Автор: Денис Аветисян
Новый подход Amber-Image позволяет создавать детализированные изображения из текста, значительно снижая вычислительные затраты и требования к ресурсам.
Исследование представляет семейство эффективных моделей генерации изображений на основе диффузионных трансформаторов, достигающих передовых результатов за счет сжатия и дистилляции знаний.
Архитектуры Diffusion Transformer (DiT) значительно продвинули область генерации изображений по текстовому описанию, однако их вычислительная сложность и требования к ресурсам препятствуют широкому внедрению. В данной работе, посвященной ‘Amber-Image: Efficient Compression of Large-Scale Diffusion Transformers’, предложен эффективный фреймворк для сжатия моделей, позволяющий получить облегченные варианты без переобучения с нуля. Разработанные модели Amber-Image, достигающие сопоставимого качества с более крупными аналогами, демонстрируют снижение количества параметров на 70% и требуют менее 2000 GPU-часов для сжатия и обучения. Возможно ли дальнейшее снижение вычислительных затрат без ущерба для качества генерируемых изображений и насколько эффективно предложенный подход масштабируется на другие архитектуры генеративных моделей?
Масштабирование генерации изображений: вызовы и ограничения
Несмотря на впечатляющий прогресс в области генерации изображений по текстовому описанию, современные модели зачастую требуют значительных вычислительных ресурсов, что существенно затрудняет их практическое применение. Создание детализированных и реалистичных изображений связано с огромным объемом вычислений, что делает развертывание этих моделей на стандартном оборудовании проблематичным. Высокая стоимость обучения и эксплуатации ограничивает доступность передовых технологий генерации изображений для широкого круга пользователей и разработчиков, подчеркивая необходимость в более эффективных и экономичных подходах к решению этой задачи. Помимо вычислительных затрат, сложность масштабирования также связана с потребностью в больших объемах данных для обучения и поддержания качества генерируемых изображений.
Существующие диффузионные модели, несмотря на впечатляющие результаты в генерации изображений по текстовому описанию, зачастую сталкиваются с трудностями в эффективном логическом анализе и понимании сложных композиционных задач. Огромное количество параметров, необходимое для достижения высокого качества генерации, приводит к значительным вычислительным затратам и затрудняет интерпретацию многокомпонентных запросов. Модели склонны к ошибкам при обработке описаний, требующих одновременного учета нескольких объектов и их взаимосвязей, что проявляется в искажении деталей или нарушении общей семантической согласованности сгенерированного изображения. Данная проблема ограничивает возможности применения таких моделей в задачах, требующих точного и детализированного представления визуальной информации по заданному тексту.
Современные системы генерации изображений по текстовому описанию, несмотря на впечатляющие результаты, часто сталкиваются с трудностями в интерпретации сложных запросов и создании семантически точных изображений. Для оценки этих возможностей были разработаны специализированные бенчмарки, такие как DPG-Bench и GenEval, выявляющие потребность в моделях, способных к более глубокому пониманию и точному выполнению инструкций. В этой связи, модель Amber-Image демонстрирует значительный прогресс, достигая передовых результатов на обоих бенчмарках и подтверждая свою способность генерировать изображения, точно соответствующие даже самым сложным текстовым описаниям. Это свидетельствует о важности развития моделей, способных к более эффективному анализу и интерпретации текстовой информации для создания визуально релевантных и семантически корректных изображений.

