Автор: Денис Аветисян
Исследование представляет инновационный цифровой ускоритель Compute-in-Memory, оптимизирующий FP8 вычисления для достижения высокой производительности и снижения энергопотребления в задачах глубокого обучения.
Предложена динамическая схема предсказания разрядности FP8, позволяющая адаптировать точность вычислений в цифровых CIM-устройствах для повышения эффективности и минимизации потерь точности.
Несмотря на растущую популярность низкоточных форматов, таких как FP8, в задачах глубокого обучения, существующие цифровые архитектуры вычислений в памяти (DCIM) сталкиваются с трудностями при поддержке переменных разрядностей мантиссы. В данной работе, посвященной ‘Balancing FP8 Computation Accuracy and Efficiency on Digital CIM via Shift-Aware On-the-fly Aligned-Mantissa Bitwidth Prediction’, предложен гибкий FP8 DCIM-ускоритель, использующий динамическое предсказание разрядности с учетом сдвига для адаптивной настройки точности весов и входных данных. Разработанное решение позволяет достичь повышения энергоэффективности до 2.8 раз по сравнению с существующими аналогами при сохранении высокой точности. Какие дальнейшие оптимизации и архитектурные решения могут способствовать еще более эффективному использованию низкоточных вычислений в DCIM-системах?
Предел Эффективности: Вызовы Масштабирования Больших Языковых Моделей
Современные большие языковые модели, несмотря на впечатляющую производительность, сталкиваются с растущими вычислительными затратами по мере увеличения числа параметров. Эта тенденция создает значительные препятствия для их широкого внедрения и практического применения. С увеличением масштаба модели, требуются всё более мощные аппаратные ресурсы и энергозатраты, что ограничивает доступность и эффективность развертывания на различных платформах. В частности, обучение и инференс моделей с миллиардами параметров становятся непосильной задачей для многих организаций и исследователей, что замедляет прогресс в области искусственного интеллекта и обработки естественного языка. Таким образом, поиск решений для оптимизации и повышения эффективности этих моделей является критически важной задачей для дальнейшего развития и демократизации доступа к передовым технологиям.
Высокая вычислительная стоимость больших языковых моделей во многом обусловлена использованием традиционных форматов представления чисел с плавающей точкой, таких как FP16 и FP32. Эти форматы, обеспечивая высокую точность, требуют значительных ресурсов памяти и вычислительной мощности, что затрудняет развертывание моделей на широком спектре устройств и ограничивает скорость обработки данных. В связи с этим, активно исследуются альтернативные подходы, направленные на снижение разрядности представления чисел, например, INT8 или даже меньше. Такие методы позволяют существенно уменьшить объем памяти, необходимый для хранения модели, и ускорить вычисления, не оказывая при этом критического влияния на конечную точность результатов. Использование низкоточных форматов требует разработки специальных алгоритмов и техник, позволяющих компенсировать потерю точности и поддерживать работоспособность модели на приемлемом уровне.
Для сохранения высокой точности больших языковых моделей при одновременном снижении требований к памяти и вычислительным ресурсам, исследователи активно разрабатывают инновационные подходы. К ним относятся методы квантования, позволяющие представлять веса и активации модели с использованием меньшего числа битов, а также техники прунинга, направленные на удаление избыточных параметров без существенной потери производительности. Особое внимание уделяется алгоритмам дистилляции знаний, которые позволяют «перенести» знания из большой, сложной модели в более компактную, сохраняя при этом её способность к обобщению. Эти методы не только уменьшают размер модели, но и ускоряют процесс вычислений, делая её более доступной для развертывания на различных платформах, включая устройства с ограниченными ресурсами.
Для полной реализации потенциала больших языковых моделей критически важна оптимизация процессов обучения и применения. Растущие вычислительные затраты, связанные с увеличением числа параметров, создают серьезные препятствия для широкого внедрения этих технологий. Повышение эффективности обучения и инференса позволяет снизить требования к ресурсам, открывая возможности для использования моделей на более широком спектре устройств и в различных областях, от обработки естественного языка до научных исследований. Разработка новых алгоритмов и техник, направленных на снижение вычислительной сложности и потребления памяти, является ключевым направлением исследований, позволяющим сделать большие языковые модели доступными и полезными для большего числа пользователей и организаций.
