Автор: Денис Аветисян
В статье представлена новая иерархическая платформа для организации и проведения глубоких исследований, способная эффективно решать долгосрочные и многогранные задачи.
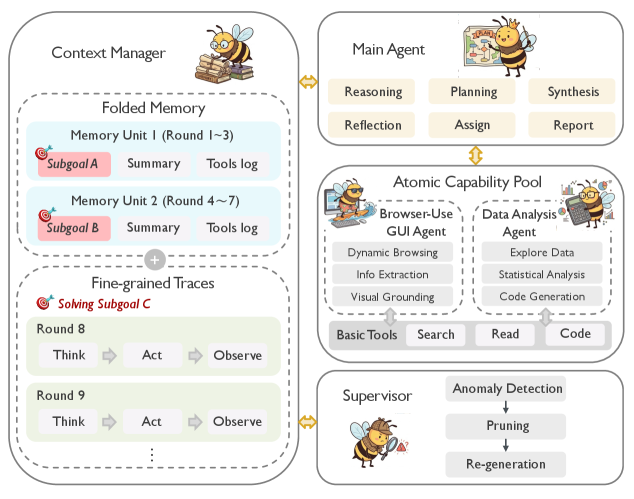
Представлен модульный агентский фреймворк Yunque DeepResearch, разработанный для повышения надежности и масштабируемости систем глубокого анализа данных и принятия решений.
Несмотря на значительный прогресс в области автономных агентов, долгосрочное выполнение сложных задач остается затруднено из-за накопления когнитивной нагрузки и хрупкости системы. В данной работе, представленной в ‘Yunque DeepResearch Technical Report’, предлагается иерархический и модульный фреймворк, способный эффективно решать эти проблемы. Ключевой особенностью Yunque DeepResearch является организация процесса исследования на основе централизованной системы оркестровки, динамического управления контекстом и проактивного модуля контроля ошибок. Сможет ли предложенный подход значительно расширить возможности агентов в решении задач глубокого исследования и открыть новые горизонты в области искусственного интеллекта?
Пределы Традиционных Агентов
Современные агенты, зачастую основанные на больших языковых моделях (БЯМ), демонстрируют впечатляющие способности в извлечении и генерации информации, однако их возможности в области устойчивого и сложного рассуждения остаются ограниченными. Несмотря на способность БЯМ к генерации связных текстов и имитации человеческой речи, они часто испытывают трудности при решении задач, требующих последовательного применения логических операций, глубокого анализа взаимосвязей и удержания информации на протяжении длительных цепочек рассуждений. Это проявляется в склонности к ошибкам при решении математических задач, построении сложных аргументов или планировании действий в динамически меняющейся среде. Таким образом, хотя БЯМ превосходно справляются с задачами, требующими быстрого доступа к знаниям, их эффективность заметно снижается при необходимости проведения глубокого и последовательного анализа.
Методики, подобные ReAct, значительно расширили возможности агентов, позволив им взаимодействовать с инструментами и окружающей средой. Однако, в ходе выполнения задач, требующих длительной последовательности действий, возникает проблема размывания контекста. С каждым новым шагом, полезная информация, необходимая для принятия обоснованных решений, постепенно теряется в потоке данных. Это особенно критично в сценариях глубоких исследований, где для успешного завершения требуется сохранение и анализ большого объема информации на протяжении всей задачи. В результате, агенты, использующие ReAct в долгосрочных задачах, часто демонстрируют снижение эффективности и точности, поскольку им становится сложно поддерживать когерентность и фокусировку на первоначальной цели исследования.
Современные подходы к оркестровке инструментов, такие как реализуемые в рамках Single-Agent Deep Research, демонстрируют ограниченную приспособляемость к меняющимся требованиям исследовательского процесса. Эти системы, как правило, основаны на предопределённых последовательностях действий и инструментов, что затрудняет их перестройку в ответ на неожиданные результаты или новые направления поиска. Отсутствие динамической адаптации приводит к неэффективному использованию ресурсов и снижает способность агента к глубокому и всестороннему изучению темы. В результате, несмотря на кажущуюся простоту реализации, подобные монолитные архитектуры оказываются недостаточно гибкими для решения сложных исследовательских задач, требующих постоянной переоценки стратегии и оперативной смены инструментов.