Amber-Image: семейство эффективных моделей
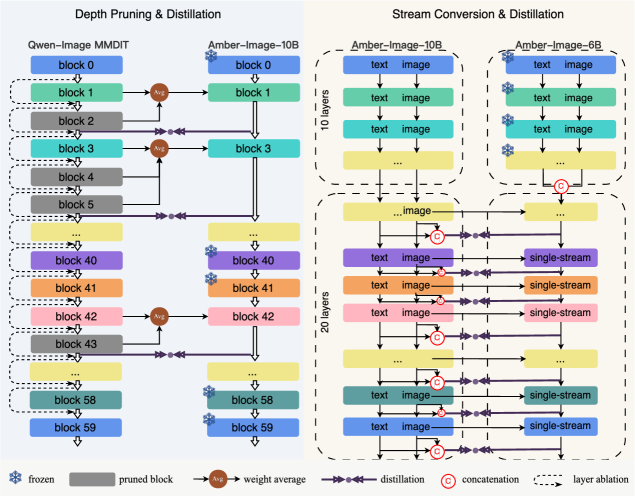
Семейство моделей Amber-Image разработано на базе Qwen-Image, используя её проверенную архитектуру и возможности. При этом, за счет оптимизации и применения методов дистилляции знаний, удалось значительно снизить вычислительные затраты. В частности, количество параметров в Amber-Image уменьшено на 70% по сравнению с оригинальной Qwen-Image, что позволяет добиться большей эффективности и снизить требования к аппаратным ресурсам без существенной потери в качестве генерируемых изображений.
В архитектуре Amber-Image используется метод дистилляции знаний для передачи навыков, полученных от более крупных моделей, к компактным и эффективным вариантам. Этот процесс включает в себя обучение меньшей модели (студента) имитировать выходные данные более крупной, предварительно обученной модели (учителя). В результате, Amber-Image сохраняет значительную часть производительности оригинальной Qwen-Image, но при существенно меньшем количестве параметров и, следовательно, сниженных вычислительных затратах. Дистилляция знаний позволяет уменьшить размер модели без значительной потери точности, что особенно важно для развертывания на ресурсоограниченных устройствах или в средах, требующих высокой скорости обработки.
Семейство моделей Amber-Image включает в себя две основные версии: Amber-Image-6B и Amber-Image-10B. Обе модели разработаны с целью достижения баланса между производительностью и потребностью в вычислительных ресурсах. Полный цикл обучения обеих версий был завершен менее чем за 2000 GPU-часов, используя кластер из 8 графических процессоров NVIDIA A100.
Архитектурные инновации: гибридные и дуальные потоки
Архитектура Amber-Image-6B сочетает в себе принципы однопотоковой и двухпотоковой обработки данных. Однопотоковый подход позволяет эффективно извлекать признаки из входных данных, в то время как двухпотоковая обработка способствует более глубокому анализу и интеграции признаков. Комбинирование этих подходов позволяет модели Amber-Image-6B достигать повышенной скорости обработки и точности распознавания по сравнению с моделями, использующими только один из этих подходов. Данная гибридная архитектура позволяет оптимизировать использование вычислительных ресурсов и повысить общую производительность системы.
Гибридная архитектура обработки данных, используемая в Amber-Image-6B, обеспечивает более эффективное извлечение и интеграцию признаков за счет комбинирования преимуществ однопотоковой и двухпотоковой обработки. Такой подход позволяет снизить вычислительную сложность и повысить скорость обработки изображений без потери точности. Более эффективное извлечение признаков означает, что модель может идентифицировать ключевые характеристики изображения с меньшими затратами ресурсов, а их интеграция позволяет более точно сопоставить эти признаки с соответствующими категориями, что в совокупности приводит к повышению как скорости, так и точности классификации изображений.
В Amber-Image-10B для уменьшения размера модели без потери производительности применяется оценка важности слоев и структурированная обрезка. Данный процесс включает в себя количественную оценку вклада каждого слоя в общую точность модели, после чего происходит удаление наименее значимых слоев. Структурированная обрезка предполагает удаление целых каналов или фильтров, что позволяет более эффективно использовать вычислительные ресурсы и упрощает последующую оптимизацию модели. Этот подход обеспечивает значительное уменьшение количества параметров модели и требований к памяти, сохраняя при этом высокую точность распознавания.
После применения структурированной обрезки для уменьшения размера модели Amber-Image-10B, инициализация оставшихся весов слоев осуществляется посредством арифметического усреднения. Данный метод предполагает вычисление среднего значения весов для каждого слоя и присвоение этого среднего значения всем оставшимся параметрам слоя. Это позволяет сохранить стабильность модели и предотвратить снижение производительности, которое могло бы возникнуть при случайной или нулевой инициализации весов после удаления части параметров. Арифметическое усреднение обеспечивает плавный переход от исходной модели к обрезанной, минимизируя нарушения в процессе обучения и обеспечивая более быструю конвергенцию.