FP8: Новый Эталон Точности для Инференса и Обучения
Формат FP8 обеспечивает существенное снижение требований к пропускной способности памяти и вычислительной сложности по сравнению с FP16 и FP32. Переход с 32-битной точности (FP32) на 8-битную (FP8) приводит к четырехкратному уменьшению объема памяти, необходимого для хранения весов и активаций модели. Это, в свою очередь, снижает требования к пропускной способности памяти на 4x. Сокращение битовой ширины также снижает сложность операций умножения и сложения, что приводит к снижению вычислительных затрат. В частности, операции с FP8 требуют в четыре раза меньше вычислительных ресурсов по сравнению с FP32 и в два раза меньше, чем FP16, что позволяет значительно ускорить вычисления и снизить энергопотребление.
Формат FP8 предлагает несколько вариантов представления чисел с плавающей точкой, включая E2M5, E3M4, E4M3 и E5M2. Каждый из этих форматов характеризуется различным распределением бит между экспонентой и мантиссой, что напрямую влияет на динамический диапазон и точность представления чисел. Например, формат E5M2 (5 бит для экспоненты и 2 бита для мантиссы) обеспечивает более широкий диапазон значений, но меньшую точность, в то время как формат E2M5 (2 бита для экспоненты и 5 бит для мантиссы) обеспечивает большую точность при более узком диапазоне. Выбор оптимального формата FP8 зависит от конкретных требований задачи и компромисса между необходимой точностью вычислений и доступным динамическим диапазоном, что требует тщательного анализа и тестирования в контексте конкретной модели и данных.
Эффективная реализация FP8 требует специализированной аппаратной поддержки, в частности, архитектур с вычислениями в памяти (Compute-in-Memory, CIM). Традиционные вычислительные архитектуры, предназначенные для работы с форматами FP16 и FP32, не оптимизированы для обработки данных FP8 и могут столкнуться с узкими местами, связанными