Автор: Денис Аветисян
Новый подход позволяет значительно расширить возможности больших языковых моделей в решении сложных задач, не увеличивая при этом вычислительные затраты.
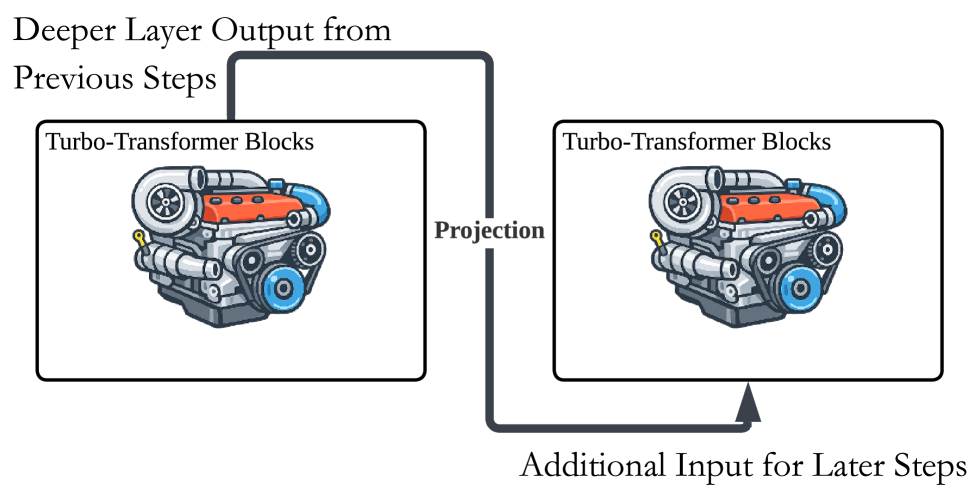
В статье представлена методика TurboConn, использующая остаточные связи для повышения эффективности рассуждений в глубоких нейронных сетях.
Несмотря на впечатляющие возможности современных больших языковых моделей, глубина их рассуждений часто оказывается ограничена фиксированным числом вычислительных шагов. В статье ‘Turbo Connection: Reasoning as Information Flow from Higher to Lower Layers’ предложен новый подход, TurboConn, который преодолевает это ограничение за счет маршрутизации остаточных связей от скрытых состояний верхних слоев к нижним слоям следующего токена. Этот метод позволяет значительно повысить точность моделей на задачах, требующих многошаговых рассуждений, таких как решение математических задач и арифметических примеров, без существенного увеличения вычислительных затрат. Может ли подобная архитектурная модификация стать ключом к созданию более эффективных и мощных языковых моделей, способных решать действительно сложные задачи?
Пределы Глубины: Рассуждения в Традиционных Трансформерах
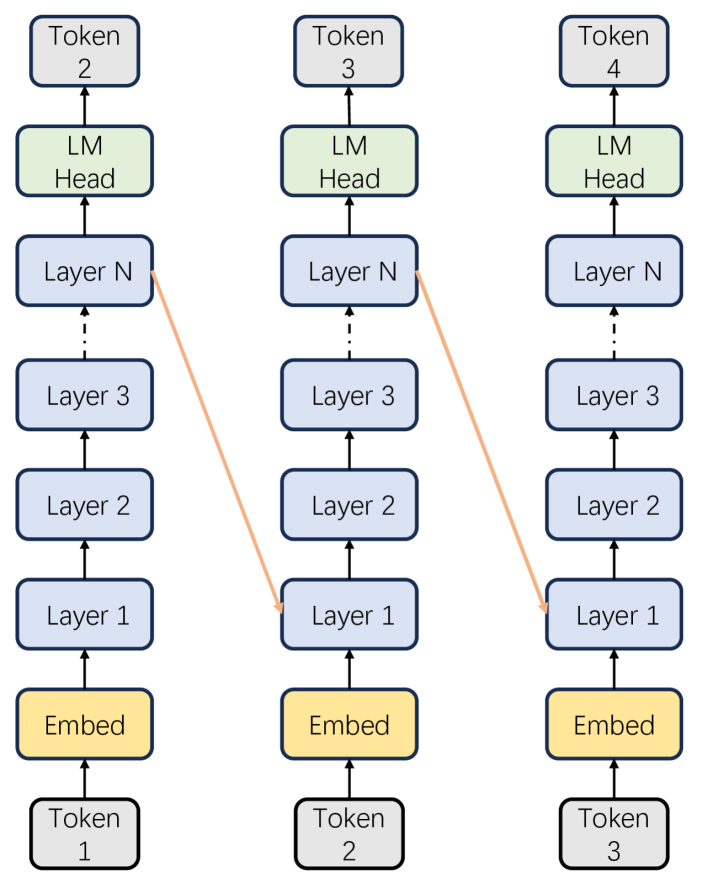
Несмотря на значительные успехи в различных областях обработки естественного языка, стандартные архитектуры Transformer демонстрируют ограниченные возможности при решении задач, требующих глубокого и многоступенчатого рассуждения. Суть проблемы заключается в том, что для сложных логических цепочек и вычислений, необходимых для таких задач, стандартные Transformer часто оказываются недостаточно «глубокими». В то время как параллельная обработка данных обеспечивает высокую эффективность в задачах, не требующих последовательного анализа, она создает