Автор: Денис Аветисян
Новая GPU-оптимизированная платформа cuRPQ значительно ускоряет обработку сложных графовых запросов, открывая возможности для анализа огромных объемов данных.
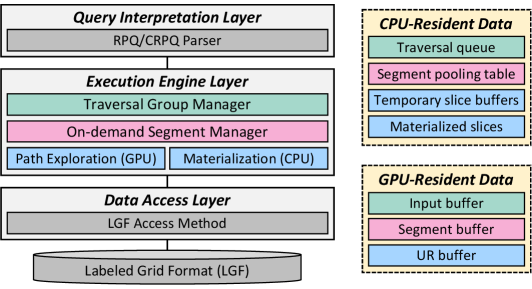
cuRPQ — высокопроизводительное фреймворк для обработки регулярных и конъюнктивных регулярных запросов к графовым базам данных, использующий параллельную обработку и инкрементную материализацию.
Несмотря на возрастающую потребность в анализе связности графов, вычисление запросов на регулярные и конъюнктивные регулярные пути (RPQ и CRPQ) остается вычислительно сложной задачей. В данной работе представлена система ‘cuRPQ: A High-Performance GPU-Based Framework for Processing Regular and Conjunctive Regular Path Queries’, оптимизированный фреймворк для GPU, позволяющий значительно ускорить обработку RPQ и CRPQ благодаря инновационному алгоритму обхода и эффективному управлению посещенными узлами. Экспериментальные результаты демонстрируют, что cuRPQ превосходит существующие методы на порядки величины, избегая ошибок, связанных с нехваткой памяти. Возможно ли дальнейшее повышение производительности за счет использования новых архитектур GPU и оптимизации алгоритмов параллельного обхода графов?
Преодолевая Границы Масштаба: Вызовы Графовых Запросов
Традиционные методы запросов к графам сталкиваются с растущими трудностями при работе с современными, масштабными наборами данных, что серьезно ограничивает возможности анализа графов знаний и других приложений. Увеличение количества узлов и связей в графе приводит к экспоненциальному росту вычислительной сложности, поскольку алгоритмы обхода и поиска оказываются неспособны эффективно обрабатывать такие объемы информации. В результате, даже относительно простые запросы могут занимать значительное время, делая интерактивный анализ невозможным и препятствуя извлечению ценной информации из сложных взаимосвязей, представленных в графе. Это особенно критично в областях, где требуется оперативное принятие решений на основе анализа больших данных, таких как обнаружение мошенничества, рекомендательные системы и биоинформатика.
Традиционные методы обработки запросов к графам, часто опирающиеся на центральный процессор (CPU), сталкиваются с серьезными ограничениями при работе с современными, масштабными наборами данных. Использование CPU для выполнения операций обхода графа и сопоставления с образцом создает узкое место, существенно замедляя производительность и ограничивая возможности масштабирования. Поскольку объемы данных экспоненциально растут, а сложность запросов увеличивается, зависимость от CPU-ориентированных решений становится все более проблематичной, препятствуя эффективному анализу и извлечению полезной информации из больших графов знаний. В результате, исследователи активно ищут альтернативные подходы, такие как аппаратное ускорение с использованием графических процессоров (GPU) или специализированных ускорителей, для преодоления этих ограничений и обеспечения эффективной обработки графовых запросов в больших масштабах.
Эффективный обход графов и поиск шаблонов являются ключевым фактором для раскрытия потенциала современных наборов данных. Сложность и объем информации, содержащейся в графах знаний и других связанных структурах, требуют алгоритмов, способных быстро и точно находить взаимосвязи и закономерности. Без таких инструментов анализ данных становится затруднительным, а возможности, связанные с извлечением ценной информации, — ограниченными. Поиск путей, выявление сообществ и обнаружение аномалий — все эти задачи требуют оптимизированных методов обхода графов, позволяющих обрабатывать миллиарды узлов и связей в разумные сроки. Именно поэтому разработка и внедрение инновационных подходов к обходу графов и поиску шаблонов является приоритетной задачей в области анализа данных и искусственного интеллекта, открывающей путь к новым открытиям и улучшениям в различных областях, от биоинформатики до социальных сетей.
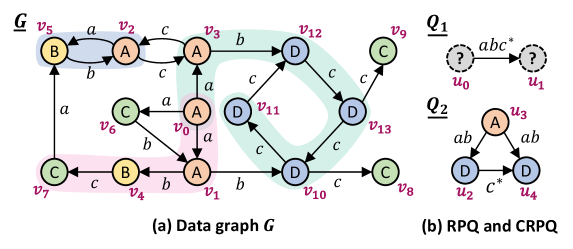
cuRPQ: Аппаратное Ускорение Графовых Запросов
cuRPQ использует массовый параллелизм графических процессоров (GPU) для ускорения выполнения запросов Regular Path Queries (RPQ) и их расширения, Conjunctive RPQ (CRPQ). В отличие от традиционных подходов, выполняемых на центральном процессоре (CPU), cuRPQ переносит вычислительную нагрузку на GPU, что позволяет одновременно обрабатывать множество путей в графе. Это особенно эффективно для сложных запросов, требующих обхода больших объемов данных и поиска соответствий сложным шаблонам, поскольку GPU способны выполнять тысячи операций параллельно, значительно сокращая общее время выполнения запроса. Такой подход позволяет существенно повысить производительность при работе с большими графами и сложными запросами, характерными для задач анализа социальных сетей, биоинформатики и баз знаний.