с пропускной способностью памяти и вычислительной эффективностью. CIM-архитектуры позволяют выполнять вычисления непосредственно в памяти, минимизируя перемещение данных и значительно снижая энергопотребление и задержки. Это особенно важно для FP8, поскольку формат требует более высокой скорости обработки данных для реализации потенциальных преимуществ в производительности и эффективности. Без аппаратной поддержки, преимущества FP8 могут быть нивелированы накладными расходами, связанными с эмуляцией или программной реализацией формата.
Внедрение формата FP8 позволяет значительно ускорить инференс и снизить энергопотребление при развертывании больших языковых моделей. Достигнута пиковая энергоэффективность в 20.4 TFLOPS/W с использованием формата E5M7, что на 2.8 раза превышает показатели предыдущих работ. Данный прирост обусловлен уменьшением требований к пропускной способности памяти и вычислительной сложности, что критически важно для масштабирования и оптимизации производительности в задачах искусственного интеллекта.
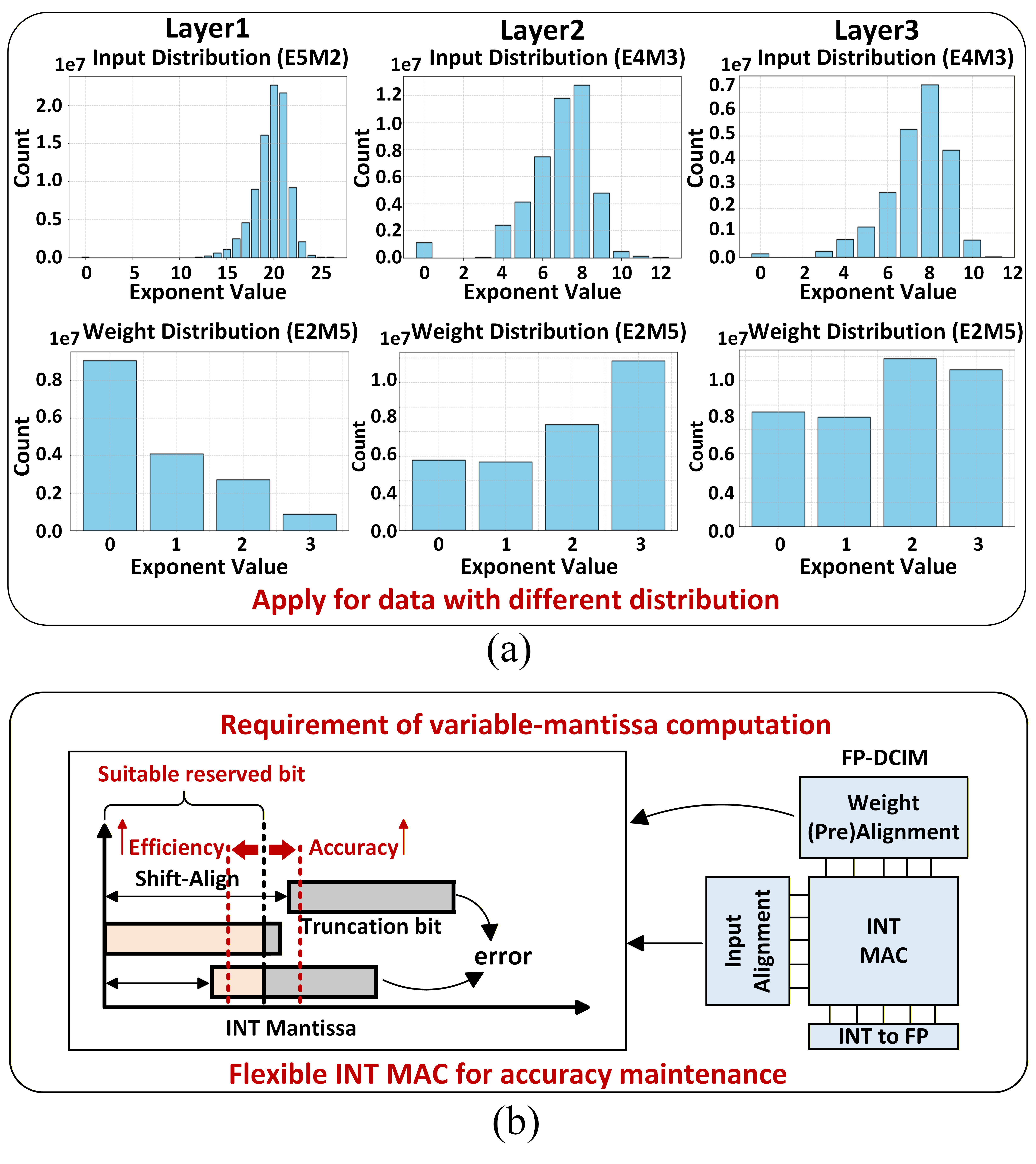
Аппаратное Ускорение и Выравнивание Мантиссы для FP8
Переменная длина мантиссы в формате FP8 представляет собой существенную аппаратную проблему, обусловленную сосуществованием различных FP8 форматов в вычислительной сети. Это требует динамической адаптации схемы выравнивания мантиссы для каждого входящего пакета данных, поскольку форматы могут отличаться количеством бит, выделенных на мантиссу. Отсутствие унифицированной длины мантиссы усложняет проектирование эффективных блоков выравнивания и приводит к увеличению сложности схемы управления, а также к потенциальному снижению пропускной способности и увеличению энергопотребления, если не реализовать специализированные решения для обработки данных с переменной длиной мантиссы.
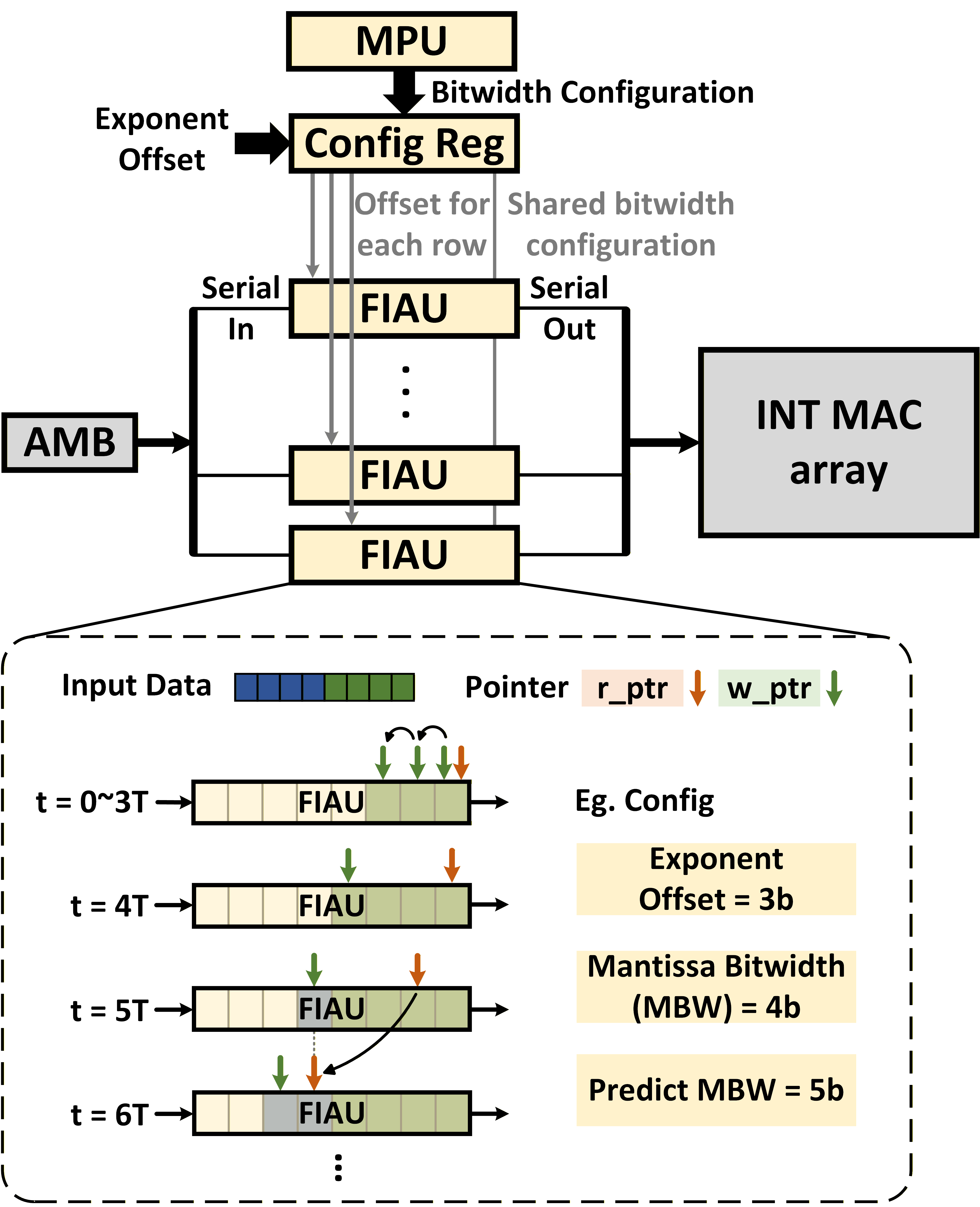