препятствия для задач, где каждый шаг рассуждения зависит от предыдущего. Ограниченная глубина вычислений приводит к тому, что модель не способна эффективно обрабатывать длинные последовательности информации и выводить корректные результаты в задачах, требующих сложного логического вывода или решения математических задач.
Стандартная архитектура Transformer, несмотря на свою эффективность, сталкивается с трудностями при обработке последовательной информации, необходимой для сложных рассуждений. Её внутренняя параллельность, являющаяся преимуществом при решении многих задач, создает узкое место при анализе данных, требующих последовательного применения логических шагов. Вместо того, чтобы последовательно обрабатывать каждый этап рассуждений, Transformer стремится к одновременной обработке, что может приводить к потере информации о контексте и взаимосвязи между этапами. В результате, при решении задач, где важна глубина и последовательность рассуждений, например, при решении математических задач или логических головоломок, стандартные Transformer демонстрируют ограниченные возможности, требуя разработки альтернативных архитектур, способных эффективно увеличивать «эффективную глубину» обработки информации.
Исследования показывают, что стандартные архитектуры Transformer испытывают трудности при решении задач, требующих глубокого логического вывода, что особенно заметно на наборах данных, таких как GSM8K. Сравнение с альтернативными подходами, например, Turbo Connection, демонстрирует существенный прирост точности — от 0.9% до более чем 10% — указывая на необходимость в архитектурах, способных эффективно увеличивать “эффективную глубину” вычислений. Этот фактор критически важен для улучшения способности модели к последовательному рассуждению и решению сложных задач, требующих многошагового анализа информации.
