Автор: Денис Аветисян
Исследование представляет метрику Shesha, позволяющую оценить стабильность геометрической структуры представлений, и демонстрирует её превосходство в прогнозировании устойчивости моделей и выявлении изменений в процессе обучения.
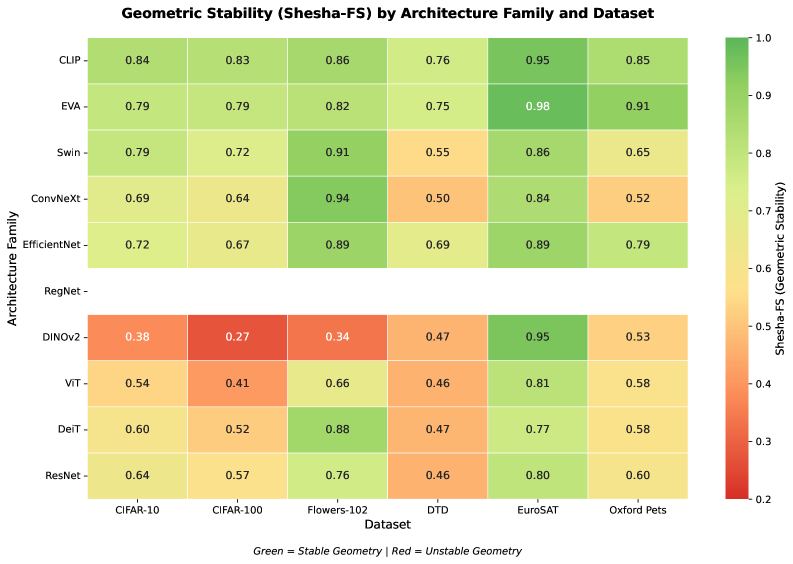
В статье представлена метрика Shesha для оценки геометрической стабильности представлений в нейронных сетях, превосходящая традиционные метрики сходства в задачах прогнозирования устойчивости и обнаружения дрейфа представлений.
Анализ представлений в современных моделях часто фокусируется на сходстве, упуская из виду вопрос о надежности этой структуры. В работе ‘Geometric Stability: The Missing Axis of Representations’ предложен новый подход, оценивающий геометрическую стабильность — способность представлений сохранять свою структуру при небольших изменениях. Разработанный фреймворк Shesha демонстрирует, что стабильность и сходство — это независимые характеристики, причем стабильность лучше предсказывает устойчивость модели, обнаруживает структурные сдвиги и отражает функциональную организацию. Не станет ли геометрическая стабильность ключевым показателем для оценки качества представлений не только в машинном обучении, но и в биологических системах?
Поиск Истинной Надежности: За пределами Переносимости Знаний
Современные методы оценки моделей машинного обучения зачастую сосредотачиваются на способности к переносу знаний — производительности на новых, ранее не встречавшихся задачах. Однако, такая оценка часто упускает из виду внутреннюю согласованность представлений, формируемых моделью. Акцент на переносе, хотя и важен, может привести к ситуации, когда модель демонстрирует кажущуюся компетентность, успешно выполняя новые задачи, но при этом не обладает устойчивым и логичным внутренним представлением данных. Это означает, что незначительные изменения во входных данных или параметрах модели могут привести к существенным изменениям в её внутренних представлениях, что ставит под сомнение её реальное «понимание» данных и способность к обобщению. Подобный подход к оценке может привести к переоценке возможностей модели и упущению важных аспектов её надёжности и устойчивости.
Особое внимание уделяется геометрической стабильности представлений, критически важному свойству, часто упускаемому из виду при оценке моделей. Данное свойство характеризует устойчивость внутренних представлений модели к незначительным изменениям входных данных или возмущениям. Модель, обладающая высокой геометрической стабильностью, демонстрирует согласованное восприятие и обработку информации, даже при наличии шума или вариаций. В противном случае, кажущаяся компетентность может быть обманчивой, поскольку незначительные изменения во входных данных способны привести к радикальным изменениям в формируемых представлениях. Таким образом, геометрическая стабильность является индикатором не просто способности модели к запоминанию, а свидетельством глубокого понимания и способности к обобщению, что позволяет ей надежно функционировать в реальных, непредсказуемых условиях.