Для эффективной выравнивания мантиссы в формате FP8 критически важны модуль предсказания мантиссы (MPU) и FIFO-основанный модуль входного выравнивания (FIAU). MPU анализирует входящие данные для прогнозирования необходимой ширины мантиссы, а FIAU, используя принцип FIFO (First-In, First-Out), выполняет сдвиг и выравнивание мантисс на основе предсказаний MPU. Такая архитектура позволяет минимизировать задержки и оптимизировать пропускную способность данных, особенно в сценариях, где одновременно используются различные форматы FP8 с переменной шириной мантиссы.
Для оптимизации выравнивания мантиссы в FP8 используются методы динамического предсказания ширины битов с учетом сдвига (DSBP). DSBP анализирует групповое распределение данных для определения оптимальной ширины мантиссы и необходимого сдвига, что позволяет минимизировать вычислительные затраты на выравнивание. Данный подход позволяет предсказывать доминирующую ширину битов в каждой группе данных, что значительно упрощает аппаратную реализацию и снижает потребление энергии по сравнению с использованием фиксированных или универсальных схем выравнивания. Эффективность DSBP заключается в адаптации к изменяющимся характеристикам входных данных, обеспечивая оптимальную производительность при различных рабочих нагрузках.
Интеграция компонентов — Блока Предсказания Мантиссы (MPU) и FIFO-блока Выравнивания Входных Данных (FIAU) — с INT MAC-матрицей и SRAM обеспечивает повышение вычислительной пропускной способности и минимизацию задержек доступа к памяти. По сравнению с использованием сдвиговых регистров (barrel shifters) при той же конфигурации входных данных, данная архитектура демонстрирует снижение занимаемой площади на 21.7% и снижение энергопотребления на 34.1%. Это достигается за счет оптимизации обработки данных непосредственно в аппаратной части и сокращения необходимости в сложных операциях сдвига, что повышает эффективность и снижает затраты ресурсов.
