Автор: Денис Аветисян
Новая система VoxServe обеспечивает бесперебойную и сверхбыструю обработку речевых моделей, открывая возможности для приложений реального времени.
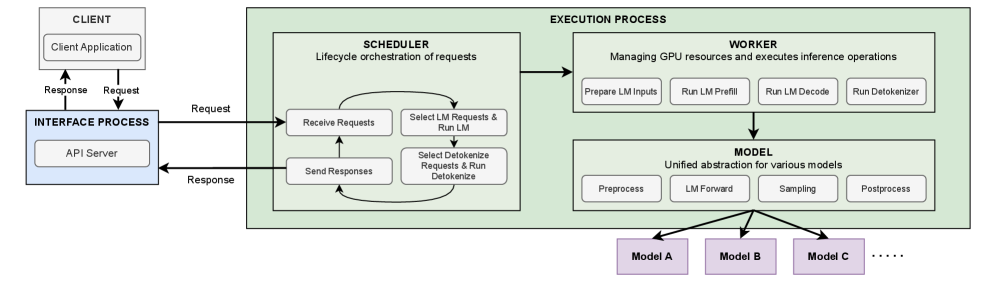
VoxServe — это унифицированная система обслуживания речевых языковых моделей, оптимизированная для потоковой обработки, снижения задержек и эффективного планирования ресурсов.
Развертывание современных моделей обработки речи (SpeechLM) в потоковых приложениях требует систем с низкой задержкой и высокой пропускной способностью, однако существующие решения зачастую не обеспечивают гибкую и эффективную поддержку разнообразных архитектур моделей. В данной работе представлена система ‘VoxServe: Streaming-Centric Serving System for Speech Language Models’ — унифицированная платформа для обслуживания SpeechLM, оптимизированная для потоковой обработки. VoxServe вводит абстракцию выполнения моделей, отделяющую архитектуру модели от системных оптимизаций, и реализует потоко-ориентированное планирование и асинхронный конвейер вывода, что позволяет добиться 10-20-кратного увеличения пропускной способности при сравнимой задержке. Какие перспективы открывает подобный подход для создания более эффективных и масштабируемых систем распознавания и синтеза речи в реальном времени?
Традиционные подходы и их ограничения
Традиционные системы синтеза речи зачастую сталкиваются с трудностями в достижении естественного звучания и гибкости адаптации к различным контекстам. Эти системы, как правило, полагаются на сложные конвейеры обработки, требующие кропотливой настройки для каждого голоса и стиля речи. В результате, синтезированная речь может звучать роботизированно, монотонно или неестественно, особенно при обработке сложных предложений или нетипичных интонаций. Кроме того, адаптация к новым голосам или языкам требует значительных усилий и ресурсов, ограничивая масштабируемость и универсальность подобных систем. Отсутствие способности к обобщению и адаптации к новым данным делает традиционные подходы менее эффективными в условиях быстро меняющихся потребностей пользователей.
В основе новой системы SpeechLM лежит принципиально иной подход к синтезу речи, использующий возможности больших языковых моделей (LLM). Традиционные системы синтеза часто испытывают трудности с достижением естественности и адаптивности, поскольку оперируют с акустическими сигналами напрямую. SpeechLM же рассматривает речь как последовательность дискретных токенов, подобно тому, как LLM обрабатывают текст. Это позволяет использовать уже обученные языковые модели для генерации речи с высокой степенью реалистичности и выразительности, открывая новые горизонты в области голосовых технологий и взаимодействия человека с машиной. Благодаря такому подходу, система способна генерировать речь, которая звучит более естественно и эмоционально окрашенно, приближаясь к человеческой.
В основе подхода SpeechLM лежит новаторская концепция представления речи как последовательности дискретных токенов, что позволяет использовать мощь предварительно обученных больших языковых моделей (LLM) для синтеза звука. Вместо традиционного подхода, оперирующего с акустическими параметрами, SpeechLM преобразует речевой сигнал в серию дискретных единиц, аналогичных словам в текстовом корпусе. Это позволяет применять проверенные методы обучения LLM, такие как самообучение на огромных объемах данных, к задаче синтеза речи. В результате, система способна генерировать более реалистичную и выразительную речь, обладающую повышенной точностью и естественностью, поскольку LLM уже обучены понимать и генерировать сложные языковые структуры и нюансы.
