Автор: Денис Аветисян
Исследователи представили GLM-5, открытую языковую модель, демонстрирующую впечатляющие возможности в решении сложных задач и способную конкурировать с закрытыми аналогами.
GLM-5 — это эффективная и адаптивная модель с открытым исходным кодом, демонстрирующая передовые результаты в задачах агентного управления и проходящая строгие тесты на безопасность.
Несмотря на значительные успехи в области больших языковых моделей, переход от простого кодирования «вайбов» к действительно автономной работе остается сложной задачей. В статье ‘GLM-5: from Vibe Coding to Agentic Engineering’ представлена новая модель GLM-5, разработанная для преодоления этого разрыва и демонстрирующая передовые результаты в задачах, требующих автономного планирования и выполнения. Благодаря внедрению DSA и асинхронной инфраструктуры обучения с подкреплением, GLM-5 достигает высокой эффективности и превосходной производительности на ключевых бенчмарках, превосходя существующие решения в области разработки программного обеспечения. Способна ли GLM-5 стать основой для создания действительно интеллектуальных агентов, способных решать сложные задачи в реальном мире?
Основа для Нового Интеллекта: GLM-5
Современные фундаментальные модели, несмотря на впечатляющие достижения в обработке языка и генерации контента, часто демонстрируют ограниченные возможности в решении задач, требующих сложного логического мышления и анализа. Это связано с тем, что традиционные архитектуры испытывают трудности при масштабировании — увеличение размера модели не всегда приводит к пропорциональному улучшению производительности, а также требует экспоненциального роста вычислительных ресурсов. В результате, потенциал искусственного интеллекта остается нереализованным, поскольку модели не способны эффективно обрабатывать многоступенчатые рассуждения, извлекать сложные взаимосвязи и обобщать знания на новые, ранее не встречавшиеся ситуации. Данные ограничения препятствуют созданию по-настоящему интеллектуальных систем, способных решать сложные проблемы и адаптироваться к меняющимся условиям.
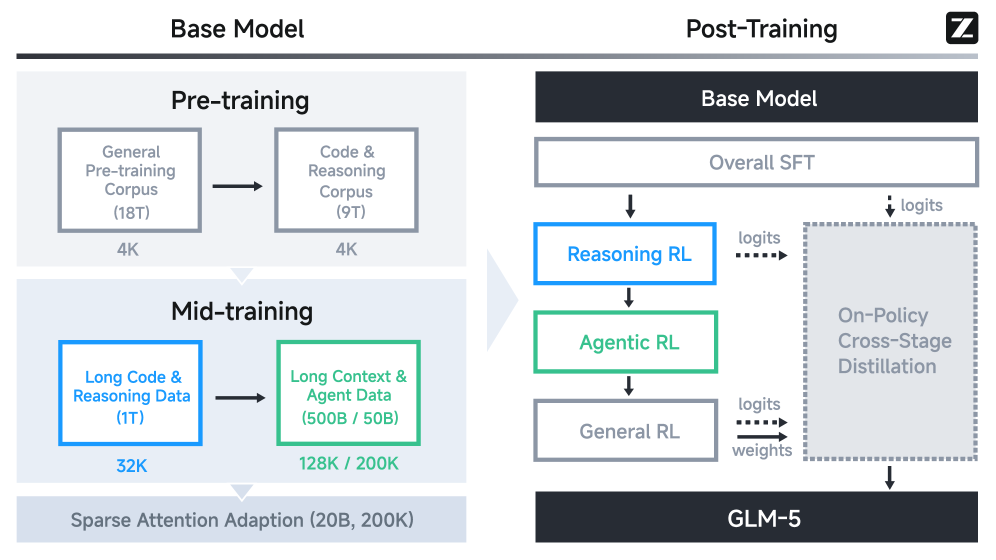
Архитектура GLM-5 представляет собой инновационный подход к созданию фундаментальных моделей, направленный на преодоление ограничений, присущих существующим системам. В ее основе лежит сочетание принципов Mixture of Experts (MoE) и оптимизированных механизмов внимания. MoE позволяет модели динамически выбирать наиболее подходящих “экспертов” для обработки конкретных входных данных, значительно повышая эффективность и масштабируемость. Оптимизированные механизмы внимания, в свою очередь, фокусируются на наиболее релевантных частях входной последовательности, уменьшая вычислительную нагрузку и улучшая качество рассуждений. Такое сочетание позволяет GLM-5 демонстрировать повышенную производительность в сложных задачах, требующих глубокого понимания и логического вывода, а также эффективно масштабироваться для обработки больших объемов данных.