Подтверждение Производительности с Llama-7b и За Его Пределами
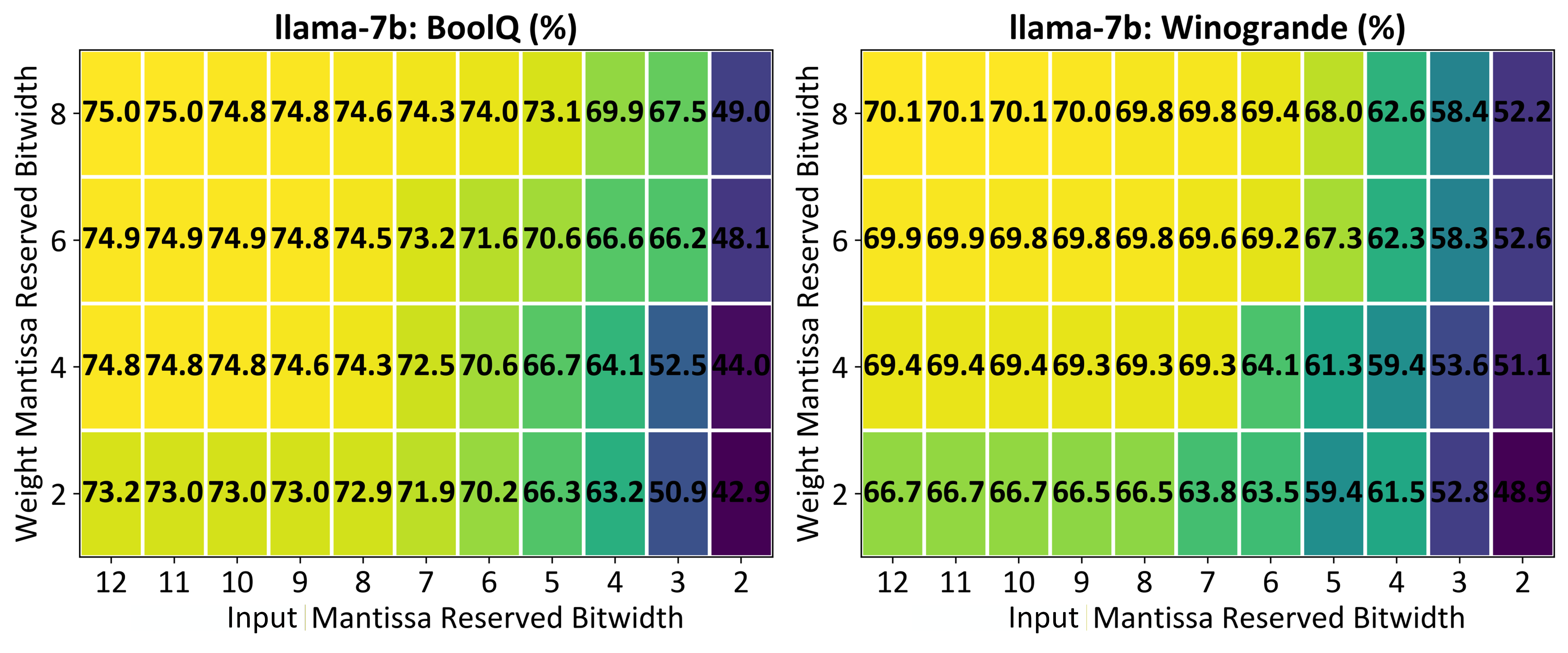
Предложенная реализация FP8, в сочетании с аппаратным ускорением, прошла валидацию на базе крупной языковой модели Llama-7b. Данный подход позволил подтвердить работоспособность и эффективность снижения точности вычислений без существенной потери качества. Использование FP8 продемонстрировало возможность значительного снижения требований к вычислительным ресурсам и энергопотреблению при работе с моделями искусственного интеллекта, открывая перспективы для более широкого и доступного применения передовых технологий в различных областях, включая обработку естественного языка и компьютерное зрение. Успешная валидация на Llama-7b является важным шагом на пути к созданию более эффективных и масштабируемых AI-систем.
Проведенные оценки на общепринятых эталонных наборах данных, таких как BoolQ и Winogrande, продемонстрировали незначительную потерю точности при использовании предложенного подхода. В частности, на BoolQ достигнут результат в 75.0%, а на Winogrande — 70.1%. Эти показатели свидетельствуют о том, что разработанная методика позволяет сохранять высокую производительность даже при снижении точности представления данных, что делает её перспективной для применения в ресурсоограниченных средах и для ускорения вычислений без существенного влияния на качество результатов.