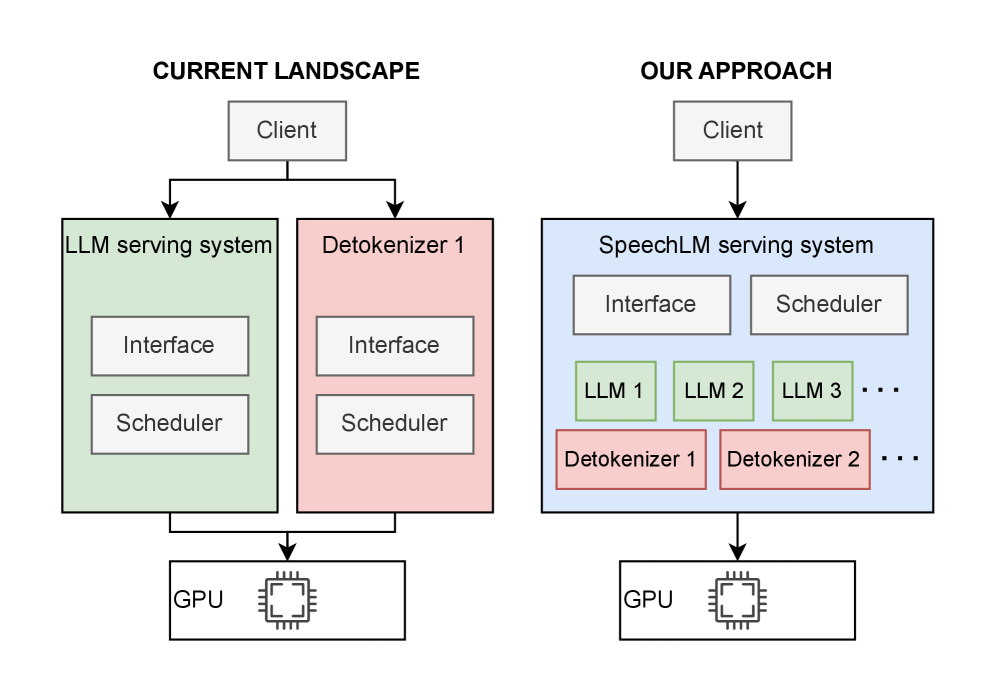
VoxServe: Оптимизация для потоковой передачи в реальном времени
Обеспечение низких задержек и экономичной потоковой обработки критически важно для успешной работы SpeechLM. Высокая задержка негативно сказывается на пользовательском опыте в реальном времени, а высокие затраты на инфраструктуру могут сделать масштабирование невозможным. Для эффективной работы SpeechLM требуется система, способная обрабатывать большие объемы потоковых данных с минимальной задержкой и при оптимальном использовании ресурсов, что напрямую влияет на стоимость обслуживания и доступность сервиса для широкой аудитории.
VoxServe — это специализированная система обслуживания, разработанная для решения задач, связанных с низкой задержкой и экономичной эффективностью потоковой передачи. В основе её архитектуры лежит асинхронная обработка запросов, позволяющая параллельно выполнять различные этапы обработки речи и, таким образом, увеличивать пропускную способность. Эффективное использование ресурсов достигается за счет оптимизации выделения памяти и вычислительных мощностей, а также за счет минимизации накладных расходов, связанных с передачей данных между компонентами системы. Такой подход позволяет VoxServe обрабатывать значительно больше запросов при сравнимых показателях задержки по сравнению с традиционными системами.
Система VoxServe демонстрирует увеличение скорости обработки запросов в 10-20 раз по сравнению с существующими реализациями, при этом сохраняя сопоставимую задержку ответа. Данный показатель достигается благодаря оптимизированной архитектуре, позволяющей обрабатывать значительно большее количество параллельных запросов без увеличения времени отклика. Это обеспечивает более эффективное использование ресурсов и повышает пропускную способность системы, что критически важно для задач потоковой обработки речи в реальном времени.
Для максимизации пропускной способности и минимизации времени отклика, VoxServe использует методы параллелизма данных и разделенного вывода. Параллелизм данных позволяет обрабатывать несколько запросов одновременно, распределяя нагрузку между доступными ресурсами. Разделенный вывод, в свою очередь, предполагает разделение процесса инференса на отдельные этапы, которые могут выполняться независимо друг от друга и на различных вычислительных узлах, что позволяет повысить эффективность использования оборудования и снизить задержки. Комбинация этих техник позволяет VoxServe достигать значительно более высокой производительности по сравнению с традиционными подходами к обслуживанию потоковых данных.