Проверка на Прочность: Валидация Способностей GLM-5
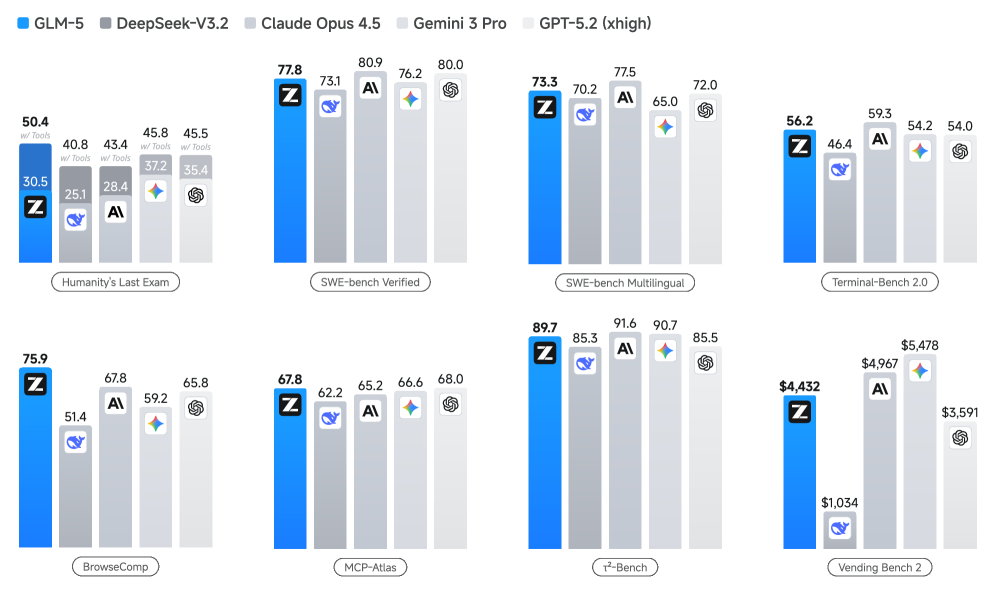
Модель GLM-5 демонстрирует превосходные результаты на различных бенчмарках, включая SWE-bench, Humanity’s Last Exam и Terminal-Bench, что подтверждает её высокие навыки решения задач. SWE-bench оценивает способность модели к написанию кода, Humanity’s Last Exam проверяет широкий спектр когнитивных способностей, а Terminal-Bench фокусируется на решении задач через взаимодействие с командной строкой. Успешное прохождение этих тестов указывает на комплексные возможности GLM-5 в областях программирования, рассуждений и практического применения знаний, что позволяет ей эффективно решать разнообразные поставленные задачи.