В ходе тестирования предложенной реализации FP8 была проведена валидация на архитектуре ResNet18 с использованием датасета ImageNet. Полученные результаты демонстрируют, что точность классификации изображений при использовании FP8 составляет 69.6%. Это свидетельствует о сохранении высокого уровня производительности модели даже при снижении разрядности представления данных, что открывает возможности для оптимизации вычислительных ресурсов и повышения эффективности обработки изображений в задачах компьютерного зрения. Данный показатель подтверждает перспективность использования FP8 для широкого спектра моделей и приложений, требующих высокой точности и скорости обработки данных.
Предложенный подход, использующий формат FP8, продемонстрировал значительное повышение производительности и энергоэффективности. В ходе тестирования на наборе данных BoolQ удалось достичь увеличения пропускной способности в 1.5 раза, а при работе с ResNet18 на ImageNet — повышения энергоэффективности в 1.7 раза по сравнению с традиционными, более точными конфигурациями. Эти результаты подтверждают возможность эффективного развертывания больших языковых моделей на основе FP8 без существенной потери в точности, что открывает перспективы для создания более быстрых и экономичных решений в области искусственного интеллекта.
Предложенный подход демонстрирует значительный потенциал для широкого применения в различных моделях и задачах искусственного интеллекта. Исследования показывают, что оптимизация, основанная на формате FP8, не ограничивается конкретными архитектурами или типами данных, что открывает возможности для создания более эффективных и масштабируемых решений в области машинного обучения. В перспективе, это позволяет снизить вычислительные затраты и энергопотребление, делая передовые модели искусственного интеллекта доступнее для широкого круга пользователей и приложений, от обработки естественного языка до компьютерного зрения и анализа данных.
Представленное исследование демонстрирует стремление к математической чистоте в области низкоточных вычислений. Авторы предлагают гибкий подход к квантованию FP8, основанный на динамическом предсказании разрядности, что позволяет достичь оптимального баланса между точностью и энергоэффективностью цифровых CIM-ускорителей. Этот метод, направленный на повышение надежности вычислений, перекликается с убеждением Давида Гильберта: “Мы должны знать. Мы должны знать, что мы можем знать.” Подобно тому, как Гильберт стремился к формализации математических знаний, данная работа нацелена на строгое определение и контроль над процессами вычислений в системах искусственного интеллекта, гарантируя их корректность и предсказуемость.
Куда двигаться дальше?
Представленная работа, хотя и демонстрирует эффективность динамического предсказания разрядности в цифровых CIM-устройствах с FP8, лишь затрагивает краешек проблемы истинной вычислительной точности. Утверждать, что алгоритм «работает» на тестовых данных — наивно. Доказательство корректности, а не просто эмпирическая демонстрация, остается высшей целью. Очевидно, что дальнейшие исследования должны быть сосредоточены на формальной верификации предложенного подхода, а не на бесконечной гонке за улучшениями на конкретных датасетах.
Особенно актуальным представляется вопрос о масштабируемости. Предложенное решение может быть элегантным для небольших матричных операций, но его применимость к крупномасштабным моделям глубокого обучения требует серьезного анализа. В конечном итоге, практическая ценность алгоритма определяется его способностью решать реальные задачи, а не количеством сэкономленных ватт на синтетических примерах. Необходимо исследовать компромиссы между сложностью реализации, потреблением энергии и точностью вычислений в контексте реально развертываемых систем.
И, конечно, не стоит забывать о фундаментальных ограничениях аппаратного обеспечения. Невозможно обойти законы физики. Улучшение алгоритмов — это лишь часть решения. Разработка новых архитектур и материалов, способных обеспечить более высокую точность и энергоэффективность вычислений, остается открытой задачей, требующей нетривиальных решений. Попытки обойти эти ограничения посредством хитроумных программных трюков — это, в лучшем случае, временное решение.
Оригинал статьи: https://arxiv.org/pdf/2602.05743.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Самообучающиеся агенты: новый подход к автономным системам
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Наука определений: Автоматическое извлечение знаний из научных текстов
- В поисках оптимального дерева: новые горизонты GPU-вычислений
- Bibby AI: Новый помощник для исследователей в LaTeX
- Графы и действия: новый подход к планированию для роботов
- Многокритериальная оптимизация: взгляд на народные методы
- Квантовые амбиции: Иран вступает в гонку
- Квантовые маршруты и гравитационные сенсоры: немного иронии от физика
2026-02-09 00:02