Автор: Денис Аветисян
Новое исследование показывает, что производительность языковых моделей, обученных с подкреплением, не всегда растет с увеличением длины генерируемого текста.
Работа посвящена изучению немонотонной зависимости между длиной рассуждений и успехом языковой модели в задачах, требующих логического мышления.
Несмотря на значительный прогресс в обучении больших языковых моделей с подкреплением, остается неясным, как оптимально контролировать длину генерируемых рассуждений для достижения баланса между эффективностью и производительностью. В своей работе ‘On the Optimal Reasoning Length for RL-Trained Language Models’ авторы исследуют взаимосвязь между длиной выходных данных и качеством рассуждений в моделях, обученных с использованием обучения с подкреплением. Полученные результаты указывают на то, что оптимальный контроль длины зависит от предварительных возможностей модели к рассуждению, а как чрезмерно короткие, так и слишком длинные выводы могут снизить точность. Какие стратегии контроля длины позволят в полной мере раскрыть потенциал языковых моделей, обученных с подкреплением, в решении сложных задач?
Пределы Масштабирования: Рассуждения в Больших Языковых Моделях
Несмотря на впечатляющие возможности больших языковых моделей, простое увеличение их размера не гарантирует улучшения способности к рассуждениям, а зачастую приводит к неэффективности. Исследование показало, что связь между длиной генерируемого текста и качеством решения задач не является линейной. Наблюдается, что как недостаточная глубина рассуждений, так и чрезмерная многословность могут снижать точность ответов. В частности, было установлено, что существует оптимальная длина рассуждений, при превышении или уменьшении которой производительность модели снижается, что указывает на немонотонную зависимость между длиной ответа и его корректностью.
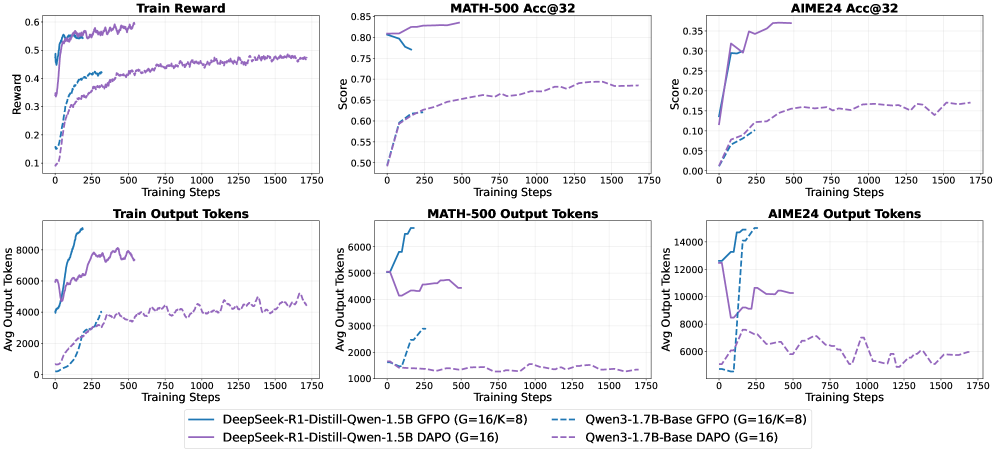
Исследования показали, что как недостаток, так и избыток шагов рассуждений негативно влияют на эффективность больших языковых моделей. Недостаточное количество шагов приводит к поверхностным выводам, в то время как чрезмерная многословность затуманивает логику и снижает точность. Интересно, что различные модели демонстрируют разное поведение: Qwen3-1.7B-Base показывает стабильное улучшение результатов с увеличением длины рассуждений, в то время как DeepSeek-R1-Distill-Qwen-1.5B достигает пика производительности на промежуточной длине, указывая на существование оптимальной глубины рассуждений. Данный факт подчеркивает важность разработки методов, позволяющих контролировать глубину рассуждений и находить баланс между достаточностью и лаконичностью для достижения максимальной эффективности языковых моделей.