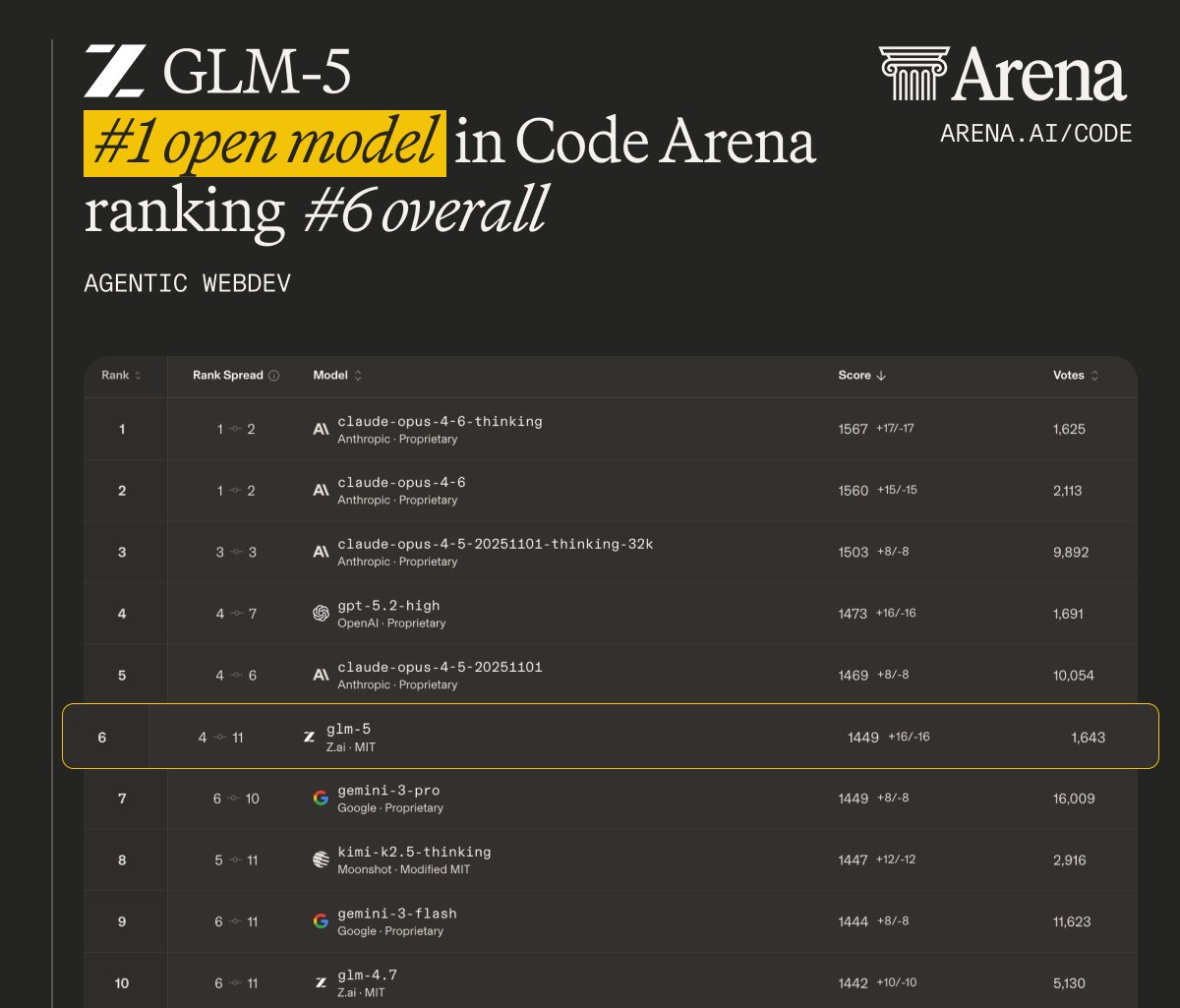
В ходе тестирования на бенчмарке Humanity’s Last Exam, модель GLM-5 продемонстрировала результаты, сопоставимые с показателями Claude Opus 4.5. При этом, GLM-5 превзошла модель Gemini 3 Pro по общему баллу, подтверждая её высокий уровень понимания и решения сложных задач, требующих широкого спектра знаний и навыков логического мышления. Данный результат указывает на конкурентоспособность GLM-5 в области оценки когнитивных способностей искусственного интеллекта.
В ходе тестирования на Vending-Bench 2 модель GLM-5 продемонстрировала итоговый баланс счета в размере $4,432. Данный результат позволяет оценить ее эффективность в задачах, требующих планирования и управления ресурсами в динамической среде. Показатель близок к результату, достигнутому моделью Claude Opus 4.5, что подтверждает высокую конкурентоспособность GLM-5 в задачах, связанных с взаимодействием с виртуальными средами и выполнением последовательности действий для достижения определенной финансовой цели.
Модель GLM-5 демонстрирует развитые навыки работы с инструментами и API, что подтверждается результатами на бенчмарках MCP-Atlas и Vending Bench 2. На MCP-Atlas модель успешно выполняет задачи, требующие взаимодействия с различными API для достижения поставленной цели. В рамках Vending Bench 2, GLM-5 показала способность эффективно управлять виртуальным счетом и совершать покупки, используя API для взаимодействия с торговыми автоматами и другими сервисами, что свидетельствует о ее способности к планированию и выполнению сложных задач, требующих внешних взаимодействий.
