Автор: Денис Аветисян
Исследователи предлагают инновационный подход к моделированию определений, позволяющий создавать более точные и универсальные описания в различных областях знаний.
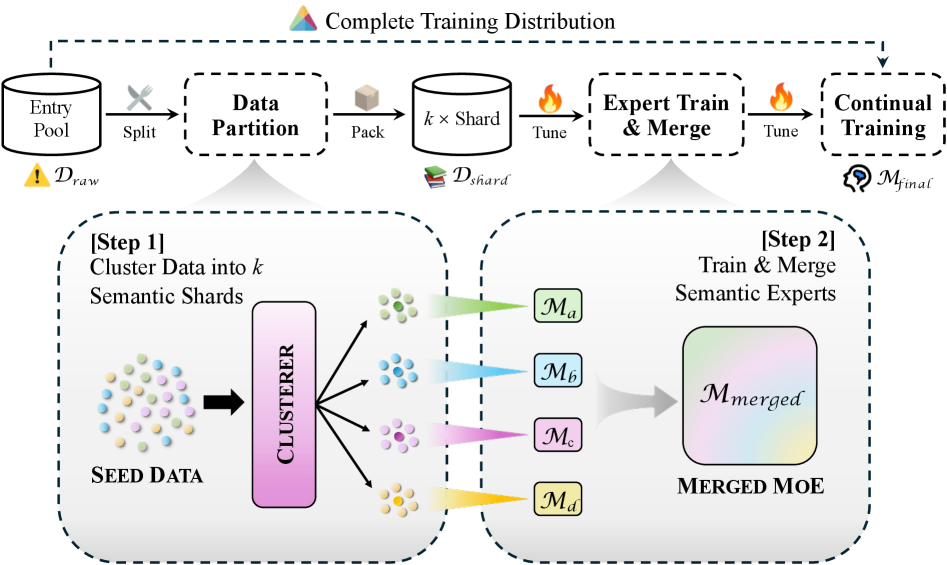
В статье представлена модель LM-Lexicon, использующая разреженную архитектуру Mixture-of-Experts с узкоспециализированными семантическими экспертами для улучшения качества генерируемых определений.
Несмотря на успехи больших языковых моделей, точное и универсальное моделирование определений остается сложной задачей. В данной работе, озаглавленной ‘LM-Lexicon: Improving Definition Modeling via Harmonizing Semantic Experts’, представлен инновационный подход, использующий разреженную архитектуру Mixture-of-Experts с узкоспециализированными семантическими экспертами для повышения качества генерируемых определений. Эксперименты показали значительное улучшение (+7% по метрике BLEU) по сравнению с существующими методами на пяти стандартных бенчмарках, что обусловлено эффективной кластеризацией и семантически-ориентированным распределением задач. Какие перспективы открывает подобный подход для создания более эффективных языковых моделей, ориентированных на семантически насыщенные приложения?
Полисемия и Недостаток Контекста в Моделировании Определений
Традиционное моделирование определений сталкивается с серьезными трудностями при обработке полисемии — явления, когда слово имеет множество значений — и недостаточным пониманием контекста. Это ограничивает практическое применение подобных систем, поскольку они часто не способны точно определить значение слова в конкретной ситуации. Например, слово “ключ” может обозначать инструмент для открывания замка, музыкальную тональность или важный фактор успеха. Без учета контекста, алгоритм может выдать неверное определение, что делает систему бесполезной для задач, требующих высокой точности, таких как автоматический анализ текста, машинный перевод или создание интеллектуальных помощников. В результате, несмотря на десятилетия исследований, эффективное моделирование значений слов остается сложной задачей, требующей новых подходов и технологий.
Несмотря на впечатляющую мощь современных больших языковых моделей, их способность к точному определению терминов в различных областях знаний часто оказывается ограниченной. Эти модели, обучаясь на огромных массивах общего текста, демонстрируют успехи в распознавании паттернов и генерации связного текста, однако им не хватает специализированных знаний, необходимых для корректной интерпретации терминологии в узкоспециализированных дисциплинах, таких как медицина, юриспруденция или инженерия. В результате, определения, генерируемые этими моделями, могут быть неполными, неточными или даже вводящими в заблуждение, особенно когда речь идет о терминах, имеющих несколько значений или требующих глубокого понимания контекста. Эта проблема подчеркивает необходимость разработки методов, позволяющих обогатить языковые модели специализированными знаниями и повысить их способность к точному и надежному определению терминов в различных областях.

LM-Lexicon: Архитектура Разреженных Экспертов
LM-Lexicon использует архитектуру Mixture-of-Experts (MoE), что предполагает распределение знаний между специализированными семантическими экспертами. Вместо одной большой нейронной сети, MoE состоит из множества меньших «экспертов», каждый из которых обучен для обработки определенной подгруппы входных данных или семантических категорий. При получении запроса, механизм маршрутизации направляет его к наиболее подходящим экспертам, что позволяет эффективно использовать вычислительные ресурсы и повысить точность обработки информации. Такая структура позволяет модели лучше справляться со сложными задачами, требующими глубокого понимания семантических нюансов, по сравнению с традиционными плотными моделями.