Современные подходы к построению больших языковых моделей сталкиваются с трудностями в достижении оптимального баланса между длиной рассуждений и точностью ответов, что проявляется в немонотонной зависимости между этими факторами. Исследование выявило, что для модели DeepSeek-R1-Distill-Qwen-1.5B максимальная производительность достигается при умеренной длине цепочки рассуждений, после чего точность начинает снижаться. Это указывает на то, что как слишком краткие, так и избыточно детализированные рассуждения могут негативно сказываться на результатах, подчеркивая необходимость разработки методов, способных динамически адаптировать глубину анализа для решения конкретной задачи и избегать как «поверхностного», так и «чрезмерного» мышления.
Контроль Процесса Рассуждения: Оптимизация с Учетом Длины
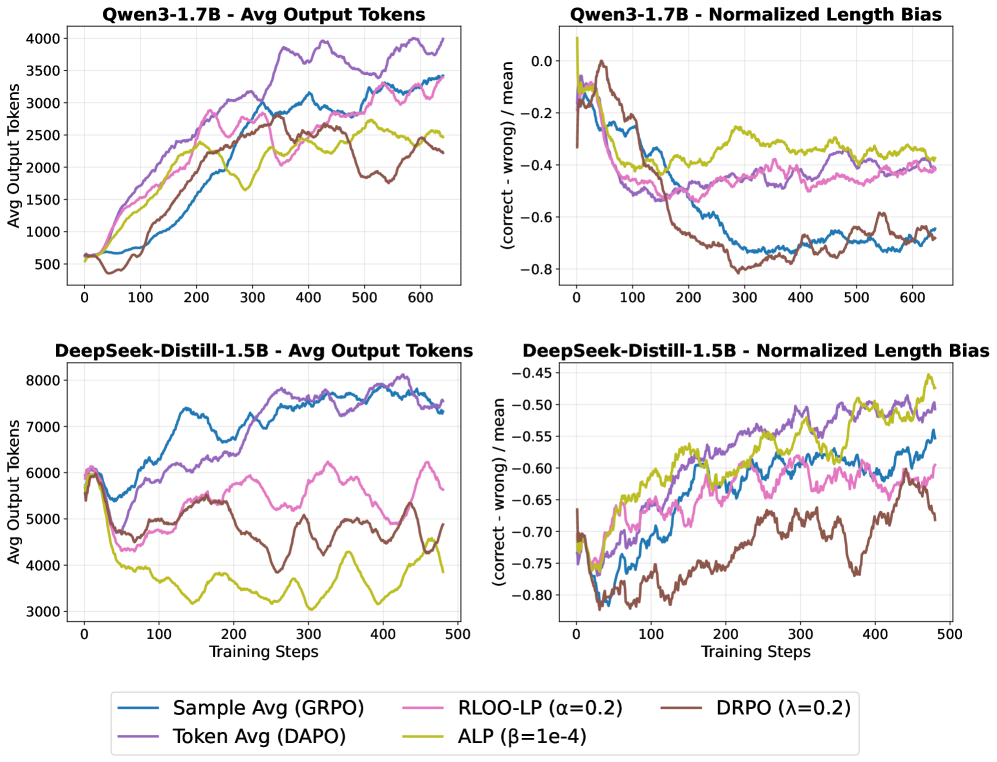
Эффективное рассуждение больших языковых моделей (LLM) напрямую зависит от управления длиной генерируемых выходных данных, измеряемой в токенах. Длина генерируемого текста оказывает существенное влияние на вычислительные затраты, как по времени, так и по ресурсам. Более длинные последовательности требуют экспоненциально больше вычислительной мощности для обработки. Поэтому, методы контроля длины (Length Control Methods) являются критически важными для снижения этих затрат, позволяя эффективно использовать доступные ресурсы и масштабировать применение LLM для более сложных задач. Контроль длины не только снижает стоимость вычислений, но и способствует повышению скорости ответа модели, что особенно важно для интерактивных приложений.
