Автор: Денис Аветисян
Как анализ взаимодействий между большими языковыми моделями позволяет автоматически создавать синергетичные команды для совместной работы без предварительного знания их специализации.
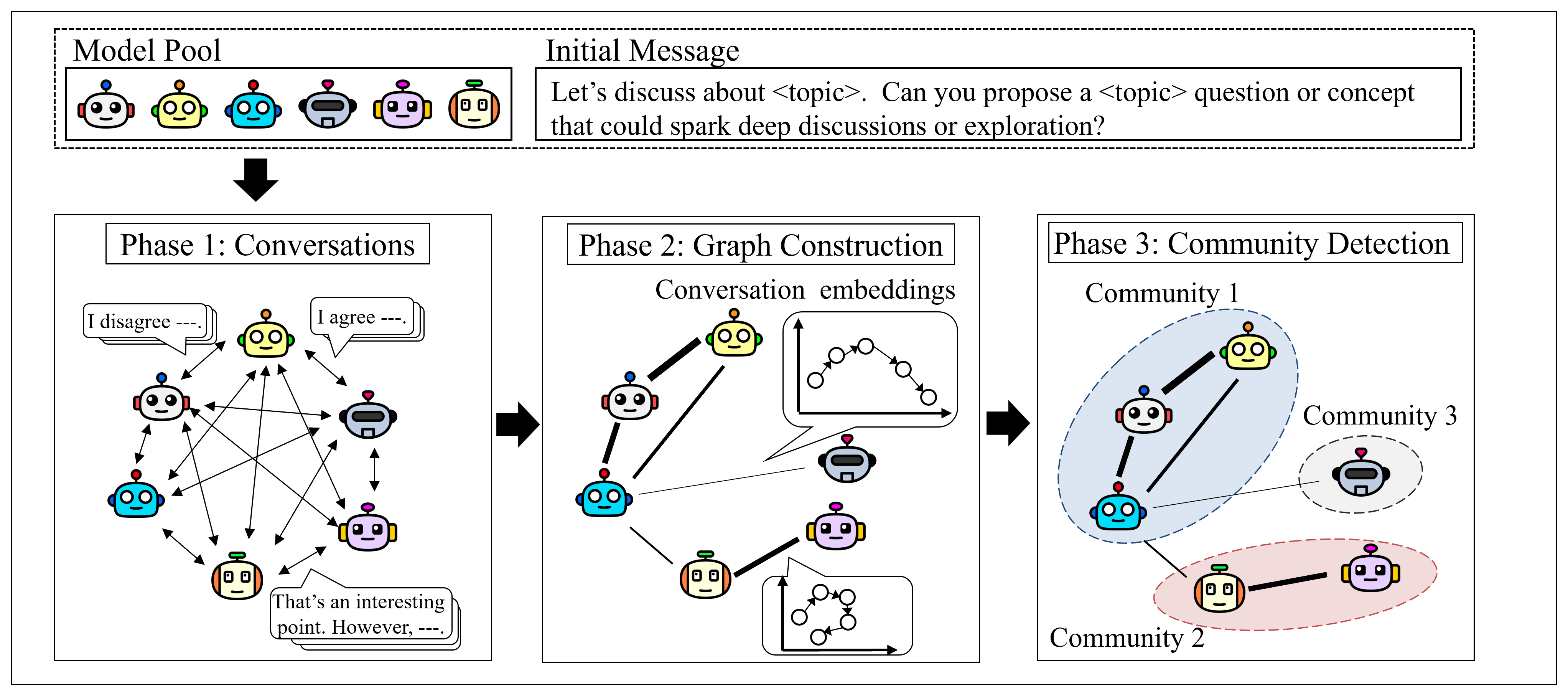
Метод визуализации и кластеризации взаимодействий языковых моделей для оптимизации многоагентного сотрудничества.
Несмотря на перспективность многоагентных систем, основанных на больших языковых моделях, формирование эффективных команд остается сложной задачей из-за непрозрачности внутренних характеристик моделей. В работе ‘The Geometry of Dialogue: Graphing Language Models to Reveal Synergistic Teams for Multi-Agent Collaboration’ предложен новый подход к автоматическому формированию команд, основанный на построении «графа языковых моделей» и выявлении синергетических кластеров посредством анализа семантической согласованности парных диалогов. Полученные результаты демонстрируют, что предложенный метод позволяет выявлять функционально согласованные группы моделей, отражающие их латентные специализации, и формировать команды, превосходящие случайные аналоги. Возможно ли создание полностью автоматизированных систем, способных динамически адаптировать состав многоагентных команд для решения широкого спектра задач?