Turbo Connection: Новая Архитектура для Улучшенных Рассуждений
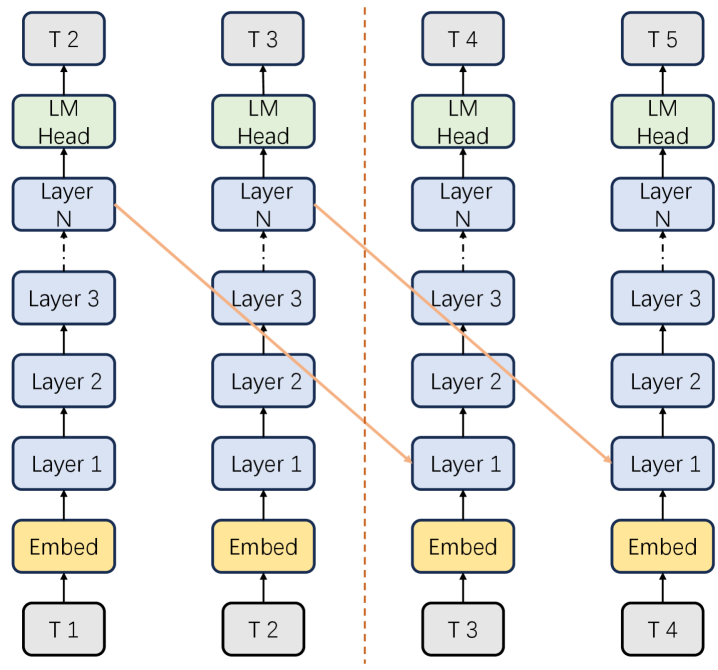
Архитектура Turbo Connection вводит нисходящие связи в структуру Transformer, позволяя информации передаваться непосредственно от более высоких слоев к более низким, минуя стандартную последовательную обработку. В традиционных Transformer-моделях информация проходит через слои последовательно, что ограничивает возможности параллельной обработки и усложняет передачу информации на большие расстояния. Нисходящие связи обеспечивают альтернативный путь передачи сигнала, позволяя сигналам, обработанным на верхних слоях, напрямую влиять на вычисления в нижних слоях. Это позволяет модели исследовать более длинные вычислительные пути и потенциально улучшить ее способность к рассуждениям, не увеличивая общее количество слоев.
Архитектура Turbo Connection увеличивает “эффективную глубину” сети за счет введения прямых связей между слоями, что позволяет исследовать более длинные вычислительные пути для рассуждений. В отличие от традиционных Transformer-моделей, где информация последовательно проходит через каждый слой, Turbo Connection обеспечивает возможность «перескока» через промежуточные слои. Это позволяет модели рассмотреть больше вариантов решения задачи, не увеличивая при этом общее количество слоев и, следовательно, не увеличивая вычислительную сложность пропорционально глубине сети. Такой подход позволяет более эффективно использовать существующие параметры модели для достижения улучшенных результатов в задачах, требующих сложных рассуждений.
Архитектура Turbo Connection направлена на смягчение ограничений, возникающих при параллельном обучении моделей-трансформеров, за счет организации прямого переноса информации между слоями. Традиционно, параллельное обучение требует последовательной обработки данных через каждый слой, что может ограничивать возможности модели по улавливанию сложных зависимостей. Прямой перенос информации позволяет модели исследовать более длинные вычислительные пути и эффективно использовать информацию, полученную на верхних слоях, для улучшения рассуждений на нижних слоях, не требуя при этом значительного увеличения количества слоев или вычислительных затрат. Это способствует повышению способности модели к более сложным формам логического вывода и решению задач, требующих глубокого понимания контекста.
В отличие от предыдущих подходов к модификации архитектуры Transformer, Turbo Connection разработана с учетом совместимости с существующими моделями. Это достигается за счет использования дополнительных нисходящих соединений, которые не требуют внесения изменений в существующие веса или структуры слоев. Внедрение Turbo Connection осуществляется путем добавления новых параметров, которые обучаются совместно с исходной моделью, что позволяет постепенно улучшать ее возможности без необходимости переобучения с нуля. Такой подход обеспечивает плавный путь к повышению производительности и позволяет интегрировать Turbo Connection в широкий спектр Transformer-based моделей, включая те, которые уже активно используются в различных приложениях.