Yunque DeepResearch: Иерархический Подход к Глубоким Исследованиям
Иерархическая агентная структура, реализованная в Yunque DeepResearch, предназначена для решения сложных задач глубокого исследования, расширяя функциональные возможности Deep Research. Данный подход предполагает декомпозицию сложной исследовательской задачи на ряд подзадач, каждая из которых решается специализированным агентом, координируемым центральным управляющим агентом. Такая иерархия позволяет эффективно распределять ресурсы, снижать когнитивную нагрузку и повышать точность и скорость получения результатов, что особенно важно при работе с большими объемами информации и многоэтапными исследованиями. Структура обеспечивает гибкость и масштабируемость, позволяя адаптироваться к различным типам исследовательских задач и требованиям.
В основе архитектуры Yunque DeepResearch лежит Главный Агент, отвечающий за стратегическое планирование и оркестровку исследовательского процесса. Он использует Динамическое Управление Контекстом для достижения баланса между точностью и эффективностью выполнения задач. Это достигается за счет адаптивной настройки глубины и широты контекста, необходимого для каждого этапа исследования, что позволяет избежать избыточной обработки информации и сосредоточиться на релевантных данных. Главный Агент динамически корректирует контекст на основе текущих результатов и целей, оптимизируя процесс исследования и минимизируя временные затраты.
В рамках архитектуры Yunque DeepResearch используется Менеджер Контекста, который применяет Структурированную Память для организации информации, основанной на подцелях исследования. Этот подход предполагает разделение данных на логические блоки, соответствующие конкретным задачам, что позволяет избежать избыточности и упрощает поиск релевантной информации. Структурированная Память обеспечивает систематизацию данных по мере их поступления, что существенно повышает скорость извлечения и улучшает качество результатов, поскольку система фокусируется на информации, непосредственно связанной с текущей подзадачей.
Модульная Специализация и Надежное Исполнение
В основе Yunque DeepResearch лежит принцип использования “Атомарного Пула Возможностей”, представляющего собой набор специализированных субагентов. Каждый субагент, такой как агент для работы с графическим интерфейсом браузера (Browser-Use GUI Agent) или агент анализа данных (Data Analysis Agent), предназначен для эффективного выполнения конкретных, чётко определенных действий. Такая модульная архитектура позволяет оптимизировать процесс исследования за счет делегирования задач наиболее подходящим компонентам и повышения общей производительности системы, избегая необходимости в универсальных, но менее эффективных решениях.
Модуль супервизора в Yunque DeepResearch непрерывно отслеживает процесс выполнения задач, выявляя аномалии в поведении агентов и отклонения от заданных параметров. Обнаруженные аномалии инициируют механизмы самокоррекции, включающие повторные попытки выполнения, перераспределение задач между агентами или активацию резервных стратегий. Эта система мониторинга и самокоррекции обеспечивает стабильность и надежность работы системы, предотвращая каскадные сбои и поддерживая целостность результатов исследований даже при возникновении нештатных ситуаций.
Модульная архитектура Yunque DeepResearch позволяет реализовать многоагентные исследования, разделяя сложные задачи на более мелкие, которые могут быть обработаны специализированными агентами. Такой подход к декомпозиции задач обеспечивает параллельное выполнение и совместное решение проблем, что превосходит возможности монолитных систем, где одна большая программа обрабатывает всю задачу последовательно. В отличие от монолитных решений, где изменения в одной части системы могут потребовать переработки всей программы, модульная конструкция позволяет независимо обновлять и улучшать отдельные агенты, повышая общую гибкость и масштабируемость системы.
Оценка Эффективности и Перспективы Развития
Исследования показали, что Yunque DeepResearch демонстрирует стабильную и надежную работу при оценке на различных бенчмарках, включая GAIA, BrowseComp и Humanity’s Last Exam. Эти тесты, охватывающие широкий спектр задач — от анализа информации и навигации в интернете до решения сложных исследовательских вопросов, — позволили оценить способность системы к адаптации и эффективной обработке разнообразных типов данных. Полученные результаты подтверждают универсальность предложенного подхода и его потенциал для применения в различных областях, требующих глубокого понимания и анализа информации. Особенно важно, что система успешно справляется с задачами, требующими не только доступа к информации, но и критического мышления и синтеза знаний.
