Автор: Денис Аветисян
Исследователи предлагают инновационный метод автоматической генерации разнообразных и достоверных задач для оценки возможностей больших языковых моделей.

Представлен InfoSynth — конвейер, использующий генетические алгоритмы и выполнение кода для создания бенчмарков, позволяющих более точно оценить производительность языковых моделей в задачах программирования.
Создание новых, надежных бенчмарков для оценки возможностей больших языковых моделей (LLM) остается сложной задачей, требующей значительных затрат времени и ресурсов. В данной работе представлена система InfoSynth: Information-Guided Benchmark Synthesis for LLMs, автоматизирующий процесс генерации бенчмарков на основе информационно-теоретических принципов и генетических алгоритмов. Предложенный подход позволяет создавать разнообразные и новые задачи по программированию на Python с автоматической верификацией корректности решений, демонстрируя высокую эффективность и превосходя традиционные методы по показателям новизны и разнообразия. Возможно ли с помощью InfoSynth создать действительно универсальный набор бенчмарков, способный объективно оценить все грани возможностей современных LLM?
Истинная Сущность Бенчмарков: Преодоление Стагнации
Существующие наборы данных для оценки моделей кодирования часто страдают от недостатка новизны и разнообразия, что серьезно ограничивает их способность достоверно оценивать обобщающую способность этих моделей. Вместо того, чтобы проверять умение решать принципиально новые задачи, многие тесты повторяют уже известные паттерны, позволяя моделям достигать высоких показателей за счет запоминания, а не истинного понимания кода. Это приводит к ситуации, когда кажущийся прогресс может быть обманчивым, поскольку модели становятся все лучше в решении узкого круга задач, но не демонстрируют улучшения в способности адаптироваться к новым, не встречавшимся ранее проблемам. В результате, текущие бенчмарки не всегда отражают реальный потенциал моделей в практических сценариях разработки, где требуется решение разнообразных и нестандартных задач.
Повторное использование одних и тех же или очень похожих задач в процессе оценки моделей машинного обучения приводит к феномену насыщения, когда показатели производительности перестают отражать реальный прогресс в понимании кода. Модели, будучи многократно обученными на схожих примерах, достигают плато, демонстрируя высокие результаты, которые не переносятся на новые, ранее не встречавшиеся задачи. Это создает иллюзию значительного улучшения, маскируя отсутствие способности к обобщению и адаптации к незнакомым ситуациям. Таким образом, стандартные метрики, основанные на ограниченном наборе задач, становятся ненадежными индикаторами истинного интеллекта и способности модели решать сложные задачи кодирования.
В настоящее время существует острая необходимость в автоматизированных методах генерации эталонов, способных расширить границы понимания кода. Существующие подходы к оценке моделей часто опираются на статические наборы задач, что приводит к насыщению и завышенным показателям производительности. Автоматическая генерация эталонов позволяет создавать разнообразные и сложные задачи, требующие от моделей не просто запоминания паттернов, а истинного понимания логики и принципов программирования. Разработка таких систем предполагает использование алгоритмов, способных создавать задачи различной сложности, охватывающие широкий спектр алгоритмических и структурных решений, и обеспечивающих возможность верификации корректности полученных ответов. Это позволит более точно оценивать способности моделей к обобщению и решению новых, ранее не встречавшихся проблем, стимулируя дальнейший прогресс в области искусственного интеллекта и разработки программного обеспечения.
Современные методы автоматической генерации кодовых задач сталкиваются с существенной проблемой баланса между новизной, разнообразием и возможностью проверки корректности решений. Стремление к созданию уникальных и сложных задач часто приводит к снижению их верифицируемости — автоматизированная проверка становится затруднительной, а ручная — трудоемкой и подверженной ошибкам. В то же время, задачи, легко поддающиеся автоматизированной проверке, нередко оказываются недостаточно разнообразными или лишены новизны, что ограничивает их способность выявлять истинный прогресс в области понимания кода моделями. Таким образом, достижение оптимального сочетания этих трех ключевых характеристик остается сложной задачей, требующей разработки инновационных подходов к генерации кодовых бенчмарков.
InfoSynth: Архитектура Автоматической Генерации Бенчмарков
В основе InfoSynth лежит использование модели GPT-4o для первоначальной генерации задач по программированию и соответствующих им решений. GPT-4o выступает в роли инициатора, предлагая базовые конструкции задач и их реализации, которые затем подвергаются дальнейшей обработке и оптимизации в рамках конвейера. Модель позволяет создавать разнообразные задачи, охватывающие различные алгоритмы и структуры данных, обеспечивая начальный набор данных для последующего этапа эволюции и тестирования. Генерация происходит на основе анализа больших объемов кода и алгоритмических шаблонов, что позволяет создавать задачи, приближенные к реальным сценариям разработки.
Для интеллектуального исследования пространства задач используется генетический алгоритм. Этот алгоритм создает новые экземпляры задач путем итеративного применения операций, аналогичных естественному отбору. Каждый экземпляр задачи оценивается на основе заданных критериев пригодности (fitness criteria), таких как сложность, разнообразие и соответствие заданным ограничениям. Экземпляры с более высоким рейтингом пригодности отбираются для создания следующего поколения задач, в процессе которого происходит скрещивание и мутация для создания новых, потенциально более оптимальных решений. Этот процесс повторяется до достижения желаемого уровня разнообразия и качества генерируемых задач.