В основе cuRPQ лежит расширение подхода, основанного на конечных автоматах, для эффективного представления и обхода сложных графовых шаблонов. Вместо традиционного перебора кандидатов, cuRPQ использует автомат для моделирования запроса, где состояния автомата соответствуют промежуточным результатам обхода графа, а переходы — условиям, определяющим допустимые связи между узлами. Такое представление позволяет параллельно исследовать различные пути в графе, значительно сокращая время выполнения запросов, особенно для сложных конъюнктивных запросов (CRPQs), требующих сопоставления нескольких шаблонов одновременно. Автомат кодируется и выполняется на GPU, что обеспечивает массовый параллелизм при обходе графа и сопоставлении шаблонов.
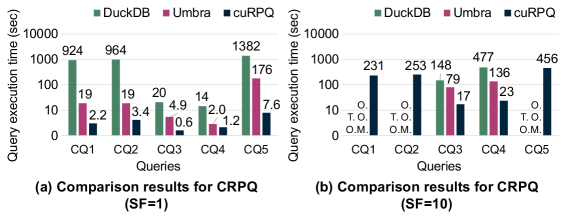
cuRPQ значительно сокращает время выполнения запросов за счет переноса вычислительной нагрузки на GPU, демонстрируя ускорение до 4945x и 269x по сравнению с передовыми алгебраическими и основанными на автоматах методами. Ключевым фактором является разделение процессов исследования графа на GPU и материализации результатов на CPU. Такая архитектура позволяет GPU эффективно параллельно обрабатывать поиск по графу, минимизируя задержки, связанные с передачей данных между CPU и GPU, что особенно важно для больших и сложных графов.
Оптимизированные Методы для Максимальной Производительности
Алгоритм cuRPQ использует стратегию обхода графа под названием `Hop-Limited Level-Wise DFS` (поиск в ширину с ограничением по глубине), направленную на повышение эффективности исследования графа. Вместо полного перебора всех возможных путей, алгоритм ограничивает глубину поиска определенным числом «хопов» (переходов по ребрам) от начальной вершины. Это существенно сокращает пространство поиска и минимизирует избыточные вычисления, особенно в больших графах, где полный обход может быть непрактичным. Ограничение глубины позволяет алгоритму сосредоточиться на наиболее релевантных частях графа, что приводит к более быстрой и эффективной обработке данных.
Техника “Segment Pooling” динамически управляет выделением памяти на GPU, предотвращая фрагментацию и максимизируя производительность. Вместо статического выделения больших блоков памяти, система выделяет память небольшими сегментами, которые распределяются по требованию. При освобождении сегментов, они не возвращаются сразу в общий пул, а остаются доступными для повторного использования в рамках текущих операций, что снижает накладные расходы, связанные с выделением и освобождением памяти. Такой подход позволяет эффективно использовать доступную память GPU, минимизируя потери, вызванные фрагментацией, и повышая общую скорость обработки данных.
Метод пакетной инкрементальной материализации (Batch-Incremental Materialization) позволяет одновременно формировать результаты как на GPU, так и на CPU. Этот подход использует сильные стороны каждого процессора: GPU обеспечивает высокую скорость вычислений при обработке больших объемов данных, а CPU эффективно справляется с задачами управления и последовательной обработкой. Вместо ожидания завершения всех вычислений на одном устройстве, промежуточные результаты формируются параллельно и инкрементально, что снижает общую задержку и повышает пропускную способность. Данный метод особенно эффективен при обработке графов, где частичные результаты могут быть сразу же использованы для дальнейших вычислений, распределенных между GPU и CPU.
Данные структурируются с использованием формата «Помеченная Сетка» (Labeled Grid Format, LGF) для оптимизации паттернов доступа при обработке на GPU. LGF представляет собой способ организации данных, при котором пространство данных разбивается на ячейки сетки, каждой из которых присваивается уникальный идентификатор. Этот подход позволяет GPU эффективно получать доступ к данным, минимизируя количество обращений к глобальной памяти и максимизируя использование кэша. Использование меток (labels) в формате LGF позволяет быстро находить и обрабатывать только те данные, которые необходимы для конкретной операции, что значительно повышает производительность при работе с большими графами и сложными структурами данных.
