Автор: Денис Аветисян
Новый метод позволяет сбалансировать креативность и безопасность больших языковых моделей, минимизируя вероятность воспроизведения защищенного авторским правом контента.
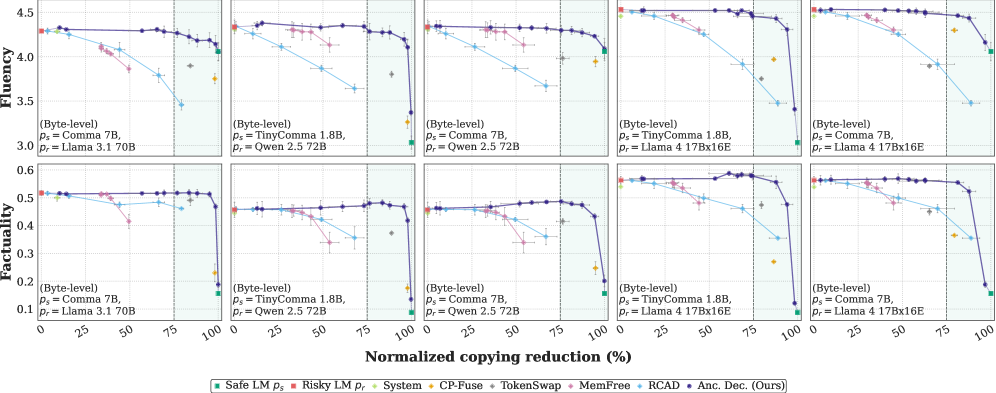
В статье представлен Anchored Decoding — подход, использующий KL-дивергенцию и адаптивное бюджетирование для контролируемой генерации текста.
Современные языковые модели, обладая впечатляющей способностью к генерации текста, нередко склонны к запоминанию фрагментов обучающих данных и их дословному воспроизведению. В статье ‘Anchored Decoding: Provably Reducing Copyright Risk for Any Language Model’ предложен метод Anchored Decoding — алгоритм, позволяющий снизить риск нарушения авторских прав, ограничивая генерацию вблизи безопасной, разрешительно лицензированной модели, при этом сохраняя полезные свойства «рискованной» модели. Разработанный подход обеспечивает управляемый компромисс между риском и качеством генерации, снижая до 75% воспроизведения скопированного контента по шести различным метрикам. Не откроет ли это новую эру в разработке надежных и этичных больших языковых моделей?
Баланс между свободой и ограничениями: этика генерации текста
Современные большие языковые модели, такие как Llama 3.1 70B, демонстрируют впечатляющую способность к генерации текста и решению разнообразных задач. Однако, в процессе обучения на обширных массивах данных, они неизбежно сталкиваются с материалами, защищенными авторским правом. Это создает риск непроизвольного воспроизведения фрагментов этих материалов в генерируемом тексте, что может привести к юридическим последствиям. Несмотря на сложность точного определения границ авторского права в цифровом пространстве, разработчики сталкиваются с необходимостью поиска баланса между мощностью модели и соблюдением законодательства, чтобы обеспечить безопасное и этичное использование этих передовых технологий.