Модель, демонстрирующая высокую производительность при решении различных задач, может оказаться поверхностной в понимании сути данных, если её внутренние представления нестабильны. Несмотря на способность успешно классифицировать или прогнозировать, такая модель может легко сбиться с пути при незначительных изменениях входных данных или при столкновении с новыми, но схожими ситуациями. Нестабильность представлений указывает на отсутствие глубокого понимания закономерностей, лежащих в основе данных, и свидетельствует о том, что модель, по сути, запоминает шаблоны, а не формирует осмысленные, устойчивые представления о мире. В результате, кажущаяся компетентность может оказаться иллюзией, а способность к обобщению и адаптации — ограниченной и хрупкой.
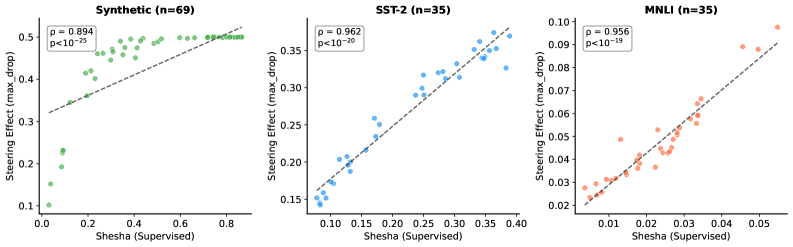
Предложен новый фреймворк, Shesha, предназначенный для прямой оценки устойчивости представлений в моделях машинного обучения. В ходе исследований было показано, что Shesha способен выявлять дрейф представлений — потерю стабильности при небольших изменениях входных данных — в 73% протестированных моделей. Это значительно превосходит результаты, полученные с использованием стандартных методов, таких как CKA (Centered Kernel Alignment), которые обнаруживают подобные отклонения лишь в незначительном количестве случаев. Таким образом, Shesha предоставляет более надежный инструмент для оценки истинного понимания модели, выходя за рамки простой оценки переносимости на новые задачи и позволяя выявлять внутреннюю непоследовательность, которая может оставаться незамеченной при использовании традиционных подходов.
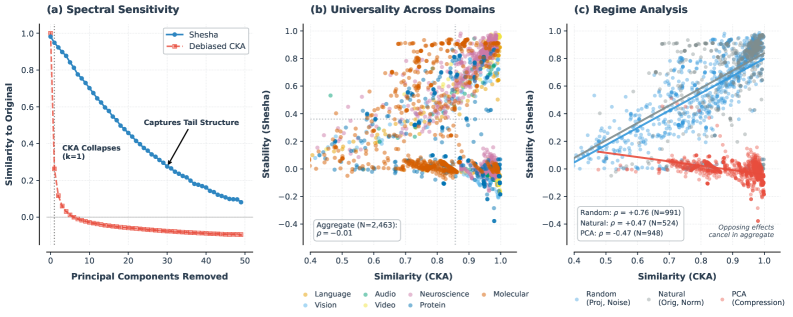
Количественная Оценка Внутренней Согласованности: Механизм Shesha
Shesha использует матрицы репрезентативного различия (RDMs) для количественной оценки взаимосвязей между различными стимулами или входными данными внутри модели. RDM строится путем вычисления расстояния (например, корреляции Пирсона или евклидова расстояния) между векторами признаков, представляющими каждый стимул. Получающаяся матрица показывает, насколько различны репрезентации разных стимулов в пространстве признаков модели. Чем больше сходство между репрезентациями двух стимулов, тем меньше значение в соответствующей ячейке RDM. Таким образом, RDM компактно кодирует информацию о структуре репрезентаций модели и позволяет количественно оценивать, как модель различает различные входные данные.