Методы контроля длины генерируемого текста, такие как DRPO, ALP и RLOO-LP, используют различные подходы к штрафным санкциям для ограничения длины выходных данных. ALP (Adaptive Length Penalty) применяет динамически изменяющийся штраф, пропорциональный текущей длине генерируемого текста, что позволяет адаптироваться к разным задачам. RLOO-LP (Reinforcement Learning Optimized for Output Length with Linear Penalty) использует обучение с подкреплением для оптимизации штрафа, стремясь к минимизации затрат на вычисления при сохранении качества ответа. DRPO (Differentiable Reward-Penalty Optimization) отличается тем, что нормализует сигнал вознаграждения с помощью DisCO, что позволяет более точно контролировать длину без ущерба для оптимизации целевой функции. Каждый из этих методов имеет свои преимущества и недостатки в зависимости от специфики задачи и вычислительных ресурсов.
Метод DRPO (Decoupled Reward Penalty Optimization) использует нормализацию DisCO (Diversity-promoting Contrastive Objective) для отделения оптимизации вознаграждения от ограничений по длине генерируемого текста. Это достигается за счет применения DisCO для нормализации вектора признаков, что позволяет модели более эффективно оптимизировать вознаграждение, не будучи жестко ограниченной длиной. В результате, DRPO обеспечивает более точный контроль над длиной выходных данных, позволяя модели генерировать тексты оптимальной длины для достижения максимальной производительности и точности, без необходимости прямого штрафования за длину в функции потерь.
Методы контроля длины, такие как DRPO, ALP и RLOO-LP, непосредственно влияют на процесс рассуждений типа “Цепочка Мыслей” (Chain-of-Thought Reasoning), изменяя способ генерации текста для повышения эффективности. Вместо полного отказа от детального анализа, эти методы вводят штрафы или поощрения, которые регулируют длину генерируемых последовательностей токенов. Такой подход позволяет модели фокусироваться на наиболее релевантной информации, избегая избыточных повторений или ненужных деталей, что приводит к сокращению вычислительных затрат и времени генерации, при этом сохраняя или даже улучшая точность и качество конечного результата. Модификация процесса рассуждений происходит на уровне алгоритма генерации, а не путем упрощения или искажения логики.
Количественная Оценка Качества Рассуждений: Измерение Дисперсии и Точности
Показатели энтропии ответа (Answer Entropy) и дисперсии вывода (Output Dispersion) позволяют оценить вариативность генерируемых ответов, сигнализируя о возможных проблемах с согласованностью рассуждений. В частности, при анализе модели DeepSeek-R1-Distill-Qwen-1.5B наблюдается увеличение энтропии ответа и одновременное снижение дисперсии вывода в режиме генерации длинных ответов. Это указывает на то, что модель начинает предлагать более разнообразные ответы при увеличении их длины, при этом степень расхождения между этими ответами уменьшается. Увеличение энтропии может свидетельствовать о снижении уверенности модели в своих ответах, в то время как снижение дисперсии указывает на тенденцию к более консистентным, хотя и разнообразным, решениям.
Метрики «Точность моды» (Mode Accuracy) и «Доля моды» (Mode Share) используются для оценки частоты, с которой наиболее распространенный ответ является верным, предоставляя практический показатель надежности рассуждений модели. В частности, анализ модели DeepSeek-R1-Distill-Qwen-1.5B показывает, что при увеличении длины генерируемого ответа (в «длинном режиме» вывода) «Точность моды» остается стабильной или даже незначительно возрастает, в то время как «Доля моды» снижается. Это указывает на то, что хотя модель чаще генерирует правильный ответ как наиболее вероятный, доля случаев, когда этот наиболее вероятный ответ действительно доминирует в распределении ответов, уменьшается.