Иллюзия Коллективного Разума
Несмотря на впечатляющие возможности больших языковых моделей (LLM), решение сложных задач часто требует совместного рассуждения, выходящего за рамки одной модели. Существующие подходы к формированию команд спонтанны или ориентированы на конкретные задачи, игнорируя нюансы взаимодействия. Это снижает эффективность коллективного интеллекта. Необходима парадигма ‘многоагентного сотрудничества’, в которой LLM динамически объединяются, а не действуют по предопределенным ролям. Такая система станет более гибкой и адаптивной. В конечном итоге, все эти «революционные» архитектуры лишь отсрочат неизбежное появление первого критического бага в продакшене.
Граф Языковых Моделей: Картография Знаний
Предлагается концепция ‘Графа языковых моделей’ для представления взаимосвязей между LLM. Узлы – отдельные модели, веса ребер – семантическая согласованность. Построение графа осуществляется посредством систематической ‘Генерации диалогов’, фиксирующей нюансы взаимодействия. Вычисление ‘Значения взаимосвязи’ основано на ‘Функции встраивания предложений’ и ‘Косинусном сходстве’. Полученная количественная оценка определяет веса ребер, отражая семантическую близость.
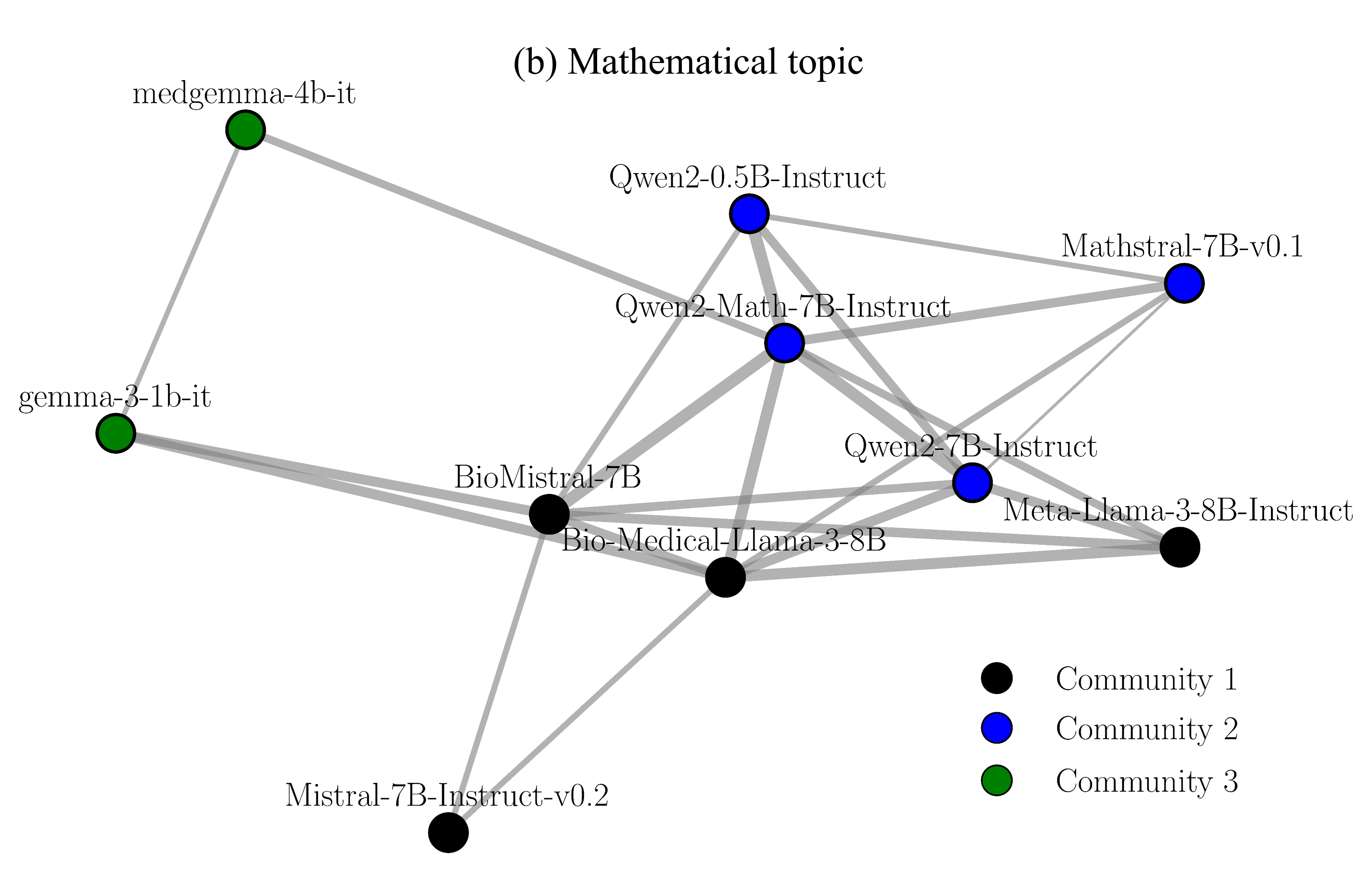
Автоматическое Формирование Команд: Обнаружение Сообществ
Для выявления групп когерентных моделей внутри графа языковых моделей применяются методы «обнаружения сообществ», в частности, алгоритм Лувена. Этот подход позволяет идентифицировать кластеры моделей, способных эффективно взаимодействовать, без предварительного знания об их структуре. Результаты показывают, что автоматически идентифицированные кластеры демонстрируют производительность, приближающуюся к командам, сформированным экспертами. Это контрастирует с традиционными подходами и указывает на возможность формирования эффективных рабочих групп на основе внутренней когерентности моделей.

