Автор: Денис Аветисян
В статье представлен всесторонний анализ алгоритмов поиска ближайших соседей на основе графов, ускоренных с помощью графических процессоров.
Таксономия, эмпирическое исследование и перспективы оптимизации для высокоразмерных данных и масштабируемых систем.
Несмотря на значительные успехи в области приближенного поиска ближайших соседей (ANNS), эффективная масштабируемость алгоритмов на современных графических процессорах (GPU) остается сложной задачей. В настоящей работе, посвященной ‘GPU-Accelerated Algorithms for Graph Vector Search: Taxonomy, Empirical Study, and Research Directions’, представлен всесторонний анализ GPU-ускоренных алгоритмов векторного поиска на основе графов. Полученные результаты демонстрируют, что передача данных между центральным процессором и GPU становится критическим узким местом, ограничивающим производительность в задачах с большими объемами данных, а оптимизация как построения, так и поиска по графовому индексу имеет решающее значение. Какие новые архитектурные решения и алгоритмические подходы позволят преодолеть ограничения, связанные с пропускной способностью памяти и латентностью, и полностью раскрыть потенциал GPU для задач ANNS?
Масштабируемость поиска ближайших соседей: вызов современным алгоритмам
Поиск ближайших соседей для заданной точки является основополагающей задачей в различных областях, включая машинное обучение, рекомендательные системы и поиск информации. Однако, вычислительная сложность этой задачи резко возрастает с увеличением объёма данных. Простой линейный поиск требует сравнения запроса с каждым элементом в наборе данных, что становится непозволительно медленным для масштабных баз данных, содержащих миллионы или даже миллиарды элементов. Эта проблема усугубляется при работе с многомерными данными, где каждое измерение увеличивает пространство поиска и, соответственно, время вычислений. Таким образом, эффективное решение задачи поиска ближайших соседей в масштабе больших данных представляет собой значительный вызов для современной информатики и требует разработки специализированных алгоритмов и структур данных.
Традиционные методы поиска ближайших соседей сталкиваются с серьезными трудностями при работе с данными высокой размерности и большими объемами. Эта проблема, известная как “проклятие размерности”, возникает из-за того, что по мере увеличения числа признаков, расстояние между точками данных стремится к одному и тому же значению, что делает невозможным эффективное выделение действительно ближайших соседей. В результате, время поиска растет экспоненциально с увеличением размерности пространства, а вычислительные затраты становятся непомерно высокими для практического применения в современных задачах, таких как поиск изображений, рекомендательные системы или анализ геномных данных. Вместо полного перебора всех точек, что становится невозможным, требуются альтернативные подходы, способные находить приблизительно ближайших соседей за приемлемое время.
В связи с экспоненциальным ростом объемов данных и увеличением их размерности, задача точного поиска ближайших соседей становится вычислительно невыполнимой. Для решения этой проблемы разрабатываются методы приближенного поиска ближайших соседей (ANNS), которые намеренно жертвуют абсолютной точностью ради значительного ускорения процесса. Эти методы, вместо поиска абсолютно всех ближайших точек, находят лишь достаточно близкие кандидаты, что позволяет существенно сократить время отклика, особенно в задачах, где небольшая погрешность допустима. Принципы работы ANNS-алгоритмов основаны на построении специальных структур данных, таких как деревья, графы или хэш-таблицы, которые позволяют эффективно отсеивать заведомо далекие точки и фокусироваться на наиболее перспективных кандидатах, обеспечивая компромисс между скоростью и точностью.