Для обучения экспертов в LM-Lexicon используется модель Llama-3-8B, подвергнутая тонкой настройке (fine-tuning) на различных семантических кластерах. Эти кластеры формируются посредством кластеризации данных, что позволяет выделить группы понятий со схожим значением. В процессе тонкой настройки каждая модель Llama-3-8B специализируется на определенном семантическом кластере, что повышает ее эффективность в обработке соответствующих запросов и позволяет более точно передавать нюансы значений.
Специализация модели LM-Lexicon на семантических кластерах позволяет ей более точно улавливать нюансы значений слов и фраз. В результате, автоматические метрики оценки, такие как BLEU, демонстрируют улучшение до 10% по сравнению с универсальными языковыми моделями. Это указывает на то, что LM-Lexicon предоставляет более точные и детализированные определения, что особенно важно для задач, требующих глубокого понимания семантики.

Интеллектуальная Маршрутизация для Оптимальной Производительности
В LM-Lexicon используется маршрутизация последовательностей на уровне домена для направления входных последовательностей к соответствующему семантическому эксперту, что повышает точность определения. В отличие от маршрутизации на уровне токенов или всей последовательности, данный подход анализирует общий семантический контекст входных данных, позволяя системе динамически выбирать наиболее компетентного эксперта для обработки конкретного домена. Это достигается за счет предварительной классификации входной последовательности по домену, после чего маршрутизация направляет запрос к соответствующему эксперту, специализирующемуся в данной области знаний. В результате повышается релевантность и точность генерируемых определений.
Подход LM-Lexicon расширяет метод Top-K Routing, обеспечивая более гибрый и детализированный выбор экспертов за счет динамического анализа входных последовательностей. В традиционном Top-K Routing, фиксированное число наиболее вероятных экспертов рассматривается для каждой последовательности. В LM-Lexicon, выбор экспертов происходит на уровне домена, позволяя системе учитывать более широкий семантический контекст и назначать последовательности экспертам, специализирующимся на соответствующих областях знаний. Это приводит к повышению точности определения и более эффективному использованию ресурсов за счет направления запросов к наиболее подходящим специалистам.
В отличие от маршрутизации на уровне токенов или последовательностей, доменная маршрутизация в LM-Lexicon учитывает общий семантический контекст входных данных. Маршрутизация на уровне токенов анализирует каждый токен независимо, а последовательная маршрутизация рассматривает последовательность токенов как единое целое, но оба подхода игнорируют более широкую предметную область запроса. Доменная маршрутизация, напротив, анализирует входную последовательность для определения домена (области знаний), к которому она относится, и направляет запрос соответствующему семантическому эксперту, что позволяет более точно определить намерения пользователя и повысить релевантность ответа.

Эмпирическая Валидация и Прирост Производительности
Оценка модели LM-Lexicon проводилась на стандартных наборах данных для моделирования определений, включая 3D-EX, WordNet, Oxford и Urban. Результаты демонстрируют превосходство LM-Lexicon по сравнению с другими моделями в данной области. Набор данных 3D-EX позволяет оценить способность модели к пониманию и генерации определений для сложных трехмерных объектов, WordNet — к пониманию семантических связей между словами, Oxford — к генерации общеупотребительных определений, а Urban — к пониманию сленговых и неформальных выражений. Комплексное тестирование на этих разнородных наборах данных подтверждает высокую эффективность и универсальность LM-Lexicon в задаче моделирования определений.
Результаты оценки, проведенной с участием людей, подтверждают, что определения, генерируемые LM-Lexicon, последовательно оцениваются как более точные и понятные, превосходя другие модели, особенно в сценариях, требующих глубокого семантического анализа. В ходе оценок участники демонстрировали предпочтение определениям LM-Lexicon по сравнению с результатами, полученными от альтернативных систем, что указывает на превосходство модели в задачах, где важна точность и ясность передачи смысла.
При оценке на наборе данных Urban, модель LM-Lexicon показала результат в 33.81% по метрике Rouge-L. Данный показатель демонстрирует существенное улучшение по сравнению с результатами, полученными другими существующими методами генерации определений. Rouge-L оценивает перекрытие между сгенерированным и эталонным текстом на основе самой длинной общей подпоследовательности, что позволяет количественно оценить качество сгенерированных определений по отношению к эталонным данным.
Полученные результаты демонстрируют, что использование специализированных знаний и интеллектуальной маршрутизации позволяет эффективно решать сложные задачи по генерации нюансированных определений. В отличие от универсальных моделей, LM-Lexicon, благодаря своей архитектуре, направляет процесс генерации через узкоспециализированные модули, что обеспечивает более точное и релевантное описание понятий. Такой подход позволяет учитывать контекст и семантические особенности слова, что особенно важно для сложных и многозначных терминов. Эффективность данной стратегии подтверждается результатами оценки на различных датасетах, включая 3D-EX, WordNet, Oxford и Urban, а также подтверждается данными, полученными в ходе экспертной оценки.