Валидация Коллективного Рассуждения: Zero-Shot Inference
Исследование оценивало эффективность автоматически формируемых команд при решении задач ‘Zero-Shot Inference’ с использованием наборов данных MMLU, GSM8K, MATH-500, MedQA и MedMCQA. Изучалось влияние метода ‘Chain-of-Thought Prompting’ в сочетании с командной работой, особенно для наборов данных GSM8K и MATH-500. Полученные результаты демонстрируют, что предложенный подход достигает производительности, сопоставимой с командами, специализирующимися на математике и медицине, превосходя базовый уровень ‘Random@3models’. Это подтверждает потенциал автоматического формирования команд для раскрытия новых возможностей в области рассуждений. Каждая новая оптимизация – лишь временная отсрочка неизбежной энтропии.
Адаптивные Многоагентные Системы: К Общему Пониманию
Представленная работа закладывает основу для достижения «общего понимания» внутри команд, работающих с LLM, что способствует более эффективной коммуникации и сотрудничеству. Разработанный подход позволяет выявлять и формализовать неявные предположения и знания, которые часто становятся препятствием для совместной работы. Будущие исследования будут сосредоточены на разработке адаптивных стратегий формирования команд, способных реагировать на изменяющиеся требования задач. Особое внимание будет уделено алгоритмам динамической переконфигурации команды, учитывающим индивидуальные навыки участников и текущую стадию выполнения проекта. Данный подход обещает раскрыть весь потенциал многоагентного сотрудничества, приводя к созданию более интеллектуальных и универсальных систем искусственного интеллекта. Ожидается, что это позволит преодолеть ограничения существующих моделей и разработать решения, способные к более сложным и творческим задачам.
Исследование, представленное в статье, пытается найти закономерности в хаосе взаимодействия языковых моделей. По сути, это попытка обуздать непредсказуемость, выявить скрытые связи и собрать из отдельных «болтающих» сущностей что-то более осмысленное. Как точно заметил Алан Тьюринг: «Мы можем только надеяться, что машины не станут слишком умными, чтобы нас игнорировать». Эта фраза, на первый взгляд о потенциальной опасности искусственного интеллекта, здесь приобретает ироничный оттенок. Ведь сама идея построения эффективных команд из LLM предполагает, что даже самые сложные алгоритмы нуждаются в структуре и координации, чтобы избежать бессмысленного «разговора» и достичь синергии. Анализ графов взаимодействия моделей – это, по сути, попытка навести порядок в этом хаосе, выявить те самые «узкие места» и точки соприкосновения, которые позволяют превратить набор независимых агентов в слаженную команду.
Что дальше?
Представленный метод визуализации взаимодействия языковых моделей, безусловно, позволяет отложить в сторону наивную веру в универсальность. Однако, автоматическое формирование «синергетических кластеров» — это лишь новая форма оптимизации, а не решение фундаментальной проблемы. Задачей остаётся понимание того, что любая архитектура, даже сформированная алгоритмом, неизбежно станет узким местом. Продакшен всегда найдёт способ доказать, что «специализация» — это просто эвфемизм для «несовместимости».
Вместо бесконечной гонки за построением идеальных команд, возможно, стоит сосредоточиться на создании инструментов для диагностики и смягчения последствий неизбежных конфликтов. Анализ графа взаимодействий — это хороший старт, но необходимо учитывать, что любая модель, в конечном итоге, отражает предвзятости и ограничения данных, на которых она обучалась. Иначе, мы просто автоматизируем процесс воспроизведения ошибок.
Нам не нужно больше графиков — нам нужно меньше иллюзий. Следующим шагом, вероятно, станет разработка метрик, позволяющих оценивать не «синергию», а устойчивость системы к сбоям и непредсказуемым запросам. Иначе говоря, необходимо научиться предсказывать, где именно и когда элегантная теория рухнет под натиском реальности.
Оригинал статьи: https://arxiv.org/pdf/2510.26352.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые нейросети на службе нефтегазовых месторождений
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
2025-11-02 15:38