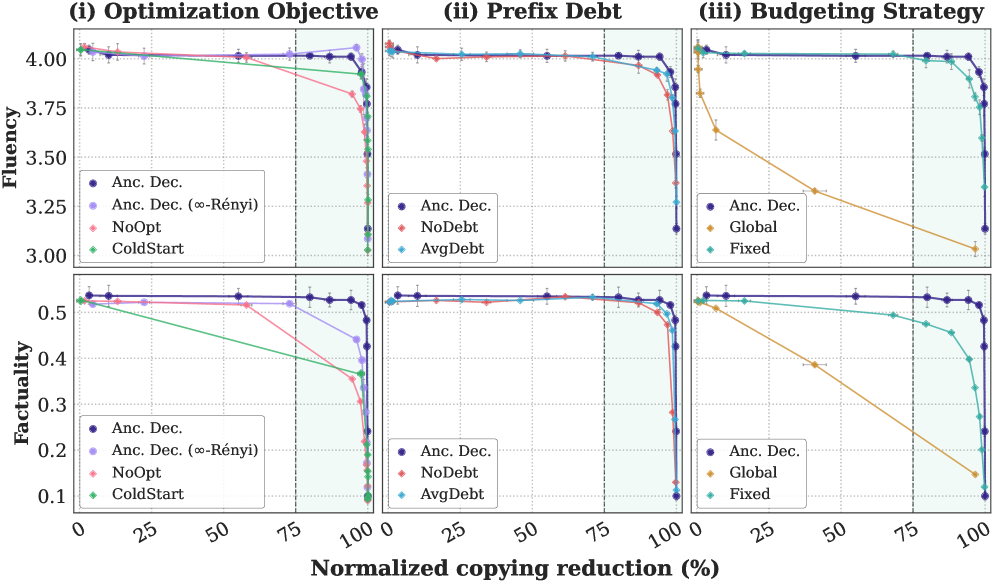
Традиционные методы снижения риска воспроизведения защищенного авторским правом материала в больших языковых моделях зачастую приводят к значительному снижению их полезности. Стремление к абсолютной безопасности, достигаемое путем жесткой фильтрации и ограничений, приводит к тому, что модель становится менее креативной, менее способной генерировать сложные и разнообразные тексты, а также менее отзывчивой на запросы пользователя. Это особенно заметно в задачах, требующих творческого подхода или детального анализа, где ограничения, направленные на предотвращение нарушения авторских прав, подавляют способность модели к генерации оригинального и информативного контента. Таким образом, возникает парадокс: инструменты, призванные помогать в создании контента, становятся менее эффективными в этом процессе из-за излишней предосторожности.
Основная сложность в создании безопасных языковых моделей заключается в поддержании баланса между исходной, потенциально рискованной версией и её безопасным аналогом. Неконтролируемое стремление к безопасности часто приводит к значительному снижению качества генерируемого текста, лишая модель её полезных возможностей. Исследователи и разработчики сталкиваются с задачей минимизировать расхождение между двумя версиями, чтобы обеспечить как высокую производительность, так и соответствие юридическим нормам, касающимся авторских прав и интеллектуальной собственности. Решение этой проблемы требует разработки инновационных методов обучения и контроля, позволяющих эффективно снижать вероятность воспроизведения защищенного контента, не жертвуя при этом способностью модели генерировать осмысленный и полезный текст.
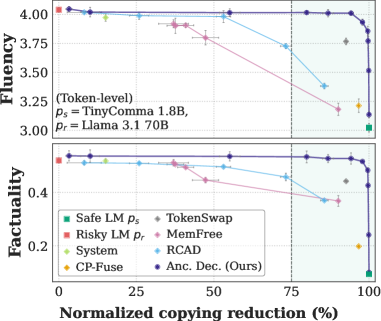
Якорная Декодировка: контролируемая генерация текста
Метод «Якорной Декодировки» (Anchored Decoding) предполагает интерполяцию между двумя языковыми моделями — «безопасной» и «рискованной» — посредством параметра бюджета K. Этот параметр определяет степень отклонения генерируемого текста от распределения вероятностей, предсказанного «безопасной» моделью. Увеличение значения K позволяет генерировать более разнообразный и потенциально полезный текст, используя возможности «рискованной» модели, однако также увеличивает вероятность генерации нежелательного или небезопасного контента. Значение K выступает в качестве регулятора, обеспечивающего баланс между качеством и безопасностью генерируемого текста, позволяя контролировать степень влияния каждой из моделей.
Подход, используемый в Anchored Decoding, заключается в комбинировании преимуществ двух языковых моделей. Первая модель, характеризующаяся более высокой степенью безопасности, обеспечивает генерацию текста, соответствующего заданным ограничениям и снижающего вероятность нежелательных результатов, таких как нарушение авторских прав. Вторая модель, обладающая большей гибкостью, способна генерировать более креативный и информативный текст, однако сопряжена с повышенным риском отклонения от безопасных границ. Комбинирование этих моделей позволяет достичь баланса между безопасностью и полезностью генерируемого текста, используя сильные стороны каждой из них.