Shesha оценивает внутреннюю геометрическую согласованность представлений модели путем корреляции матриц репрезентативной диссимилярности (RDMs), полученных из различных подмножеств признаков или данных. RDMs кодируют отношения между стимулами, отражая, насколько различны представления модели для разных входных данных. Высокая корреляция между RDMs, построенными на разных подмножествах данных, указывает на стабильность и надежность внутренних представлений модели, что свидетельствует о согласованности обработки информации даже при частичном изменении входных данных или используемых признаков. Этот подход позволяет количественно оценить, насколько внутренние представления модели остаются согласованными и структурно схожими при различных условиях.
В отличие от традиционных методов, таких как Centered Kernel Alignment (CKA), Shesha фокусируется на оценке внутренней согласованности представлений внутри одной модели, а не на сравнении представлений между разными системами. CKA измеряет сходство между представлениями, генерируемыми двумя различными моделями или слоями, вычисляя корреляцию между их ядрами. Shesha же использует матрицы репрезентативного диссонанса (RDMs) для анализа отношений между различными стимулами внутри одной модели, позволяя оценить, насколько согласованно модель представляет информацию, независимо от других систем. Такой подход позволяет выявить внутренние противоречия в представлениях модели, которые могут быть не видны при межсистемном сравнении.
Для оценки присущих ограничений измерения внутренней согласованности моделей, в Shesha адаптирована методика оценки «потолка шума» (Noise Ceiling Estimation). Данный подход предполагает генерацию множества случайных RDMs (матриц диссимилярности представлений) на основе исходных данных, что позволяет оценить максимальную достижимую корреляцию, обусловленную только шумом. Полученное значение служит реалистичным порогом, определяющим предел стабильности измеряемых показателей согласованности и позволяющим отличить истинную согласованность от случайных флуктуаций. Эффективно, «потолок шума» определяет верхнюю границу для оценки надежности результатов измерения согласованности, основанных на корреляции RDMs.
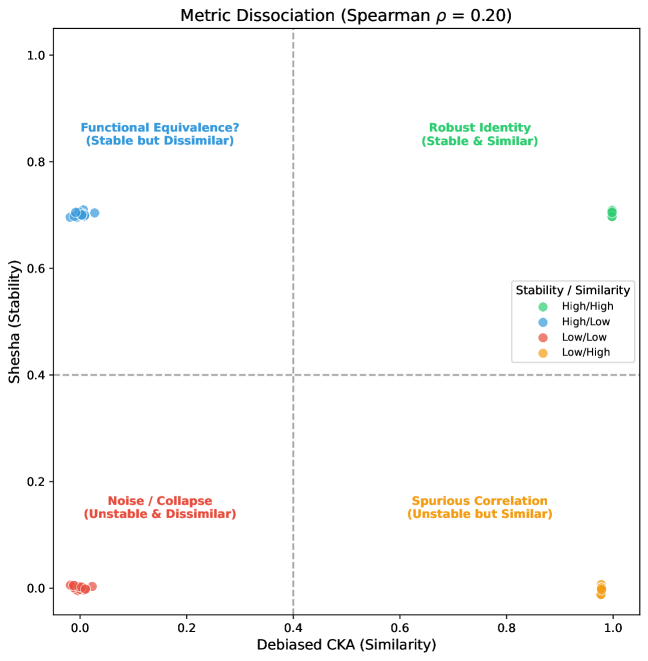
Углубленный Анализ: Расширения Shesha для Робастности и Взаимосвязи Признаков
Вариант Shesha, известный как Sample-Split Shesha, предназначен для оценки устойчивости модели к вариациям входных данных. Метод заключается в вычислении матриц репрезентативного расстояния (RDM) на основе непересекающихся подмножеств данных. Затем вычисляется корреляция между этими RDMs. Высокая корреляция указывает на то, что репрезентации модели остаются согласованными, несмотря на изменения во входных данных, что свидетельствует о большей робастности. Низкая корреляция может указывать на чувствительность модели к небольшим изменениям во входных данных или на нестабильность внутренних представлений.