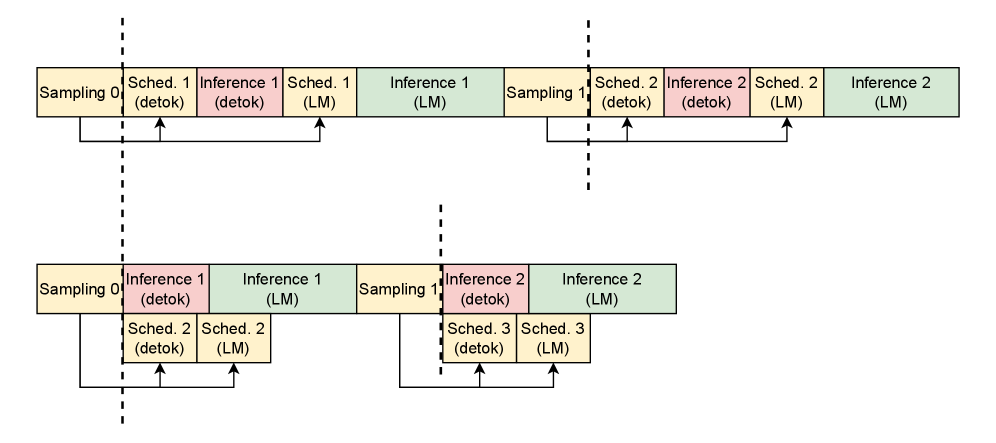
Тонкая настройка: Кэширование и разбиение на фрагменты
Для обеспечения непрерывного воспроизведения потокового аудио, системы должны предварительно загружать и обрабатывать аудиофрагменты (chunks). Этот подход позволяет компенсировать задержки, связанные с сетевой передачей данных и обработкой модели преобразования текста в речь (TTS). Предварительная загрузка и обработка позволяют модели TTS начать генерацию аудио до того, как закончится воспроизведение предыдущего фрагмента, что критически важно для поддержания бесшовного пользовательского опыта. Размер фрагментов и стратегия прогнозирования будущих потребностей в аудио определяют эффективность данной системы и напрямую влияют на задержку и стабильность потока.
Для минимизации задержки и обеспечения бесперебойной потоковой передачи VoxServe использует детокенизацию по частям (chunk-wise detokenization) и стратегическое кэширование (KV Cache). Этот подход позволяет обрабатывать аудиопоток небольшими фрагментами, что снижает требования к памяти и ускоряет процесс генерации речи. Кэш KV (Key-Value) хранит промежуточные результаты обработки для каждого фрагмента, что позволяет избежать повторных вычислений при последующих запросах. Эффективное использование KV Cache значительно сокращает время отклика системы и обеспечивает плавную потоковую передачу аудио.
Эффективное управление кэшем и оптимизированные алгоритмы планирования (Scheduling Algorithm) критически важны для максимизации частоты попаданий в кэш (cache hit rate) и минимизации задержек обработки. Высокая частота попаданий в кэш позволяет избежать повторных вычислений и повторной загрузки данных, что значительно снижает латентность. Алгоритмы планирования, в свою очередь, оптимизируют порядок обработки аудио-фрагментов (chunks), чтобы приоритезировать наиболее важные данные и минимизировать время ожидания. Комбинация этих двух подходов позволяет поддерживать непрерывное воспроизведение и высокую производительность системы даже при использовании ресурсоемких моделей и больших объемов данных.
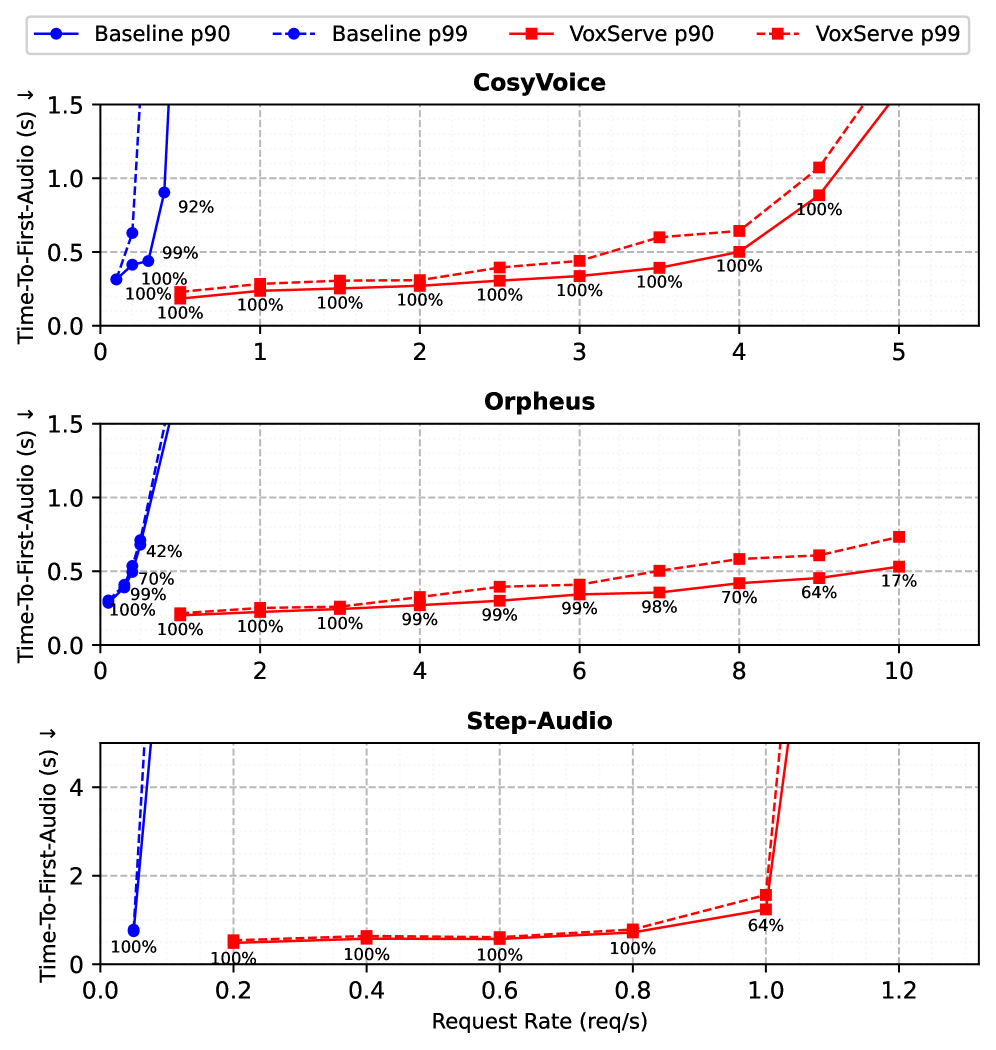