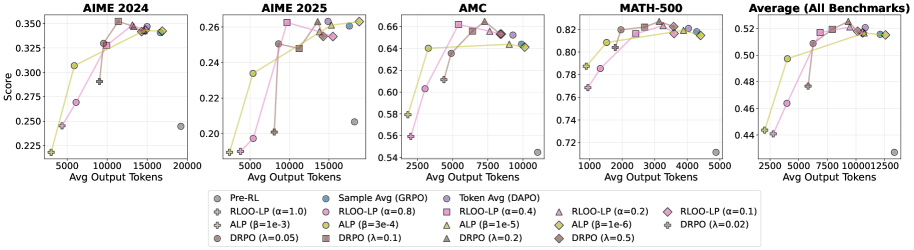
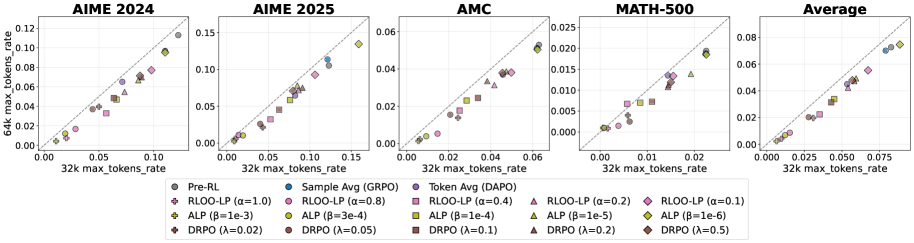
Применение метрик, таких как энтропия ответа (Answer Entropy), дисперсия вывода (Output Dispersion), точность моды (Mode Accuracy) и доля моды (Mode Share), к моделям Qwen3-1.7B-Base и DeepSeek-R1-Distill-Qwen-1.5B, позволило получить эмпирические данные, подтверждающие преимущества контролируемого рассуждения. Анализ этих показателей демонстрирует, что оптимизация, направленная на управление длиной генерируемых ответов, приводит к повышению согласованности и надежности результатов, особенно в задачах, требующих сложных логических выводов и математических расчетов. Данные, полученные на бенчмарках AIME 2024, AIME 2025, AMC и MATH-500, указывают на корреляцию между снижением вариативности ответов и улучшением общей производительности моделей.
Оценка модели проводилась на стандартных бенчмарках, включающих AIME 2024, AIME 2025, AMC и MATH-500, что позволило продемонстрировать влияние оптимизации, учитывающей длину генерируемого текста, на итоговую производительность. Весь процесс обучения модели занял 576 GPU-часов, что эквивалентно использованию 8 графических процессоров в течение 72 часов. Данные результаты подтверждают эффективность предложенного подхода к обучению и позволяют оценить требуемые вычислительные ресурсы для достижения сопоставимых результатов.

Совершенствование Рассуждений с Использованием Обучения с Подкреплением
Метод обучения с подкреплением представляет собой мощный инструмент для оптимизации способности больших языковых моделей (LLM) к рассуждениям. В отличие от традиционных методов обучения, которые полагаются на заранее размеченные данные, обучение с подкреплением позволяет модели учиться на основе обратной связи, получаемой в процессе взаимодействия со средой. Этот процесс имитирует обучение человека, где модель получает “награды” за правильные шаги в рассуждениях и “штрафы” за ошибки, постепенно улучшая свою способность решать сложные задачи. Подобный подход позволяет LLM не просто генерировать текст, но и адаптировать свои стратегии рассуждений, повышая точность и эффективность ответов с течением времени, что открывает новые возможности для создания интеллектуальных систем.
Для усовершенствования логических способностей больших языковых моделей (LLM) применяются алгоритмы, такие как GRPO и DAPO, которые позволяют корректировать процесс рассуждений, делая его более последовательным и точным. Эти алгоритмы работают, оценивая и улучшая шаги, предпринятые моделью для достижения решения. Одновременно с этим, вводится система штрафов, зависящая от длины ответа — это стимулирует LLM генерировать лаконичные и при этом содержательные ответы, избегая излишней детализации и повторений. Такой подход позволяет не только повысить качество рассуждений, но и оптимизировать вычислительные ресурсы, делая модель более эффективной и пригодной для решения сложных задач, требующих как точности, так и краткости изложения.