Модель GLM-5 демонстрирует передовые навыки веб-навигации и поиска информации, что подтверждается результатами на бенчмарке BrowseComp. В рамках данного бенчмарка GLM-5 достигла наилучших показателей среди моделей с открытым исходным кодом, превзойдя DeepSeek-V3.2 и Kimi K2.5. Это указывает на способность модели эффективно извлекать и обрабатывать информацию из сети Интернет для решения поставленных задач.
Оптимизация и Эффективность: Технические Основы GLM-5
Модель GLM-5 оптимизирована для снижения вычислительных затрат за счет использования FlashAttention и DSA (DeepSeek Sparse Attention). FlashAttention использует алгоритмы, которые минимизируют обращения к медленной памяти во время вычисления механизма внимания, что значительно ускоряет процесс. DSA, в свою очередь, применяет разреженную матрицу внимания, отбрасывая незначимые связи между токенами, что снижает объем вычислений без существенной потери качества модели. Комбинация этих двух технологий позволяет GLM-5 достигать высокой производительности при значительно меньших вычислительных ресурсах, чем традиционные модели внимания.
Квантизация W4A8 позволяет значительно уменьшить размер модели GLM-5, используя 4-битное представление для весов и 8-битное для активаций. Этот метод снижает требования к памяти и вычислительным ресурсам, делая возможным развертывание модели на устройствах с ограниченными ресурсами, таких как мобильные телефоны и встроенные системы. Применение W4A8 приводит к уменьшению размера модели примерно в 4 раза по сравнению с использованием 16-битных чисел с плавающей точкой, при этом сохраняется приемлемый уровень производительности благодаря оптимизированной реализации и компенсации потерь точности.
Оптимизатор Muon обеспечивает эффективное обучение модели GLM-5, используя адаптивные стратегии изменения скорости обучения и момента для ускорения сходимости и повышения стабильности. В сочетании с системой Agent-as-a-Judge, представляющей собой автоматизированную систему оценки, обеспечивается непрерывное улучшение модели. Agent-as-a-Judge использует набор заранее определенных метрик и критериев для оценки качества генерируемого текста, предоставляя обратную связь для дальнейшей оптимизации процесса обучения и корректировки параметров модели. Данный подход позволяет автоматизировать процесс оценки и снизить потребность в ручной аннотации данных, что существенно ускоряет цикл разработки и улучшает общую производительность GLM-5.
За Пределами Тестов: Влияние и Потенциал GLM-5
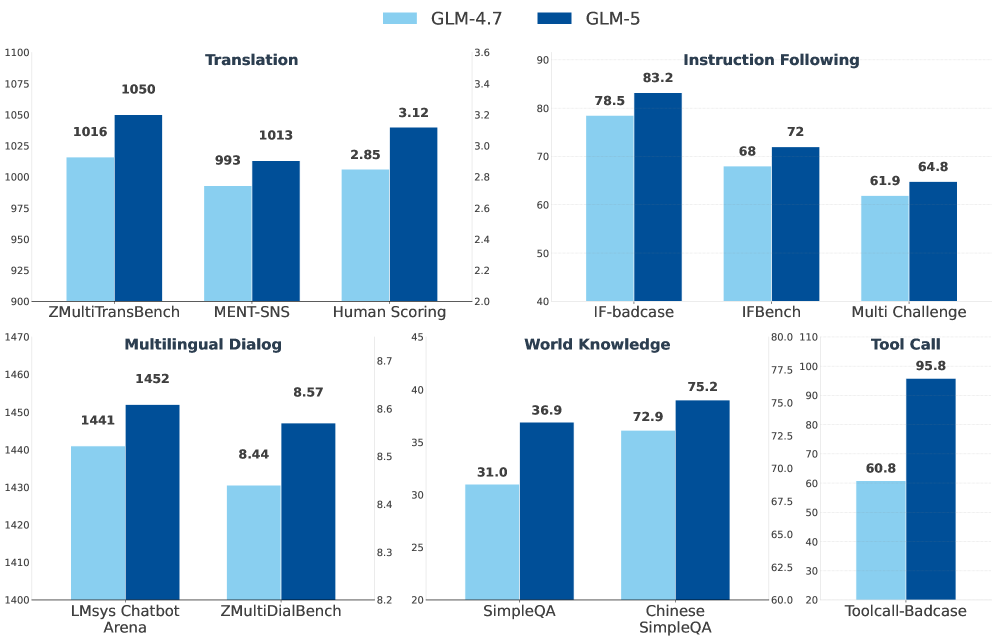
Успехи модели GLM-5 в тесте ZMultiTransBench ярко демонстрируют её выдающиеся многоязычные возможности, открывая новые перспективы в сфере глобальной коммуникации и доступа к информации. Эта способность к эффективной обработке и генерации текстов на различных языках позволяет преодолевать языковые барьеры, обеспечивая более широкое распространение знаний и способствуя международному сотрудничеству. Благодаря GLM-5, пользователи по всему миру получают возможность взаимодействовать с информацией и друг с другом без ограничений, связанных с лингвистическими различиями, что особенно важно в эпоху глобализации и растущей взаимосвязанности.