Метод Feature-Split Shesha исследует внутреннюю согласованность модели путем корреляции репрезентационных матриц различий (RDM), полученных из непересекающихся подмножеств признаков. Этот подход позволяет оценить, насколько различные аспекты представления модели согласованы друг с другом. Разделение признаков на отдельные подмножества и последующее вычисление RDM для каждого из них позволяет выявить степень согласованности в обработке информации, представленной различными признаками. Высокая корреляция между RDM, полученными из разных подмножеств признаков, указывает на то, что модель обрабатывает эти аспекты информации согласованно, что свидетельствует о большей внутренней согласованности модели.
Супервизированный Shesha предоставляет оценку стабильности, ориентированную на конкретную задачу, реализуя подход Sample-Split Shesha с использованием информации о метках классов. В отличие от базового Shesha, который анализирует стабильность представлений без учета задачи, супервизированный вариант применяет процедуру разделения данных на непересекающиеся подмножества, но при этом учитывает соответствующие метки классов при вычислении корреляции между Random Directional Measures (RDMs). Это позволяет оценить, насколько стабильны представления модели при небольших изменениях входных данных, в контексте конкретной задачи классификации или регрессии. Высокая корреляция между RDMs, полученными из различных подмножеств данных с метками, указывает на устойчивость модели к вариациям во входных данных при решении поставленной задачи.
Предложенные расширения Shesha, такие как Sample-Split Shesha и Feature-Split Shesha, позволяют получить более детальное представление о структуре представления модели и её способности поддерживать согласованную обработку данных. Анализ корреляции между RDMs (Representational Disimilarity Matrices), полученными на основе различных подмножеств данных (Sample-Split) или признаков (Feature-Split), выявляет степень устойчивости модели к вариациям входных данных и внутреннюю согласованность её представления. Supervised Shesha, реализующий Sample-Split Shesha с учетом меток задачи, обеспечивает оценку стабильности модели в контексте конкретной задачи, что позволяет более точно оценить её надежность и обобщающую способность.
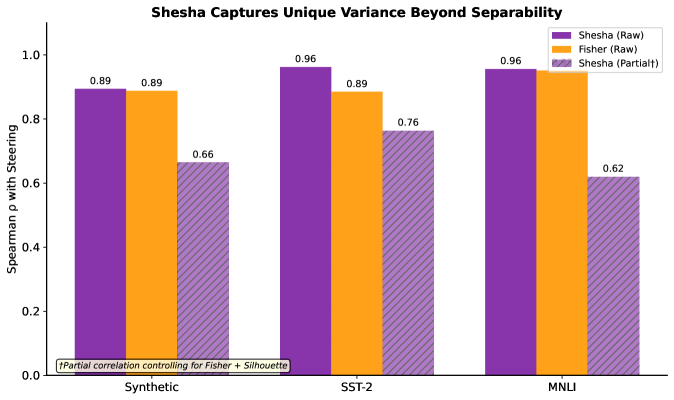
Влияние на Архитектуру Моделей и Методы Обучения: Путь к Надежному Искусственному Интеллекту
Исследования показали, что иерархические архитектуры, в отличие от более простых моделей, демонстрируют повышенную геометрическую стабильность. Этот феномен указывает на значимость многоуровневой обработки информации в искусственных нейронных сетях. В частности, слоистая структура позволяет модели более эффективно кодировать и сохранять информацию о геометрических преобразованиях входных данных, что, в свою очередь, способствует устойчивости к небольшим изменениям или шуму. Такой подход к построению архитектуры позволяет создавать более надежные и предсказуемые системы, способные к обобщению и адаптации в различных условиях, что особенно важно для задач, требующих высокой точности и устойчивости к помехам.