Оценка производительности системы Yunque DeepResearch на авторитетных бенчмарках, таких как GAIA, BrowseComp и Humanity’s Last Exam, демонстрирует ее широкие возможности и надежность. Достигнутый показатель Pass@1 составляет 78.6% на GAIA, 62.5% на BrowseComp и 51.7% на Humanity’s Last Exam. Эти результаты подтверждают способность системы успешно решать разнообразные исследовательские задачи, требующие глубокого анализа информации, логического мышления и способности к адаптации к различным типам данных и форматам вопросов. Высокая результативность на столь различных платформах подчеркивает универсальность и потенциал Yunque DeepResearch в качестве мощного инструмента для проведения научных исследований.
Результаты сравнительного анализа показывают, что разработанная платформа Yunque DeepResearch демонстрирует значительное превосходство над передовыми моделями. В частности, на бенчмарке BrowseComp достигнут прирост производительности в 10.0% по сравнению с Gemini 3 Pro, а на GAIA — 4.8%. Особенно заметно улучшение в задачах, связанных с обработкой китайского языка, где на BrowseComp-ZH платформа опережает DeepSeek-V3.2 на 10.1%. Эти результаты подтверждают эффективность предложенного подхода и указывают на потенциал Yunque DeepResearch для решения широкого спектра исследовательских задач, требующих высокой точности и способности к адаптации к различным языковым контекстам.
Дальнейшие исследования сосредоточены на усовершенствовании управления рабочей памятью в рамках системы Yunque DeepResearch. Ключевой задачей является расширение возможностей хранения и обработки информации, необходимой для решения сложных исследовательских задач. Разработчики стремятся к масштабированию фреймворка, чтобы он мог эффективно справляться с неоднозначными и многогранными вопросами, требующими глубокого анализа и синтеза данных. Особое внимание уделяется оптимизации алгоритмов, позволяющих системе удерживать в памяти релевантную информацию на протяжении длительных периодов времени и использовать ее для построения логических цепочек и выработки обоснованных выводов. Успешное решение этих задач позволит значительно повысить эффективность системы в решении широкого спектра научных проблем и открыть новые горизонты в области автоматизированных исследований.
Исследование, представленное в данной работе, демонстрирует стремление к созданию систем, способных к глубокому и долгосрочному анализу информации. Подход, основанный на модульности и иерархической структуре, позволяет преодолеть ограничения существующих систем, страдающих от когнитивной перегрузки и хрупкости. Как однажды заметила Ада Лавлейс: «Мой анализ машинного языка привёл меня к убеждению, что машинное поведение может быть запрограммировано для выполнения любой операции». Эта мысль находит отражение в архитектуре Yunque DeepResearch, где каждый модуль представляет собой специализированный инструмент, способный к выполнению конкретной задачи, а их взаимодействие обеспечивает целостность и эффективность всей системы. Особенно важным является акцент на управлении контекстом и коррекции ошибок, что позволяет агентам действовать более надежно и адаптироваться к изменяющимся условиям.
Что дальше?
Представленная работа, стремясь к созданию более надежной и расширяемой системы для глубоких исследований, неизбежно обнажает границы применимости существующих подходов. Система, как и любой сложный механизм, ломается по стыкам ответственности — там, где модули взаимодействуют, там и возникает наибольшая неопределенность. Недостаточно просто добавить еще один уровень абстракции; необходимо тщательно продумать интерфейсы и протоколы взаимодействия, чтобы избежать накопления скрытых ошибок.
Особое внимание следует уделить проблеме контекстуального управления. Информация, как известно, имеет свойство обесцениваться, а система, не способная к адаптации к изменяющейся среде, обречена на устаревание. Следующий этап развития должен быть направлен на создание самообучающихся механизмов, способных динамически переоценивать релевантность данных и адаптировать стратегии исследования. Простота и ясность архитектуры — залог долговечности, но и гибкость, и способность к эволюции — не менее важны.
В конечном итоге, успех подобных систем будет определяться не столько сложностью алгоритмов, сколько способностью предвидеть слабые места и строить устойчивые к ошибкам структуры. Разработка инструментов для формальной верификации и тестирования, а также создание метрик для оценки надежности и расширяемости, — это задачи, которые требуют первоочередного внимания. Иначе, останется лишь иллюзия контроля над сложной реальностью.
Оригинал статьи: https://arxiv.org/pdf/2601.19578.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Ранжирование с умом: новый подход к предсказанию кликов
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Квантовые сети для моделирования молекул: новый подход
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
2026-01-28 23:42