Метод контролируемой генерации текста использует дивергенцию Кулбака-Лейблера (KL Divergence) для обеспечения определенного уровня защиты авторских прав. Регулируя расхождение между генерируемым текстом и безопасной языковой моделью, достигается баланс между риском нарушения авторских прав и полезностью генерируемого контента. Экспериментальные данные демонстрируют возможность получения парето-оптимального компромисса между этими параметрами, позволяя пользователю настраивать генерацию в соответствии с требуемым уровнем безопасности и полезности. KL(P||Q) = \sum_{i} P(i) \log \frac{P(i)}{Q(i)} — формула, определяющая меру расхождения между распределениями вероятностей P и Q, используемая в данном подходе.
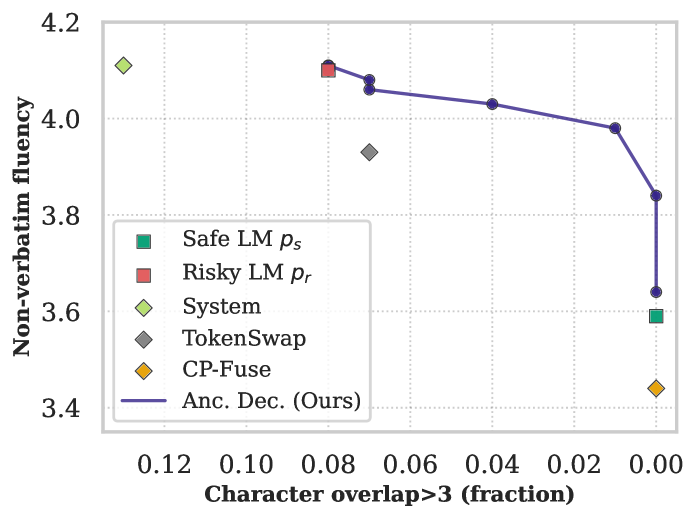
Байтовый уровень точности: повышение безопасности и совместимости
Декодирование на уровне байтов, реализованное посредством ByteSampler, обеспечивает совместимость между моделями, использующими различные токенизаторы. Вместо работы с дискретными токенами, ByteSampler оперирует непосредственно с байтами, что позволяет избежать проблем, связанных с несоответствием словарей токенов разных моделей. Это дает возможность точно контролировать генерируемый контент, поскольку каждая байтовая последовательность может быть точно определена и обработана, независимо от используемой модели токенизации. Такой подход особенно важен при работе с многоязычными моделями или при интеграции моделей, обученных на разных наборах данных, где различия в токенизации могут привести к непредсказуемым результатам.
Расчет расхождения Кульбака-Лейблера (KL Divergence) на уровне байтов обеспечивает более детальную оценку различий между распределениями вероятностей, чем традиционные методы, оперирующие токенами. Это позволяет выявлять даже незначительные отклонения в генерируемом тексте, что критически важно для повышения безопасности моделей. В отличие от анализа на уровне токенов, байтовый анализ учитывает все возможные комбинации байтов, что делает его более чувствительным к потенциально опасным или нежелательным последовательностям. Использование KL Divergence (Byte-Level) позволяет более точно контролировать и ограничивать генерацию контента, снижая вероятность появления небезопасных или вредоносных текстов.
Байтовый подход бесшовно интегрирован с Anchored Decoding, расширяя его возможности и применимость к более широкому спектру моделей. Данная интеграция позволяет значительно снизить сходство MinHash по сравнению с базовыми методами. В частности, использование байтового сэмплирования в сочетании с Anchored Decoding обеспечивает более точную оценку и контроль над генерируемым контентом, что приводит к уменьшению вероятности генерации нежелательных или небезопасных последовательностей. Наблюдаемое снижение MinHash указывает на более выраженное различие между генерируемым текстом и исходными данными, что является важным показателем эффективности механизма безопасности.