Ускорение ANNS с помощью GPU: новый горизонт производительности
Графические процессоры (GPU) обеспечивают значительное ускорение при выполнении операций поиска ближайших соседей (ANNS) благодаря своей архитектуре, ориентированной на массовый параллелизм. В отличие от центральных процессоров (CPU), которые оптимизированы для последовательного выполнения задач, GPU содержат тысячи ядер, способных одновременно выполнять множество вычислений. Поскольку вычисление расстояний между векторами является основной операцией в ANNS, возможность параллельного выполнения этих вычислений на GPU позволяет существенно сократить время поиска. Это достигается за счет одновременной обработки нескольких пар векторов, что особенно эффективно при работе с большими объемами данных и высокой размерностью векторов. В результате, GPU способны обрабатывать поисковые запросы значительно быстрее, чем CPU, делая их незаменимыми для приложений, требующих высокой производительности и масштабируемости.
Ускорение на графических процессорах (GPU) значительно сокращает время поиска ближайших соседей, позволяя реализовать приложения, работающие в режиме реального времени, и обрабатывать наборы данных, которые ранее были недоступны для методов, основанных на центральном процессоре (CPU). В частности, для задач, требующих быстрого ответа на запросы, таких как рекомендательные системы или поиск изображений, GPU-ускорение обеспечивает критическое повышение производительности. Это позволяет масштабировать приложения поиска ближайших соседей до миллиардов векторов, что невозможно при использовании только CPU, и открывает возможности для анализа и обработки больших объемов данных в интерактивном режиме.
Эффективное использование GPU для ускорения поиска ближайших соседей (ANNS) требует тщательного анализа накладных расходов на передачу данных и шаблонов доступа к памяти. В частности, при работе с крупномасштабными наборами данных, такими как DEEP100M, задержки, связанные с передачей данных между CPU и GPU, могут превышать 97%, что существенно ограничивает общую производительность. Оптимизация этих процессов включает в себя минимизацию объемов передаваемых данных, использование асинхронных операций передачи, а также проектирование алгоритмов таким образом, чтобы максимально эффективно использовать локальную GPU-память и избегать частых обращений к основной памяти.

Графовые алгоритмы ANNS: эффективность и масштабируемость структуры данных
Методы, основанные на графах, строят графы близости для представления взаимосвязей между точками данных, что позволяет эффективно осуществлять поиск. В этих графах каждая точка данных представлена узлом, а ребра соединяют узлы, представляющие близкие точки. Близость определяется метрикой расстояния, такой как евклидово расстояние или косинусное сходство. В процессе поиска алгоритм начинает с начальной точки и обходит граф, посещая ближайшие узлы, пока не будут найдены наиболее релевантные результаты. Такая структура позволяет избежать полного перебора всех точек данных, значительно повышая скорость поиска по сравнению с линейными алгоритмами. Эффективность метода напрямую зависит от стратегии построения графа и выбора метрики расстояния.
Алгоритмы, такие как GGNN, CAGRA и GANNS, используют архитектуру GPU для распараллеливания операций обхода графа и вычисления расстояний. Это достигается за счет эффективного использования тысяч ядер GPU для одновременной обработки множества узлов и ребер графа, что значительно ускоряет процесс поиска ближайших соседей. В частности, распараллеливание вычисления расстояний между векторами данных и одновременный обход графа позволяют существенно сократить время отклика по сравнению с CPU-ориентированными подходами. Такой подход особенно эффективен при работе с высокоразмерными данными и большими объемами данных, где вычисления становятся ресурсоемкими.
Различные стратегии построения графов, такие как K-ближайших соседей (K-NN), диаграммы Вороного (Delaunay) и графы относительных окрестностей (Relative Neighborhood Graph), оказывают существенное влияние на точность и эффективность поиска в алгоритмах приближенного поиска ближайших соседей (ANNS). K-NN графы строятся на основе соединения каждой точки с её K ближайшими соседями, что обеспечивает высокую скорость поиска, но может привести к потере точности при малом значении K или к избыточной сложности при большом. Диаграммы Вороного, напротив, создают более глобальную структуру, но требуют более сложных вычислений для определения границ ячеек. Графы относительных окрестностей формируются на основе принципа, что две точки соединены, если они являются ближайшими соседями друг для друга, что обеспечивает баланс между точностью и вычислительной сложностью. Выбор стратегии зависит от характеристик данных и требуемого компромисса между скоростью и точностью поиска.