Эмпирическая Проверка: Производительность в Сценариях Рассуждений
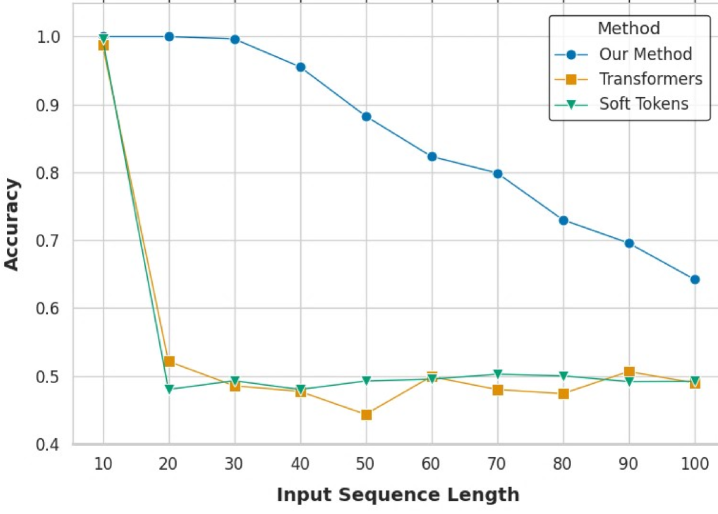
В ходе оценки Turbo Connection проводилось тестирование на различных задачах, требующих логического мышления. Это включало в себя многоступенчатые арифметические вычисления, задачу на определение четности (parity task), а также сложный набор задач GSM8K. Использование этих разнородных тестов позволило всесторонне оценить способность Turbo Connection к решению задач, требующих последовательного логического вывода и математических операций, охватывая как относительно простые, так и сложные сценарии.
Эксперименты с использованием моделей Llama 3 и Qwen 3 продемонстрировали существенное увеличение точности на различных задачах рассуждения. Зафиксированные улучшения в общей точности варьируются от 0.9% до более чем 10%. Эти результаты свидетельствуют о том, что применение Turbo Connection оказывает положительное влияние на способность моделей решать сложные задачи, требующие логического вывода и анализа данных, и позволяет добиться заметного прогресса в их производительности.
В ходе тестирования на задаче определения четности (parity task) с использованием модели Qwen-3-1.7B, применение Turbo Connection позволило достичь 100% точности. Это значительно превосходит результат, полученный при стандартной тонкой настройке (fine-tuning) той же модели, который составил 53.78%. Данный результат демонстрирует существенное улучшение способности модели к логическому выводу и решению задач, требующих точного определения четности числа.
В ходе экспериментов было установлено, что Turbo Connection значительно улучшает механизм «дискриминативной фильтрации», позволяя моделям более уверенно выявлять и отбрасывать неверные пути рассуждений. Для модели Qwen-3-1.7B среднее количество отброшенных вариантов составило 5.259, что превышает показатель базовой модели 8B (4.500). Данный результат демонстрирует, что Turbo Connection способствует более эффективному исключению неверных промежуточных выводов в процессе решения задач.
Последствия и Перспективы: К Более Надежному Искусственному Интеллекту
Успешная реализация Turbo Connection наглядно демонстрирует, что внесение изменений в архитектуру больших языковых моделей способно преодолеть существующие ограничения. Традиционные подходы часто сталкиваются с трудностями при обработке сложных запросов и поддержании последовательности рассуждений. Turbo Connection, за счет оптимизации потока информации и повышения эффективности использования параметров, позволяет значительно улучшить способность модели к решению задач, требующих глубокого анализа и логических выводов. Этот результат подчеркивает важность дальнейших исследований в области архитектурных инноваций, как ключевого направления для создания более надежных и интеллектуальных систем искусственного интеллекта, способных к более сложным формам рассуждений и адаптации к новым задачам.
Архитектура Turbo Connection способствует повышению надёжности и прозрачности процессов рассуждений в больших языковых моделях за счёт увеличения эффективной глубины сети и усиления дискриминативной фильтрации. Увеличение глубины позволяет модели анализировать информацию на более детальном уровне, выявляя тонкие взаимосвязи и зависимости. В свою очередь, усиленная дискриминативная фильтрация помогает отсеивать нерелевантную информацию и сосредотачиваться на ключевых факторах, что снижает вероятность ошибок и повышает точность выводов. Таким образом, Turbo Connection не только улучшает производительность модели, но и делает её рассуждения более понятными и обоснованными, что крайне важно для решения сложных задач и обеспечения доверия к результатам.