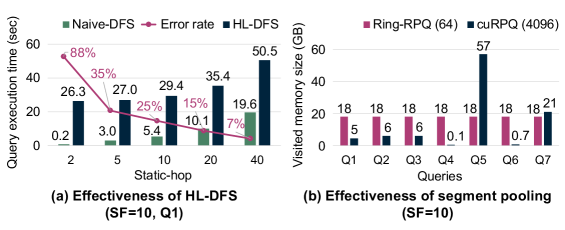
Подтвержденная Масштабируемость и Практическая Ценность
Исследования показали, что cuRPQ демонстрирует высокую производительность при работе с эталонным набором данных LDBC SNB, предназначенным для оценки систем управления графами в социальных сетях. Данный бенчмарк, имитирующий крупномасштабные социальные сети, позволил подтвердить способность cuRPQ эффективно обрабатывать огромные графы, содержащие миллиарды узлов и связей. Результаты тестов демонстрируют, что cuRPQ не только справляется с задачей обработки больших объемов данных, но и обеспечивает стабильную и предсказуемую производительность, что крайне важно для приложений, работающих с динамически меняющимися графами, таким как анализ социальных связей и рекомендательные системы.
Исследование системы cuRPQ показало её высокую применимость к реальным графам знаний, что подтверждено оценкой на наборе данных StackOverflow. Этот популярный ресурс, содержащий вопросы и ответы по программированию, представляет собой сложную сеть взаимосвязанных тем и экспертов. cuRPQ успешно обрабатывает данные StackOverflow, демонстрируя способность эффективно находить связи между вопросами, ответами и пользователями, что делает её перспективным инструментом для систем поиска информации и ответов на вопросы. Способность системы оперировать подобными сложными графами знаний открывает возможности для её использования в широком спектре приложений, включая интеллектуальный поиск, рекомендательные системы и анализ больших данных.
Система cuRPQ демонстрирует высокую эффективность при решении задачи транзитивного замыкания, фундаментальной операции в анализе графов и алгоритмах, используемых в различных областях — от социальных сетей до баз знаний. Транзитивное замыкание позволяет определить достижимость между любыми двумя узлами в графе, что критически важно для таких задач, как рекомендательные системы, анализ связей и обнаружение сообществ. cuRPQ оптимизирует этот процесс, значительно сокращая время вычислений и потребление памяти по сравнению с существующими подходами, что делает возможным анализ графов гораздо большего масштаба и сложности. Эффективная реализация данной операции открывает новые возможности для построения и использования сложных графовых моделей в реальных приложениях.
Исследования показали, что система cuRPQ демонстрирует почти линейную масштабируемость при увеличении количества графических процессоров, что позволяет эффективно обрабатывать растущие объемы данных. В частности, при использовании нескольких GPU, производительность системы увеличивается пропорционально их числу, обеспечивая значительное ускорение вычислений. Более того, cuRPQ значительно оптимизирует использование памяти, снижая ее потребление до 57.2 ГБ по сравнению с предшествующими подходами. Такое существенное уменьшение требований к памяти позволяет обрабатывать более крупные графы и сложные запросы, делая cuRPQ перспективным решением для анализа масштабных графовых структур и систем, работающих с большими объемами данных.
Представленная работа демонстрирует стремление к лаконичности и эффективности в обработке сложных запросов к графовым базам данных. cuRPQ, оптимизируя параллельное исследование и инкрементальную материализацию, подчеркивает важность отсеивания избыточности для достижения высокой производительности. Брайан Керниган однажды заметил: «Простота — высшая степень совершенства». Этот принцип находит отражение в архитектуре cuRPQ, где удаление ненужных шагов и оптимизация процессов позволяют получить элегантное и мощное решение для обработки запросов CRPQ. Акцент на оптимизации и удалении избыточности является ключевым для достижения как производительности, так и понятности системы.
Куда же дальше?
Представленная работа, хоть и демонстрирует значительное ускорение обработки сложных запросов к графам, лишь обнажает глубинную проблему: наше увлечение сложностью. cuRPQ — инструмент, безусловно, эффективный, но его эффективность — лишь временное облегчение симптомов. Истинная ясность заключается не в оптимизации алгоритмов для обработки бесконечных, запутанных запросов, а в проектировании систем, где такие запросы попросту не возникают. Система, требующая детальных инструкций для эффективной работы, уже проиграла.
Дальнейшее развитие, вероятно, пойдет по пути ещё более изощрённой параллелизации и материализации. Однако, более плодотворным представляется поиск альтернативных моделей представления данных, где отношения между сущностями выражены непосредственно, а не вычисляются «на лету». Отказ от избыточности — вот где лежит путь к подлинному совершенству. Простота — не недостаток, а признак глубокого понимания.
В конечном счёте, задача состоит не в том, чтобы быстрее копать яму, а в том, чтобы понять, нужна ли эта яма вообще. Понятность — это вежливость. И к системам обработки данных это относится в первую очередь. Оптимизация ради оптимизации — занятие для тех, кто не видит главного.
Оригинал статьи: https://arxiv.org/pdf/2602.20748.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Квантовая самовнимательность на службе у поиска оптимальных схем
- Квантовый скачок: от лаборатории к рынку
- Виртуальная примерка без границ: EVTAR учится у образов
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
2026-02-25 23:19