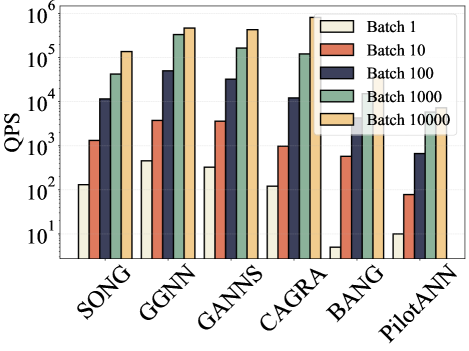
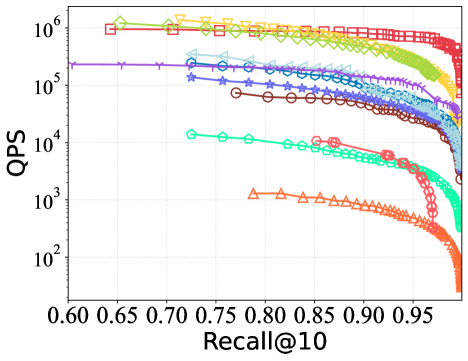
Оптимизация длины пути запроса является критически важным фактором для достижения максимальной производительности в алгоритмах ANNS, основанных на графах. Алгоритм CAGRA демонстрирует наиболее высокую и стабильную скорость обработки запросов (QPS) по сравнению с другими подходами. В ходе тестирования CAGRA показал превосходную пропускную способность при работе с разнородными наборами данных, отличающимися по масштабу и размерности, что указывает на его эффективность и надежность в различных сценариях применения.
Архитектурные оптимизации ANNS на GPU: максимизация параллелизма и минимизация задержек
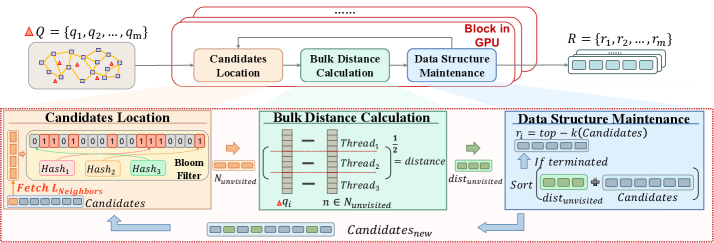
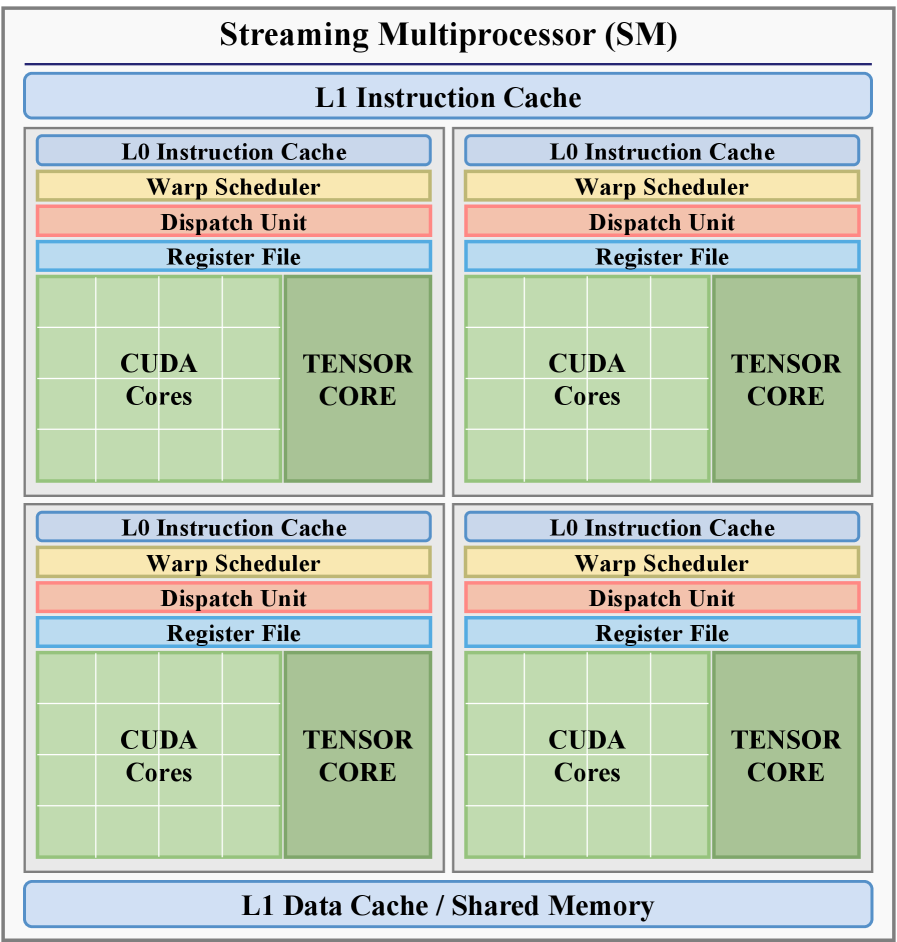
Эффективное использование графического процессора (GPU) напрямую зависит от глубокого понимания его иерархии памяти, ключевым элементом которой является разделяемая память (Shared Memory) внутри каждого потокового мультипроцессора. В отличие от глобальной памяти GPU, доступ к разделяемой памяти значительно быстрее, поскольку она находится ближе к вычислительным ядрам. Разделяемая память позволяет потокам внутри одного мультипроцессора обмениваться данными без обращения к более медленной глобальной памяти, что критически важно для производительности алгоритмов приближенного поиска ближайших соседей (ANNS). Оптимизированные алгоритмы активно используют разделяемую память для хранения промежуточных результатов вычислений и организации эффективного доступа к данным, минимизируя задержки и максимизируя пропускную способность. Правильное распределение и использование разделяемой памяти — это фундаментальный аспект разработки высокопроизводительных GPU-ускоренных приложений.