Усиленное понимание текста и масштабируемость моделей
Внедрение Qwen2.5-VL-7B в качестве текстового энкодера значительно расширило возможности Amber-Image в понимании сложных и детализированных текстовых описаний. Данная модель, благодаря своей архитектуре, способна более точно интерпретировать нюансы языка, улавливая тонкости смысла и контекста, что ранее представляло сложность для подобных систем. Это позволило Amber-Image генерировать изображения, более точно соответствующие заданным текстовым запросам, даже если они содержат сложные метафоры, абстрактные понятия или требуют глубокого понимания культурных отсылок. Благодаря этому улучшению, система демонстрирует повышенную способность к созданию визуально богатых и семантически точных изображений, открывая новые горизонты для применения в различных областях, требующих точной визуализации сложных идей.
Для повышения эффективности передачи знаний в Amber-Image применялась локальная дистилляция знаний. Этот метод позволяет целенаправленно переносить информацию из более крупной, предварительно обученной модели в компактную, оптимизируя процесс обучения. Вместо передачи знаний из всех слоев, дистилляция фокусируется на наиболее критичных, определяющих качество генерации изображений. Такой подход не только ускоряет процесс обучения, но и значительно улучшает производительность модели, позволяя добиться высокого качества изображений даже при ограниченных вычислительных ресурсах. В результате, Amber-Image демонстрирует оптимальное соотношение между размером модели и качеством генерируемых изображений, превосходя аналогичные системы по эффективности и скорости работы.
Разработанные модели демонстрируют впечатляющий баланс между эффективностью использования параметров и качеством генерируемых изображений. Это достижение позволяет развертывать Amber-Image даже на устройствах с ограниченными вычислительными ресурсами, таких как мобильные телефоны или встроенные системы. Оптимизация архитектуры и методов обучения позволила добиться высокой производительности без увеличения размера модели, что критически важно для практического применения в широком спектре сценариев. Такой подход открывает возможности для создания доступных и эффективных систем генерации изображений, способных работать в условиях ограниченных ресурсов и обеспечивать высокое качество результатов.
Достигнутые улучшения в архитектуре Amber-Image позволили существенно сократить время генерации изображений и снизить вычислительные затраты, при этом сохранив высокое качество и соответствие сгенерированных изображений исходному текстовому описанию. В результате, модель демонстрирует передовые результаты на ключевых бенчмарках DPG-Bench и GenEval, превосходя по эффективности как закрытые коммерческие системы, так и более крупные модели с открытым исходным кодом. Этот прорыв открывает возможности для развертывания Amber-Image на устройствах с ограниченными ресурсами, не жертвуя при этом качеством и семантической точностью генерируемых изображений.
Перспективы развития: к более эффективной и разумной генерации
В будущем планируется углубленное изучение инновационных методов прореживания и дистилляции моделей, направленных на значительное уменьшение их размера без существенной потери производительности. Эти техники, включающие в себя удаление избыточных параметров и передачу знаний от больших, сложных моделей к более компактным, позволяют создавать эффективные генеративные системы, пригодные для развертывания на устройствах с ограниченными ресурсами. Исследователи стремятся к разработке алгоритмов, способных интеллектуально определять и удалять наименее важные элементы модели, сохраняя при этом её способность генерировать высококачественный контент. Оптимизация структуры модели и уменьшение вычислительной сложности являются ключевыми задачами, способствующими повышению скорости работы и снижению энергопотребления.
Исследования в области применения разработанных методов оптимизации — таких как прунинг и дистилляция — к другим типам данных, в частности к генерации видео, представляется весьма перспективным направлением. Успешное применение этих техник к видео позволит существенно снизить вычислительные затраты и объемы памяти, необходимые для создания реалистичных и детализированных видеороликов. Это открывает возможности для разработки более эффективных систем видеомоделирования, сжатия и обработки, а также для создания новых приложений в области виртуальной и дополненной реальности, где требуется генерация высококачественного видео в режиме реального времени. Подобные исследования могут значительно расширить сферу применения генеративных моделей и способствовать развитию новых мультимедийных технологий.