Процесс итеративной проверки кода в InfoSynth включает в себя многократное тестирование сгенерированных решений с использованием принципов рассуждений «chain-of-thought». Этот подход подразумевает, что система не просто оценивает корректность результата, но и анализирует ход выполнения кода, выявляя потенциальные ошибки и логические неточности. При обнаружении неверного ответа или ошибки, система генерирует объяснения шагов, которые привели к проблеме, и использует эту информацию для корректировки кода. Повторение циклов тестирования и отладки на основе логического анализа позволяет значительно повысить надежность и точность генерируемых решений, а также обеспечить более эффективную отладку и исправление ошибок.
После генерации задач и решений, применяется этап постобработки, включающий несколько проверок. Во-первых, проводится анализ на предмет ясности формулировки, чтобы исключить двусмысленность и обеспечить однозначное понимание условия задачи. Во-вторых, выполняется верификация корректности сгенерированных решений на основе тестовых данных и логического анализа. В-третьих, осуществляется контроль соответствия уровня сложности задачи заданным параметрам, с возможной автоматической корректировкой параметров или перегенерацией задачи в случае несоответствия. Эти шаги направлены на обеспечение высокого качества и пригодности сгенерированных задач для использования в образовательных и исследовательских целях.
Оценка Качества Бенчмарков: Новизна и Разнообразие
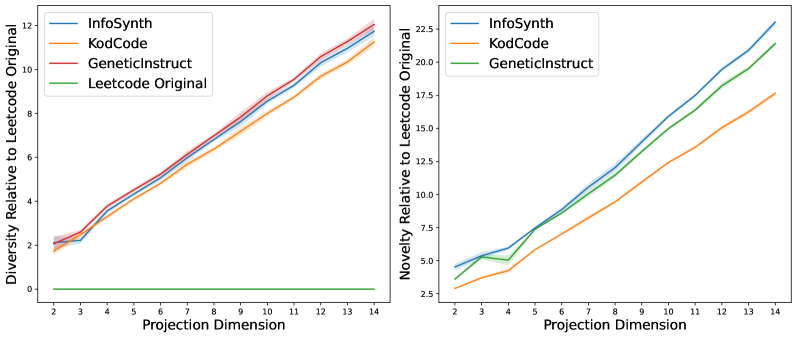
Для оценки новизны и разнообразия генерируемых бенчмарков используются метрики KL-дивергенции и энтропии Шеннона. KL-дивергенция D_{KL}(P||Q) измеряет разницу между распределением сгенерированных задач и распределением задач в базовых наборах данных, а энтропия Шеннона H(X) количественно определяет степень случайности и разнообразия в сгенерированных задачах. Экспериментальные результаты демонстрируют, что предложенный подход обеспечивает более высокую новизну и разнообразие генерируемых бенчмарков по сравнению с существующими наборами данных и альтернативными методами генерации, что подтверждается более низкими значениями KL-дивергенции и более высокими значениями энтропии Шеннона для сгенерированных бенчмарков.
Для визуальной оценки характеристик генерируемых бенчмарков используется метод снижения размерности UMAP (Uniform Manifold Approximation and Projection). UMAP позволяет отобразить многомерные данные бенчмарков на плоскости, сохраняя при этом их топологическую структуру. Это обеспечивает возможность наглядного сравнения генерируемых бенчмарков с существующими наборами данных, выявляя области перекрытия и уникальности. Визуализация, полученная с помощью UMAP, помогает оценить степень разнообразия и покрытия пространства задач, обеспечивая более глубокое понимание качества генерируемых бенчмарков по сравнению с традиционными метриками.
Алгоритмы K-ближайших соседей (K-NN) используются на этапе фильтрации с целью исключения из генерируемого набора задач тех, которые слишком похожи на существующие. Реализация K-NN позволяет вычислить расстояние между каждой сгенерированной задачей и всеми задачами из базового набора данных или ранее сгенерированных задач. Задачи, имеющие небольшое среднее расстояние до k ближайших соседей, отбрасываются, что способствует повышению новизны и разнообразия итогового бенчмарка. Кроме того, K-NN используется как вспомогательный инструмент при вычислении метрик новизны и разнообразия, предоставляя информацию о плотности распределения задач в пространстве признаков.
Для обеспечения высокой уникальности генерируемого набора данных используется алгоритмический подход, основанный на MinHash и Locality Sensitive Hashing (LSH). MinHash позволяет эффективно вычислять схожесть между задачами путем создания их сигнатур фиксированной длины. LSH, в свою очередь, служит для быстрого поиска задач с близкими сигнатурами, что позволяет идентифицировать и отфильтровать дубликаты или задачи, демонстрирующие высокую степень сходства. Данный метод позволяет существенно снизить избыточность в генерируемом наборе данных, гарантируя, что каждая задача вносит вклад в общее разнообразие и сложность бенчмарка.