Исследование демонстрирует, что обучение с использованием метода контрастивного выравнивания (Contrastive Alignment) способствует повышению геометрической стабильности нейронных сетей. Этот подход, фокусирующийся на сближении представлений схожих объектов и удалении представлений различных объектов, не только улучшает способность модели обобщать знания, но и укрепляет связь между заданными целями обучения и согласованностью формируемых представлений. По сути, контрастивное выравнивание заставляет модель строить более надежные и устойчивые внутренние представления данных, что, в свою очередь, способствует более предсказуемому и стабильному поведению в различных условиях и задачах. Полученные данные указывают на то, что оптимизация не только точности, но и внутренней согласованности представлений является ключевым фактором для создания надежных систем искусственного интеллекта.
Исследования показали, что некоторые современные подходы к обучению, такие как самообучение и использование метрик отбеленной схожести, могут неожиданно приводить к снижению геометрической стабильности модели. Вместо ожидаемого повышения устойчивости, эти методы иногда приводят к фрагментации пространства представлений, делая модель более чувствительной к незначительным изменениям входных данных. Это подчеркивает важность тщательного анализа влияния различных стратегий обучения на внутреннюю согласованность и надежность искусственного интеллекта, а также указывает на необходимость разработки новых методов, которые бы гарантировали стабильность представления данных даже при использовании передовых техник обучения.
Разработанная система Shesha представляет собой мощный инструмент для оценки и повышения устойчивости систем искусственного интеллекта, открывая путь к созданию более надежных и интерпретируемых моделей. Исследования показали высокую корреляцию между показателями Shesha и эффективностью управления — коэффициент Rho находится в диапазоне от 0.67 до 0.76. Это свидетельствует о том, что Shesha способна не только выявлять потенциальные уязвимости в архитектуре моделей, но и служить метрикой для оптимизации их производительности, обеспечивая более предсказуемое и контролируемое поведение в различных условиях эксплуатации. Благодаря возможности количественной оценки стабильности представлений, Shesha позволяет исследователям и разработчикам целенаправленно улучшать проектирование и обучение ИИ-систем, повышая их общую надежность и предсказуемость.
К Биологически Вдохновленному Искусственному Интеллекту и За Его Пределами: Новые Горизонты Исследований
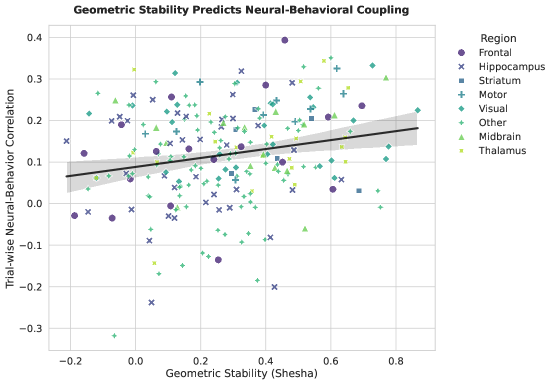
Концепция геометрической устойчивости находит глубокий отклик в нейробиологических исследованиях, поскольку именно устойчивые репрезентации информации являются ключевым фактором эффективной обработки данных в мозге. Нейронные сети, способные поддерживать стабильные внутренние представления, демонстрируют повышенную устойчивость к шуму и помехам, что критически важно для надежной работы когнитивных функций. Подобная устойчивость позволяет мозгу эффективно извлекать значимую информацию из сложных и неполных данных, а также быстро адаптироваться к изменяющимся условиям окружающей среды. Исследования показывают, что нарушение стабильности репрезентаций связано с когнитивными нарушениями, что подчеркивает важность изучения механизмов, обеспечивающих устойчивость в нервной системе, и разработки алгоритмов, имитирующих эти механизмы для создания более надежных и адаптивных систем искусственного интеллекта.
Предполагается, что разработанная система Shesha может быть применена для анализа данных о нейронной активности, получаемых с помощью передовых технологий, таких как Neuropixels. Этот подход позволит глубже понять структуру представления информации в мозге, выявляя устойчивые паттерны нейронных ответов на различные стимулы. Исследование данных, полученных с помощью Neuropixels, с использованием Shesha, потенциально способно раскрыть, как мозг кодирует и обрабатывает информацию, предоставляя ценные сведения о принципах работы нейронных сетей и лежащих в их основе вычислительных механизмах. Анализ устойчивости этих представлений может пролить свет на процессы обучения, памяти и когнитивных функций, открывая новые горизонты в нейронауке и искусственном интеллекте.