Дальнейшее развитие более эффективных и интеллектуальных текстовых кодировщиков представляется ключевым фактором для значительного улучшения качества генерации и семантического понимания. Исследования в этой области направлены на создание кодировщиков, способных не только точно интерпретировать смысл входного текста, но и выделять наиболее важные детали и нюансы, что позволяет генеративным моделям создавать более связные, релевантные и креативные тексты. Усовершенствованные кодировщики смогут улавливать сложные взаимосвязи между словами и фразами, а также учитывать контекст и намерения автора, что приведет к генерации текстов, максимально приближенных к человеческому стилю и качеству. Повышение эффективности этих кодировщиков также позволит снизить вычислительные затраты и ускорить процесс генерации, делая технологии более доступными и масштабируемыми.
В конечном счете, стремление к разработке генеративных моделей сконцентрировано на достижении баланса между мощностью и доступностью. Исследования направлены на создание систем, способных генерировать сложные и реалистичные данные, при этом оставаясь ресурсоэффективными и простыми в использовании. Это позволит значительно расширить спектр применений — от автоматического создания контента и персонализированного обучения до помощи в научных исследованиях и творческих проектах. Подобные модели не только упростят доступ к передовым технологиям искусственного интеллекта, но и откроют новые возможности для самовыражения и творчества, позволяя каждому человеку реализовать свой потенциал с помощью инструментов генеративного ИИ.
Исследование демонстрирует закономерную тенденцию: попытки оптимизировать сложные модели, такие как diffusion transformers, неизбежно приводят к компромиссам. Amber-Image, с её стратегической обрезкой слоёв и дистилляцией знаний, лишь подтверждает эту мысль. Как однажды заметил Ян Лекун: «Машинное обучение — это не магия, а инженерия.» И действительно, представленные методы — это не прорыв в архитектуре, а прагматичное решение задачи уменьшения вычислительных затрат. Попытки добиться state-of-the-art производительности с меньшим количеством параметров — это всего лишь очередная итерация вечной борьбы между теорией и практикой, где прод всегда найдёт способ упростить даже самую элегантную конструкцию.
Что дальше?
Работа, представленная в данной статье, демонстрирует, как умело «выжать» производительность из уже существующих моделей генерации изображений. Однако, иллюзия эффективности всегда хрупка. Каждый раз, когда речь заходит о «сжатии» и «оптимизации», следует помнить, что рано или поздно, система неизбежно споткнётся о новые данные, о которых её создатели даже не подозревали. Уменьшение количества параметров — это лишь отсрочка неизбежного технического долга.
Более того, термины вроде «cloud-native» и «parameter efficiency» звучат красиво, но по сути это просто перекладывание вычислительной нагрузки на кого-то другого, часто за большие деньги. Погоня за «state-of-the-art» напоминает бег по кругу: сегодня это «прорыв», а завтра — очередная отправная точка. В конечном итоге, мы не пишем код — мы просто оставляем комментарии будущим археологам, пытающимся понять, зачем мы всё это делали.
По-настоящему интересные вопросы остаются без ответа. Как обеспечить стабильность моделей при изменении входных данных? Как избежать «галлюцинаций» и непредсказуемого поведения? И главное — как сделать так, чтобы эти сложные системы не просто генерировали картинки, а действительно понимали, что они делают? Если система стабильно падает, значит, она хотя бы последовательна. А вот последовательность в хаосе генеративных моделей — это уже настоящая проблема.
Оригинал статьи: https://arxiv.org/pdf/2602.17047.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Предел возможностей: где большие языковые модели теряют разум?
- Улучшение точности квантовых сенсоров: новый подход к подавлению шумов
- Резонансы в тандеме: Управление светом в микрорезонаторах
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
- Моделирование спектроскопии электронного пучка: новый подход
- Квантовое программирование: Карта развивающегося мира
- За пределами стандартной точности: новая структура эффективной теории
- Сердце музыки: открытые модели для создания композиций
- Тандем топ-кварков и бозона Хиггса: новые горизонты точности
- Квантовый скачок: от лаборатории к рынку
2026-02-22 05:56