Оптимизация бюджетов безопасности с помощью адаптивного контроля
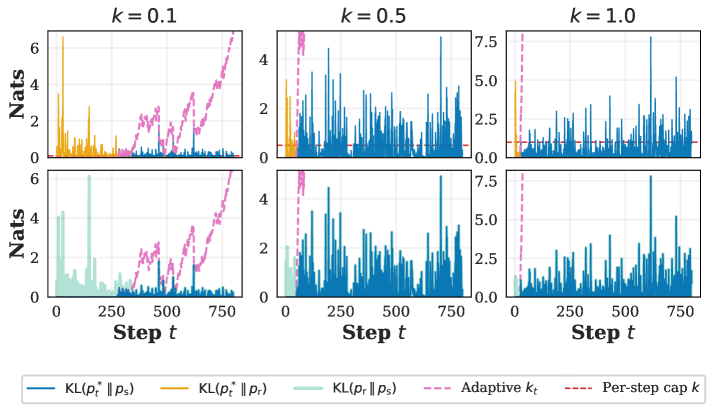
Адаптивное бюджетирование представляет собой динамический подход к управлению бюджетом безопасности K, основанный на оценке расхождения на каждом шаге генерации текста. Вместо использования фиксированного бюджета, система непрерывно корректирует K в зависимости от степени отклонения от безопасной траектории. Это позволяет более эффективно использовать доступные ресурсы, поскольку бюджет безопасности увеличивается в тех случаях, когда модель демонстрирует тенденцию к отклонению от желаемого поведения, и уменьшается, когда модель генерирует текст, соответствующий заданным ограничениям. Такой подход не только снижает вычислительные затраты, но и способствует повышению надежности и безопасности генерируемого контента, обеспечивая оптимальный баланс между креативностью и соблюдением установленных норм.
Методика “Префиксного Долга” позволяет усовершенствовать процесс адаптивного бюджетирования, снижая начальный бюджет безопасности, основываясь на вероятности копирования материала из рискованной модели. Данный подход учитывает, что при высокой вероятности копирования, начальный бюджет может быть уменьшен без ущерба для общей безопасности. Исследования показали положительную корреляцию между применением “Префиксного Долга” и индикаторами, свидетельствующими о копировании авторских материалов, что подтверждает эффективность данной методики в управлении рисками и оптимизации использования ресурсов. Таким образом, “Префиксный Долг” не только повышает экономичность системы, но и способствует более точному контролю за соблюдением авторских прав.
Оптимизация бюджета безопасности, основанная на адаптивном контроле, позволяет максимально эффективно использовать потенциал рискованной модели, не нарушая заданные ограничения по безопасности. Исследования демонстрируют, что с увеличением параметра k — уровня допустимого отклонения — наблюдается устойчивое повышение точности фактической информации (FActScore) во всех категориях частоты сущностей. Кроме того, зафиксировано улучшение показателей ROUGE-1 и ROUGE-L, которые оценивают качество генерируемого текста с точки зрения перекрытия с эталонными текстами. Данные результаты подтверждают, что предлагаемый подход не только обеспечивает соблюдение мер безопасности, но и способствует повышению общей эффективности и качества работы модели, позволяя ей генерировать более точные и релевантные тексты.
К ответственной разработке больших языковых моделей
Сочетание методов привязанной декодировки, байтового контроля и адаптивного бюджетирования открывает новые возможности для раскрытия всего потенциала больших языковых моделей, одновременно снижая риски, связанные с авторским правом. Привязанная декодировка позволяет направлять процесс генерации текста, гарантируя соответствие заданным критериям и избегая нежелательных результатов. Байтовый контроль обеспечивает точное управление выходными данными, предотвращая воспроизведение защищенного авторским правом контента на уровне отдельных байтов. Адаптивное бюджетирование динамически регулирует вычислительные ресурсы, выделяемые для генерации, оптимизируя баланс между качеством и соблюдением юридических ограничений. Данный комплексный подход позволяет создавать мощные и безопасные языковые модели, способные к инновациям, не нарушая при этом интеллектуальную собственность других лиц.