Система Shesha обладает потенциалом для оценки эффективности генетических интервенций, направленных на улучшение когнитивных функций, в частности, результатов, полученных с помощью CRISPR-скринингов. Анализируя изменения в стабильности представлений, вызванные конкретными генетическими модификациями, Shesha способна количественно оценить влияние этих изменений на устойчивость когнитивных процессов. Такой подход позволяет не только выявлять гены, играющие ключевую роль в когнитивных функциях, но и прогнозировать эффективность различных генетических стратегий, направленных на улучшение памяти, внимания или других когнитивных способностей. Использование Shesha в подобных исследованиях открывает новые возможности для разработки персонализированных подходов к улучшению когнитивных функций и лечению связанных с ними расстройств.
Стремление к объединению искусственного и биологического интеллекта открывает новые горизонты для создания действительно устойчивых и адаптивных систем искусственного интеллекта. Разработанный подход демонстрирует впечатляющую стабильность — показатель в 0.924 значительно превышает случайные значения, полученные в ходе перестановочных тестов. При этом, вероятность ложной тревоги составляет всего 7.3%, что существенно ниже — в шесть раз — по сравнению с традиционным методом Прокруста (44%) в стабильных ситуациях. Это указывает на повышенную надежность и точность предлагаемого метода, что делает его перспективным инструментом для построения интеллектуальных систем, способных эффективно функционировать в сложных и меняющихся условиях, а также для углубленного понимания механизмов работы мозга.
Исследование, представленное в данной работе, акцентирует внимание на геометрической стабильности нейронных представлений как ключевом факторе, определяющем надежность и устойчивость моделей. Введение метрики Shesha позволяет более точно оценивать, насколько хорошо модель сохраняет свою функциональность при изменениях входных данных или внутренних параметров. Это особенно важно в контексте переноса обучения и обеспечения детерминированного поведения системы. Как однажды заметил Винтон Серф: «Интернет — это всего лишь еще одна большая машина, и все машины иногда ломаются». Аналогично, нейронные сети, даже самые сложные, подвержены ошибкам, и понимание принципов геометрической стабильности необходимо для создания более надежных и предсказуемых систем, способных сохранять свою функциональность даже в условиях непредсказуемости.
Куда двигаться дальше?
Представленная работа, вводя метрику Shesha для оценки геометрической стабильности представлений, обнажает не только текущие недостатки в оценке робастности моделей, но и фундаментальную проблему: стремление к «рабочим» решениям часто затмевает необходимость доказательной непротиворечивости. Истинную элегантность кода нельзя измерить количеством успешно пройденных тестов; важна сама структура, ее устойчивость к возмущениям, ее внутренняя логика. Очевидно, что существующие методы оценки, основанные на простой схожести представлений, не способны адекватно отразить истинную устойчивость к дрейфу, особенно в контексте трансферного обучения и, что более важно, в биологических системах, таких как результаты CRISPR-скринингов.
Необходимо признать, что измерение геометрической стабильности — это лишь первый шаг. Следующим логичным шагом представляется разработка методов, позволяющих не просто оценивать стабильность, но и обеспечивать ее. То есть, создание алгоритмов обучения, которые изначально строят представления, устойчивые к возмущениям и дрейфу. В этой связи, особенно перспективным представляется изучение связи между геометрической стабильностью и принципами минимальной достаточности — стремлением к наиболее простой и эффективной структуре представления.
В конечном итоге, задача заключается не в создании все более сложных моделей, а в поиске тех принципов, которые позволяют строить простые, элегантные и, главное, доказуемо устойчивые представления. И это не просто техническая проблема, но и философский вызов — поиск истинной структуры в хаосе данных.
Оригинал статьи: https://arxiv.org/pdf/2601.09173.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые нейросети на службе нефтегазовых месторождений
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
2026-01-15 19:02