Внедрение группового размера в четыре в архитектуре Turbo Connection, несмотря на существенное повышение производительности, влечет за собой значительные вычислительные затраты. Исследования показали, что использование данной конфигурации приводит к 38.81 итерации рекурсии, что в 4.87 раза увеличивает время обучения модели по сравнению со стандартными настройками. Это означает, что для достижения оптимальных результатов с Grouped Turbo Connection требуется значительно больше вычислительных ресурсов и времени, что необходимо учитывать при масштабировании и развертывании системы. Оптимизация процесса обучения и поиск компромисса между скоростью и эффективностью представляются важными направлениями дальнейших исследований.
Предстоящие исследования направлены на синергетическое объединение архитектуры Turbo Connection с передовыми методами, в частности, с подходом «Chain-of-Thought» (Цепочка Мыслей). Данная интеграция предполагает усиление способности модели к последовательному, логическому рассуждению, что позволит ей не только генерировать ответы, но и демонстрировать ход своих мыслей. Ожидается, что сочетание архитектурных усовершенствований Turbo Connection с возможностями Chain-of-Thought значительно повысит надежность и интерпретируемость сложных рассуждений, открывая путь к созданию искусственного интеллекта, способного решать задачи, требующие глубокого анализа и планирования, и приближаясь к уровню когнитивных способностей человека.
Предложенный подход открывает новые перспективы в разработке искусственного интеллекта, способного решать всё более сложные задачи, требующие рассуждений. Исследования демонстрируют, что архитектурные модификации, такие как Turbo Connection, позволяют создавать системы, преодолевающие ограничения существующих больших языковых моделей и стремящиеся к уровню человеческого мышления. Потенциал данной технологии заключается не только в повышении точности и надёжности ответов, но и в создании более прозрачных и интерпретируемых процессов принятия решений, что критически важно для применения ИИ в ответственных областях, таких как медицина или финансы. Дальнейшие исследования, направленные на интеграцию с другими передовыми методами, такими как Chain-of-Thought, обещают ещё более значительный прогресс в достижении человекоподобного интеллекта у машин.
Исследование, представленное в данной работе, демонстрирует стремление к созданию систем, способных к более глубокому и эффективному рассуждению. Авторы предлагают метод TurboConn, направленный на увеличение «глубины рассуждений» больших языковых моделей без существенного увеличения вычислительных затрат. Этот подход перекликается с идеей о том, что истинная устойчивость достигается не за счёт мгновенных изменений, а за счёт постепенного, аккуратного развития. Как однажды заметила Ада Лавлейс: «То, что может быть выражено в форме алгоритма, подлежит воплощению в машине». Данная работа — попытка воплотить алгоритм более глубокого рассуждения в архитектуре языковой модели, стремясь к созданию системы, которая не просто обрабатывает информацию, но и осмысливает её, сохраняя при этом свою эффективность и устойчивость во времени.
Что дальше?
Представленная работа, стремясь к увеличению «глубины рассуждений» больших языковых моделей, неизбежно сталкивается с фундаментальным вопросом: является ли эта глубина свойством самой системы или лишь иллюзией, порожденной архитектурными ухищрениями? Каждый сбой в логике, каждая неточность — это сигнал времени, напоминание о конечности вычислительных ресурсов и несовершенстве алгоритмов. Метод TurboConn, безусловно, представляет собой шаг вперед, но он лишь откладывает неизбежное столкновение с энтропией.
Будущие исследования, вероятно, сосредоточатся не столько на увеличении глубины, сколько на повышении устойчивости системы к накоплению ошибок. Рефакторинг — это диалог с прошлым, попытка извлечь уроки из собственных неудач. Вместо того чтобы строить все более сложные «башни» рассуждений, возможно, стоит обратить внимание на принципы самовосстановления и адаптации, присущие более устойчивым системам.
Очевидно, что поиск оптимального баланса между вычислительной эффективностью и способностью к сложному мышлению — это вечная проблема. И в этом поиске важно помнить, что время — не метрика, а среда, в которой существуют системы. И каждая система стареет — вопрос лишь в том, делает ли она это достойно.
Оригинал статьи: https://arxiv.org/pdf/2602.17993.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Виртуальная примерка без границ: EVTAR учится у образов
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
- Квантовый скачок: от лаборатории к рынку
2026-02-23 17:49