Модель GLM-5 продемонстрировала передовые результаты в многоязыковом бенчмарке SWE-bench Multilingual, превзойдя по своим показателям такие мощные системы, как Gemini 3 Pro и Claude Opus 4.5. Этот успех свидетельствует о значительном прогрессе в области кросс-лингвистического понимания и генерации текста, открывая новые возможности для глобального общения и обработки информации на различных языках. Превосходство GLM-5 в данном тесте подчеркивает её способность эффективно работать с лингвистически разнообразными данными, что делает её ценным инструментом для задач, требующих высокой точности перевода и понимания нюансов разных языков.
В ходе тестирования на Tau2-Bench, GLM-5 продемонстрировала производительность, сопоставимую с одной из самых передовых проприетарных моделей — Claude Opus 4.5. Tau2-Bench, представляющий собой сложный набор задач, предназначенных для оценки способности модели к рассуждению и решению проблем, позволил выявить высокую эффективность GLM-5 в областях, требующих глубокого понимания контекста и генерации логически обоснованных ответов. Этот результат подчеркивает, что GLM-5 не только успешно справляется со стандартными бенчмарками, но и способна конкурировать с лидерами индустрии в более сложных сценариях, открывая новые возможности для применения модели в различных областях, от автоматизации бизнес-процессов до разработки интеллектуальных помощников.
Модель GLM-5 продемонстрировала превосходство над DeepSeek-V3.2 в ряде ключевых бенчмарков, тем самым устанавливая новый эталон производительности для моделей с открытым исходным кодом. Данное достижение подчеркивает значительный прогресс в области разработки доступных и высокоэффективных языковых моделей, открывая возможности для широкого спектра применений — от автоматического перевода и создания контента до сложных систем анализа данных. Превосходство над DeepSeek-V3.2 не только подтверждает техническую состоятельность GLM-5, но и стимулирует дальнейшие исследования и инновации в сообществе разработчиков открытого программного обеспечения, способствуя более быстрому развитию искусственного интеллекта и его внедрению в различные сферы жизни.
Сочетание возможностей GLM-5 и принципов Agentic Engineering открывает путь к созданию действительно автономных агентов искусственного интеллекта, способных к сложному планированию и исполнению задач. Данные агенты, в отличие от традиционных систем, способны самостоятельно определять цели, разрабатывать стратегии их достижения и адаптироваться к изменяющимся условиям. Оценка общего уровня интеллекта таких систем осуществляется посредством Индекса Искусственного Аналитического Интеллекта (Artificial Analysis Intelligence Index), позволяющего количественно измерить способность агента к решению разнообразных задач, требующих логического мышления, анализа данных и творческого подхода. Такой подход позволяет не только оценивать прогресс в области искусственного интеллекта, но и стимулирует разработку более совершенных и эффективных автономных систем.
