти источники. Недостаточно строить системы, способные искать; необходимо, чтобы они умели распознавать, когда их знания начинают трескаться, и откуда берутся ростки ложной информации.
Разумеется, многомерная оценка качества источников — это лишь первый шаг. Истинная проблема заключается не в том, чтобы измерить доверие, а в том, чтобы понять, что доверие — иллюзия, требующая соглашения об уровне обслуживания. Система, уверенная в своей правоте, опаснее системы, признающей свою ограниченность. Следующим этапом, вероятно, станет исследование динамики доверия: как меняется оценка источника со временем, под влиянием новых данных и меняющихся представлений о мире.
В конечном счёте, вся эта работа — напоминание о том, что системы не строятся, а взращиваются. И каждый архитектурный выбор — это пророчество о будущем сбое. Надежда не в контроле, а в способности системы к самовосстановлению, к признанию собственных ошибок и к поиску новых, более надежных корней.
Оригинал статьи: https://arxiv.org/pdf/2602.16942.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Предел возможностей: где большие языковые модели теряют разум?
- Улучшение точности квантовых сенсоров: новый подход к подавлению шумов
- Резонансы в тандеме: Управление светом в микрорезонаторах
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
- Моделирование спектроскопии электронного пучка: новый подход
- Квантовое программирование: Карта развивающегося мира
- За пределами стандартной точности: новая структура эффективной теории
- Сердце музыки: открытые модели для создания композиций
- Тандем топ-кварков и бозона Хиггса: новые горизонты точности
- Квантовый скачок: от лаборатории к рынку
2026-02-22 12:39