Перспективы Развития и Более Широкое Влияние
Архитектура LM-Lexicon, отличающаяся модульностью, предоставляет уникальную возможность для беспрепятственного добавления новых семантических экспертов. Это позволяет системе постоянно расширять свою базу знаний и адаптироваться к новым типам информации и задачам. В отличие от традиционных языковых моделей, требующих переобучения для включения новых знаний, LM-Lexicon позволяет интегрировать специализированные знания в виде отдельных модулей, что значительно ускоряет процесс обучения и повышает гибкость системы. Такой подход открывает перспективы для создания интеллектуальных систем, способных эффективно работать с разнообразными и постоянно меняющимися данными, и позволяет легко адаптировать систему к специфическим потребностям различных областей применения.
Предлагаемый фреймворк демонстрирует значительный потенциал для широкого спектра приложений, выходящих за рамки базового исследования. В частности, он может быть эффективно использован для построения и обогащения знаний в структурированных базах данных — так называемых графах знаний, где связи между понятиями становятся более явными и доступными для анализа. Более того, архитектура системы позволяет создавать продвинутые системы ответов на вопросы, способные понимать сложные запросы и предоставлять точные и релевантные ответы. Не менее перспективным представляется применение в области автоматизированного создания контента, где фреймворк может служить основой для генерации текстов различного формата и стиля, от новостных статей до креативных описаний, существенно повышая эффективность и скорость производства информации.
Дальнейшие исследования направлены на изучение методов самообучения для автоматического выявления и тренировки новых семантических экспертов. Предполагается, что используя неразмеченные данные, система сможет самостоятельно обнаруживать закономерности и формировать новые знания, не требуя ручного вмешательства. Такой подход позволит значительно расширить возможности LM-Lexicon, сделав её более адаптивной и способной к обучению в динамично меняющихся условиях. Ожидается, что самообучение позволит создавать экспертов, специализирующихся на узких областях знаний, что повысит точность и релевантность ответов системы на сложные запросы и откроет новые перспективы в области автоматической генерации контента и построения интеллектуальных систем.
Представленное исследование демонстрирует стремление к математической чистоте в области моделирования определений. Авторы, создавая LM-Lexicon, фактически строят систему, где каждый «эксперт» в Mixture-of-Experts архитектуре отвечает за строго определенную семантическую область. Это напоминает принцип декомпозиции сложной задачи на более простые, доказуемо корректные подзадачи. Как отмечал Эдсгер Дейкстра: «Простота — это отсутствие ненужных деталей, а не отсутствие деталей». Данный подход к построению sparse моделей, где каждый эксперт специализируется на конкретной области знаний, позволяет достичь высокой точности и обобщающей способности, избегая избыточности и неопределенности, что соответствует стремлению к элегантности и доказуемости алгоритмов.
Куда Дальше?
Представленная работа, несомненно, демонстрирует потенциал разреженных смесей экспертов в задаче моделирования определений. Однако, стоит признать, что гармонизация семантических экспертов — это, скорее, инженерный трюк, нежели принципиальное решение. Иллюзия понимания, создаваемая языковыми моделями, не отменяет необходимости в строгой формализации семантики. До тех пор, пока определение остаётся зависимым от статистических закономерностей, а не от аксиоматической логики, остаётся открытым вопрос о его истинной корректности.
Будущие исследования, вероятно, столкнутся с необходимостью преодоления ограничения доменной адаптации. Создание универсальной модели определений, способной к обобщению за пределы узкоспециализированных областей, представляется задачей, требующей не просто увеличения объёма данных, а фундаментального переосмысления принципов представления знаний. Необходимо искать способы интеграции символьных и нейронных подходов, чтобы выйти за рамки простой эмуляции интеллектуальной деятельности.
В конечном итоге, успех в моделировании определений будет зависеть не от сложности архитектуры, а от строгости критериев оценки. До тех пор, пока модель способна лишь «убедительно» сформулировать определение, а не доказать его истинность, она останется лишь инструментом для манипулирования информацией, а не средством достижения истинного знания.
Оригинал статьи: https://arxiv.org/pdf/2602.14060.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Конфиденциальный анализ больших данных: новый подход к быстрым ответам
- Автоматическая оптимизация вычислений: новый подход к библиотекам математических функций
- Взрыв скорости: Оптимизация внимания для современных GPU
- Текстуры вместо Гауссиан: Новый подход к синтезу видов
- Квантовый импульс для нейросетей: новый подход к распознаванию изображений
- Ожившие Пиксели: Создание Реалистичных Видео с Сохранением Личности
- Языковые модели и границы возможного: что делает язык человеческим?
- Гендерные стереотипы в найме: что скрывают языковые модели?
- Искусственный интеллект на страже экологии: защита данных и справедливые алгоритмы
- Игры без модели: новый подход к управлению в условиях неопределенности
2026-02-17 18:20