Влияние и Перспективы Развития
Система InfoSynth предоставляет возможность создания специализированных бенчмарков, адаптированных под конкретные уровни подготовки и образовательные цели. В отличие от стандартных наборов задач, часто представляющих собой усредненный уровень сложности, InfoSynth позволяет точно настраивать сложность и тематику тестов. Это достигается благодаря автоматизированному конвейеру, который генерирует задачи, соответствующие заданным параметрам, будь то проверка базовых навыков программирования или оценка способности решать сложные алгоритмические задачи. Такая гибкость позволяет разработчикам и преподавателям создавать индивидуальные траектории обучения и более точно оценивать прогресс обучающихся, а также более эффективно выявлять слабые места в знаниях и навыках.
Автоматизированный конвейер, лежащий в основе InfoSynth, значительно снижает трудозатраты, связанные с созданием и поддержанием эталонов для оценки моделей. Традиционно, разработка качественных тестов требовала значительных усилий экспертов, включая ручную генерацию задач, проверку корректности решений и постоянную адаптацию к новым технологиям. InfoSynth же позволяет автоматизировать практически все этапы этого процесса — от формирования разнообразных проблемных ситуаций до оценки качества предлагаемых решений. Это не только экономит время и ресурсы, но и обеспечивает возможность масштабирования процесса создания эталонов, позволяя оперативно реагировать на изменения в области искусственного интеллекта и поддерживать актуальность тестов. В результате, разработчики моделей получают возможность более эффективно оценивать и совершенствовать свои системы, а исследователи — получать более надежные и объективные результаты.
Система InfoSynth способствует развитию устойчивой обобщающей способности моделей и предотвращает переобучение за счет постоянного предоставления новых и разнообразных задач. Вместо того, чтобы модели тренировались на ограниченном наборе данных, InfoSynth динамически генерирует проблемы, требующие адаптации к различным сценариям и условиям. Этот подход заставляет модели учиться не просто запоминать решения, а понимать лежащие в их основе принципы, что значительно повышает их способность эффективно работать с ранее не встречавшимися данными. Постоянное усложнение задач и расширение спектра решаемых проблем позволяет избежать узкой специализации и гарантирует, что модель сохранит высокую производительность даже при изменении входных параметров или контекста.
Исследования показали, что внедрение итеративного механизма обратной связи значительно повышает качество генерируемых решений. Процесс, в котором система анализирует результаты выполнения кода и корректирует последующие попытки, приводит к измеримому увеличению процента успешного прохождения тестов. В частности, применение дополнительных этапов постобработки, направленных на оптимизацию и исправление наиболее частых ошибок, демонстрирует прирост точности в пределах 5-15% у различных моделей, используемых в качестве испытуемых. Это свидетельствует о том, что система не просто генерирует код, но и активно совершенствует его, обеспечивая более надежные и эффективные решения, что критически важно для дальнейшего развития и применения подобных технологий.
Представленная работа демонстрирует стремление к созданию детерминированных и проверяемых тестов для оценки больших языковых моделей. Авторы подчеркивают важность не просто достижения работоспособности, но и доказательства корректности генерируемого кода. Как однажды заметила Барбара Лисков: «Хороший дизайн — это когда система может быть изменена без влияния на другие части». Этот принцип напрямую применим к InfoSynth, поскольку система генерирует разнообразные и независимые тесты, что позволяет более точно оценить надежность и предсказуемость LLM, избегая ложноположительных результатов, возникающих при использовании недостаточно продуманных наборов данных. Важность верификации и воспроизводимости результатов, лежащая в основе InfoSynth, полностью соответствует принципам строгой математической чистоты, к которой стремится качественный код.
Что Дальше?
Представленный подход, хотя и демонстрирует способность генерировать бенчмарки для оценки больших языковых моделей, не является панацеей. Сам факт автоматической генерации тестов не гарантирует их истинной репрезентативности или адекватного охвата всего спектра возможных сценариев. Более того, зависимость от генетических алгоритмов вводит элемент случайности, требующий тщательной верификации каждого сгенерированного набора тестов на предмет неожиданных артефактов или предвзятостей.
Будущие исследования должны быть сосредоточены на формализации критериев «новизны» и «разнообразия». Простое увеличение числа тестов не решает проблему; необходимо разработать метрики, позволяющие количественно оценить информативность каждого теста и избежать избыточности. Особый интерес представляет исследование возможностей интеграции формальных методов верификации кода непосредственно в процесс генерации бенчмарков, что позволит гарантировать их корректность не только на уровне тестовых случаев, но и на уровне спецификаций.
В конечном счете, задача оценки больших языковых моделей требует не просто создания большего количества тестов, а разработки более глубокого понимания того, что на самом деле означает «интеллект» в контексте программирования. Истина не в количестве пройденных тестов, а в математической чистоте и доказуемости алгоритмов, которые эти модели генерируют.
Оригинал статьи: https://arxiv.org/pdf/2601.00575.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Квантовые сети для моделирования молекул: новый подход
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Квантовые прорывы: Хорошее, плохое и смешное
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Квантовые вычисления: от шифрования армагеддона до диверсантов космических лучей — что дальше?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-05 13:22