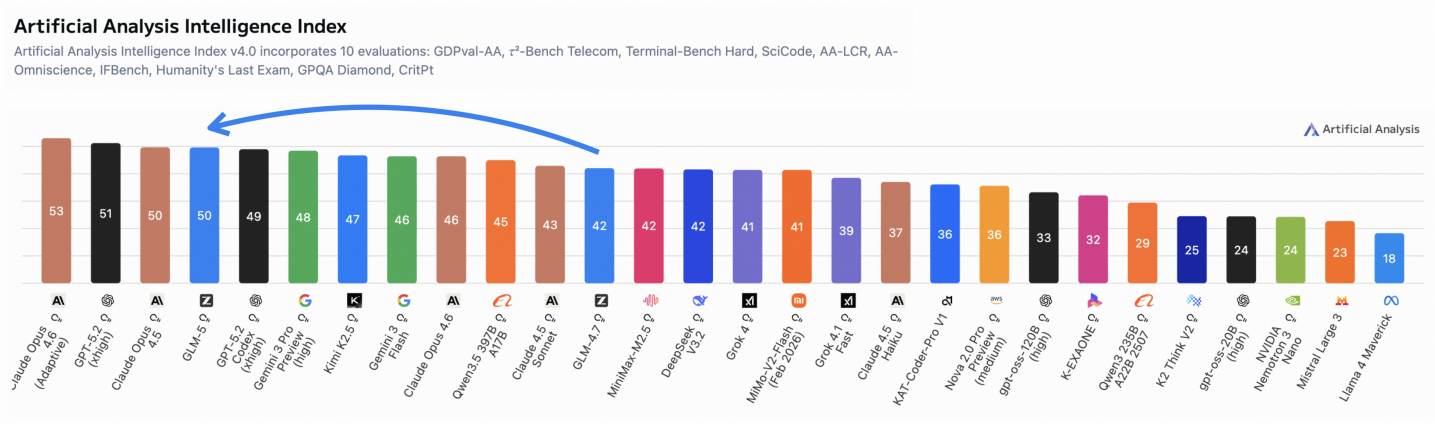
Изучение GLM-5, как и наблюдение за эволюцией любой сложной системы, неизбежно подводит к мысли о тщетности поисков идеального решения. Разработчики стремятся к агентности, эффективности, открытости модели, но рано или поздно всё упрётся в неизбежный технический долг. Кен Томпсон как-то заметил: «Вся революционная технология завтра станет техдолгом». И это справедливо: каждая новая функция, каждое усложнение архитектуры — это потенциальная головная боль в будущем. Модель может демонстрировать впечатляющие результаты на текущих бенчмарках, но реальный мир всегда найдёт способ сломать даже самую элегантную теорию, а документация, как известно, — это лишь форма коллективного самообмана. Впрочем, если баг воспроизводится, можно с уверенностью сказать — у нас стабильная система.
Что дальше?
Представленная работа, демонстрируя очередное улучшение метрик в области «агентных» моделей, неизбежно ставит вопрос о том, что будет дальше. Не о новых бенчмарках, разумеется — они всегда найдутся. Скорее, о том, как быстро эти самые «агенты» начнут искать способы обойти те самые ограничения, которые с таким энтузиазмом на них накладываются. Каждая «революционная» архитектура — это лишь отсрочка неизбежного технического долга, и рано или поздно станет понятно, что оптимизация под бенчмарк — это не то же самое, что реальное понимание.
Упор на «эффективность» и «адаптивность» — ход логичный, но наивный. Продакшен всегда найдёт способ сломать элегантную теорию. Достаточно вспомнить, как легко автоматизация может превратиться в катастрофу. И пока исследователи гоняются за параметрами, где-то в продакшене уже тестируют скрипт, который случайно удалит базу данных.
В конечном итоге, вся эта гонка за «открытыми весами» напоминает попытку построить дамбу из песка. Да, на какое-то время она может сдержать поток, но рано или поздно вода найдёт способ обойти препятствие. И тогда придётся начинать всё сначала, с новой архитектурой и новыми обещаниями.
Оригинал статьи: https://arxiv.org/pdf/2602.15763.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, планирующий путешествия: новый подход к сложным задачам
- Искусственный интеллект и квантовая физика: кто кого?
- Большие языковые модели как судьи перевода: бюджет на размышления и калибровка реальности.
- Квантовый импульс для нейросетей: новый подход к распознаванию изображений
- Таблицы оживают: Искусственный интеллект осваивает структурированные данные
- Взрыв скорости: Оптимизация внимания для современных GPU
- Гендерные стереотипы в найме: что скрывают языковые модели?
- Текстуры вместо Гауссиан: Новый подход к синтезу видов
- Законы масштабирования и архитектура: к пределу эффективности вычислений в больших языковых моделях.
- Наука на благо бизнеса: как публикации стимулируют инновации
2026-02-18 21:07