Оптимизированный планировщик в VoxServe обеспечивает 134-кратное увеличение пропускной способности, измеряемое как Real-Time Factor (RTF). Это означает, что система способна обрабатывать аудиоданные в 134 раза быстрее по сравнению с неоптимизированной реализацией. Достижение данного прироста производительности является результатом эффективного распределения ресурсов и минимизации задержек при обработке аудио-чанков, что критически важно для обеспечения непрерывного и высококачественного потокового воспроизведения. Повышение RTF напрямую влияет на возможность обработки больших объемов данных в реальном времени и поддержание низкой латентности при потоковой передаче.
В ходе тестирования VoxServe демонстрирует 100% стабильность потоковой передачи (streaming viability) для всех протестированных моделей и конфигураций экспериментов. Это подтверждается результатами, полученными в различных сценариях использования и при работе с различными архитектурами моделей синтеза речи. Отсутствие прерываний или сбоев в потоке данных гарантирует непрерывное воспроизведение аудио, что является критически важным требованием для интерактивных приложений и сервисов, использующих синтез речи в реальном времени.
Для дальнейшей оптимизации производительности VoxServe используется технология CUDA Graph, позволяющая снизить накладные расходы и ускорить запуск ядер GPU. CUDA Graph компилирует последовательность операций GPU в единый граф, который затем выполняется как единая операция, минуя отдельные вызовы ядер и связанные с ними задержки. Это значительно сокращает время, необходимое для подготовки и запуска каждого этапа обработки аудио, что особенно важно для задач потоковой передачи в реальном времени. Использование CUDA Graph позволяет минимизировать накладные расходы на запуск ядра и повысить общую эффективность обработки, что способствует увеличению скорости потоковой передачи и снижению задержки.
Влияние данных: Обучение и оценка
Эффективность систем SpeechLM и VoxServe напрямую зависит от качества и разнообразия используемых наборов данных для обучения и оценки. Недостаточность или предвзятость в данных может привести к снижению реалистичности синтезируемой речи, ограниченному диапазону поддерживаемых голосов и акцентов, а также к ошибкам в произношении. Тщательный отбор и подготовка данных, включающих широкий спектр лингвистических особенностей и акустических характеристик, критически важны для достижения высокого уровня производительности и обеспечения надежной работы систем в различных сценариях использования. Именно поэтому разработчики уделяют особое внимание созданию и использованию обширных и тщательно размеченных датасетов, способных охватить все нюансы человеческой речи.