Сочетание обучения с подкреплением и методов контроля длины генерируемого текста открывает новые перспективы для создания больших языковых моделей, демонстрирующих как высокую производительность, так и эффективность. Такой подход позволяет не просто увеличивать вычислительные ресурсы, но и оптимизировать сам процесс рассуждений модели. В результате, создаются системы, способные решать сложные задачи, генерируя при этом лаконичные и точные ответы. Это особенно важно для приложений, где важна не только правильность решения, но и скорость его получения, а также минимизация потребляемых ресурсов. Подобная оптимизация позволяет LLM эффективно обрабатывать большие объемы информации и находить оптимальные решения в различных областях, от научных исследований до практического применения в промышленности и повседневной жизни.
Вместо простого увеличения размеров языковых моделей, современные исследования направлены на создание действительно интеллектуальных систем, способных к тонкому и надежному рассуждению. Такой подход предполагает отход от стратегии, где улучшение производительности достигается исключительно за счет увеличения количества параметров, и переход к методам, оптимизирующим сам процесс логического мышления. Обучение с подкреплением позволяет моделям не просто генерировать текст, но и учиться на собственных ошибках, постепенно совершенствуя способность к анализу, синтезу и принятию обоснованных решений. Это открывает путь к созданию искусственного интеллекта, который способен не только имитировать человеческий разум, но и демонстрировать подлинное понимание и способность к решению сложных задач, требующих не просто обработки данных, а глубокого анализа и логических выводов.
Исследование демонстрирует, что оптимальная длина рассуждений в моделях, обученных с подкреплением, не является линейной. Слишком короткие или, наоборот, чрезмерно длинные выводы могут негативно сказаться на производительности. Этот принцип перекликается с мыслью Брайана Кернигана: «Простота — это высшая степень совершенства». В контексте данной работы, краткость и ясность рассуждений, основанных на математической непротиворечивости, являются ключом к достижению оптимальных результатов. Истинная элегантность алгоритма, как показывает исследование, заключается не в его объеме, а в точности и лаконичности представления логической цепочки.
Куда двигаться дальше?
Настоящая проблема, вытекающая из представленного анализа, заключается не в поиске “оптимальной длины” рассуждений, а в осознании, что само понятие “оптимальности” нуждается в пересмотре. Недостаточно просто контролировать длину вывода; необходимо понимать, качество этого вывода, что, в свою очередь, требует более глубокого погружения в математические основы рассуждений моделей. Оптимизация без анализа — это самообман и ловушка для неосторожного разработчика. Простое увеличение масштаба моделей не решит фундаментальную проблему: способны ли они к истинно логическому выводу, или же они лишь искусно манипулируют статистическими закономерностями?
Дальнейшие исследования должны сосредоточиться на разработке метрик, способных оценивать не только “правильность” ответа, но и обоснованность процесса рассуждения. Необходимо исследовать, как различные методы обучения с подкреплением влияют на внутреннюю структуру рассуждений модели, и как эта структура связана с ее способностью к обобщению. Важно также учитывать, что не существует универсальной “оптимальной длины”; она зависит от сложности задачи и от внутренних характеристик модели.
В конечном счете, успех в этой области будет зависеть от способности выйти за рамки эмпирических наблюдений и создать математически строгую теорию рассуждений в больших языковых моделях. Только тогда можно будет говорить о действительно “оптимальных” решениях, а не просто о тех, которые хорошо работают на текущем наборе тестов.
Оригинал статьи: https://arxiv.org/pdf/2602.09591.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Внимание в сети: Новый подход к ускорению больших языковых моделей
- Искусственный нос будущего: как квантовая механика и машинное обучение распознают запахи
- Химический синтез под контролем искусственного интеллекта: новые горизонты
- Внимание на границе: почему трансформеры нуждаются в «поглотителях»
- S-Chain: Когда «цепочка рассуждений» в медицине ведёт к техдолгу.
- Язык тела под присмотром ИИ: архитектура и гарантии
- Творческий процесс под микроскопом: от логов к искусственному интеллекту
- Плоские зоны: от теории к новым материалам
- Наука, управляемая интеллектом: новая эра открытий
- Генетическая приоритизация: новый взгляд на отбор генов
2026-02-12 05:18