Гарантия KK-NAF представляет собой формальное подтверждение безопасности, позволяющее уверенно внедрять большие языковые модели в чувствительных областях применения. В её основе лежит математически обоснованная система, которая строго контролирует генерацию текста, предотвращая несанкционированное воспроизведение защищенного контента. Эта гарантия не просто декларирует безопасность, а предоставляет проверяемый механизм, подтверждающий, что выходные данные модели соответствуют заданным ограничениям и не нарушают авторские права. В результате, разработчики и пользователи могут с большей уверенностью полагаться на большие языковые модели в таких критических областях, как здравоохранение, финансы и юридическая практика, зная, что риск нежелательных последствий сведен к минимуму.
Предлагаемый подход к разработке больших языковых моделей представляет собой масштабируемую и адаптируемую основу, позволяющую стимулировать инновации без ущерба для юридических и этических норм. В отличие от жестких, негибких систем, данная архитектура позволяет динамически корректировать параметры и стратегии в процессе разработки и развертывания, что особенно важно в быстро меняющемся ландшафте искусственного интеллекта. Гибкость подхода позволяет интегрировать новые методы защиты авторских прав и механизмы обеспечения безопасности по мере их появления, а также адаптироваться к различным требованиям конкретных приложений. Благодаря этому, разработчики получают возможность создавать мощные и полезные языковые модели, уверенно соблюдая при этом правовые рамки и принципы ответственного использования технологий.
Исследование представляет собой любопытную попытку обуздать хаос генеративных моделей, применив принцип «якорения». Авторы предлагают способ балансировать между творческим потенциалом и юридическими рисками, ограничивая выходные данные, но не подавляя их полностью. Этот подход напоминает о словах Клода Шеннона: «Информация — это физическое явление». В данном случае, информация — это текст, а «якорение» — способ управления физической реализацией этого текста, чтобы избежать нежелательных последствий. По сути, это своего рода реверс-инжиниринг процесса генерации, направленный на предсказуемость и контроль, а значит, на взлом системы ограничений, навязанных авторским правом.
Куда Дальше?
Представленный подход, безусловно, демонстрирует элегантный способ обуздать непредсказуемость больших языковых моделей. Однако, попытка свести риски нарушения авторских прав к математической оптимизации — это всегда лишь приближение к реальности. Защита от копирования, основанная на расхождениях в дивергенциях Кулбака-Лейблера и Рени, выглядит стройно, но не учитывает тонкостей юридической интерпретации и контекста использования сгенерированного текста. По сути, это очередная гонка вооружений, где каждая новая защита порождает новые методы обхода.
Наиболее интересным направлением представляется не столько совершенствование алгоритмов «якорения» (Anchored Decoding), сколько разработка систем, способных динамически оценивать и учитывать риски в реальном времени. Адаптивное бюджетирование, упомянутое в работе, — лишь первый шаг. Необходимо создавать модели, которые не просто избегают прямого копирования, но и способны генерировать контент, принципиально отличающийся от существующего, не просто по форме, а по смыслу. Иначе мы рискуем создать лишь более изощренные инструменты для плагиата.
В конечном итоге, истинный прогресс заключается не в укрощении хаоса, а в его понимании. Разработка моделей, способных осознанно генерировать «белый шум», не имеющий аналогов в существующей информационной среде, представляется более перспективной задачей, чем попытки построить идеальную систему защиты от копирования. Ведь иногда лучший способ избежать нарушения — это создать нечто принципиально новое.
Оригинал статьи: https://arxiv.org/pdf/2602.07120.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Понимание мира в динамике: новая модель для анализа 4D-данных
- Искусственный интеллект на службе редких болезней
- Плоские зоны: от теории к новым материалам
- Генерация без рисков: как избежать нарушения авторских прав при работе с языковыми моделями
- S-Chain: Когда «цепочка рассуждений» в медицине ведёт к техдолгу.
- Самообучающиеся агенты: новый подход к автономным системам
- Искусственный интеллект в разговоре: что обсуждают друг с другом AI?
- Квантовые амбиции: Иран вступает в гонку
- Язык тела под присмотром ИИ: архитектура и гарантии
- Раскрывая логику нейросетей: Графы причинно-следственных связей
2026-02-10 23:27