Для создания надежных систем синтеза речи, таких как SpeechLM и VoxServe, крайне важны разнообразные и качественные наборы данных. Ресурсы, такие как LibriTTS, HiFi Multi-Speaker English TTS и LJ Speech, предоставляют широкий спектр голосовых характеристик, акцентов и стилей речи, что позволяет моделям обучаться более эффективно и генерировать более реалистичные и выразительные высказывания. Разнообразие данных обеспечивает устойчивость системы к различным условиям и запросам, а высокое качество записей минимизирует искажения и шумы, что напрямую влияет на воспринимаемость и естественность синтезированной речи. В результате, использование этих наборов данных позволяет создавать системы, способные генерировать речь, практически неотличимую от человеческой.
Обучение на тщательно подобранных наборах данных, таких как LibriTTS, HiFi Multi-Speaker English TTS и LJ Speech, позволяет SpeechLM создавать удивительно естественную и выразительную речь для широкого спектра голосов и акцентов. Модель не просто воспроизводит звуки, но и передает нюансы произношения, интонации и эмоциональную окраску, что делает синтезированную речь практически неотличимой от человеческой. Такая способность к адаптации и реалистичности открывает новые возможности для применения в голосовых помощниках, аудиокнигах, системах озвучивания и других областях, где важна качественная и правдоподобная передача речи.
Сочетание передовой архитектуры SpeechLM и высококачественных наборов данных для обучения открывает новую эру в синтезе речи. Благодаря этому симбиозу, системы способны генерировать не просто понятную, но и удивительно реалистичную, эмоционально окрашенную речь, максимально приближенную к естественной. Это достигается за счет способности модели учитывать тончайшие нюансы произношения, интонации и тембра голоса, что позволяет создавать голосовые помощники, озвучивание текстов и другие приложения, отличающиеся беспрецедентным уровнем отзывчивости и естественности. Такой подход позволяет преодолеть ограничения предыдущих поколений систем синтеза речи, предлагая пользователям более комфортное и интуитивно понятное взаимодействие с технологиями.

Разработка VoxServe, как и любая система, стремящаяся к оптимизации стриминговой обработки SpeechLM, неизбежно сталкивается с компромиссами. Авторы стремятся к снижению задержки и повышению производительности, но, как показывает практика, любое усложнение архитектуры рано или поздно порождает новые узкие места. В этой гонке за эффективностью легко забыть о простоте и поддерживаемости. Клод Шеннон как-то заметил: «Теория коммуникации — это не только передача информации, но и борьба с шумом». В контексте VoxServe, «шумом» можно считать избыточную сложность, которая мешает системе оставаться гибкой и адаптируемой к меняющимся требованиям. Система абстрагирует модели и оптимизирует планирование, но, в конечном итоге, все равно остается инструментом, который нужно поддерживать и развивать.
Куда Поведёт Нас Река?
Представленная система, VoxServe, безусловно, демонстрирует улучшения в потоковой обработке речевых моделей. Однако, оптимизация ради оптимизации — занятие, как известно, бесконечное. Каждая победа над задержкой неминуемо откроет новые узкие места. Неизбежно возникнет вопрос о масштабируемости не только самой системы, но и инфраструктуры, на которой она развёрнута. Ведь «масштабируемость» — это, как правило, эвфемизм для «ещё не протестировали под реальной нагрузкой».
Интереснее выглядит заявленная абстракция модели. Но и здесь кроется подвох. Заманчиво, конечно, менять модели «на лету», но сколько времени и ресурсов потребуется на валидацию каждой новой итерации? А как быть с несовместимостью форматов, неожиданными зависимостями и прочим «наследием» предыдущих поколений? Часто бывает, что монолит, пусть и громоздкий, оказывается надёжнее сотни микросервисов, каждый из которых по-своему врёт.
В конечном счёте, задача не в создании «универсальной» системы, а в поиске баланса между гибкостью, производительностью и, что самое главное, — реальностью. Ведь в конечном итоге, все эти «революционные» технологии неизбежно превращаются в технический долг. И рано или поздно придётся за него расплачиваться.
Оригинал статьи: https://arxiv.org/pdf/2602.00269.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Взлом языковых моделей: эволюция атак, а не подсказок
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Эволюция Симуляций: От Агентов к Сложным Социальным Системам
- Квантовые хроники: Последние новости в области квантовых исследований и разработки.
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Самообучающиеся агенты: новый подход к автономным системам
- В поисках оптимального дерева: новые горизонты GPU-вычислений
- Искусственный интеллект, который знает, когда ему нужна подсказка
- Роботы учатся видеть: новая стратегия управления на основе видео
2026-02-04 03:37