Алгоритмы приближенного поиска ближайших соседей (ANNS) на графических процессорах (GPU) активно используют возможности общей памяти (shared memory) для повышения производительности. Стратегическое использование этой памяти позволяет существенно снизить задержки доступа к данным, поскольку она обеспечивает значительно более быстрый доступ по сравнению с глобальной памятью GPU. Разработчики стремятся максимизировать локальность данных, перемещая часто используемые фрагменты информации в общую память каждого потокового мультипроцессора. Это достигается путем разбиения данных на небольшие блоки и загрузки их в общую память перед выполнением вычислений, что минимизирует необходимость обращения к более медленной глобальной памяти и, как следствие, ускоряет процесс поиска. Эффективное управление локальностью данных и оптимизация доступа к памяти являются ключевыми факторами в создании высокопроизводительных алгоритмов ANNS для GPU.
Гибридные подходы, такие как BANG и PilotANN, направлены на снижение накладных расходов, связанных с передачей данных, путем хранения большей части информации в оперативной памяти центрального процессора (CPU). Вместо полной загрузки данных на графический процессор (GPU), эти алгоритмы используют GPU только для выполнения наиболее ресурсоемких вычислений, например, поиска ближайших соседей. Такой подход позволяет значительно уменьшить задержки, вызванные обменом данными между CPU и GPU, особенно при работе с большими объемами данных. Эффективно используя возможности обоих процессоров, гибридные методы обеспечивают более высокую производительность и масштабируемость в задачах приближенного поиска ближайших соседей (ANNS), что делает их перспективными для широкого спектра приложений, включая поиск изображений, рекомендательные системы и обработку естественного языка.
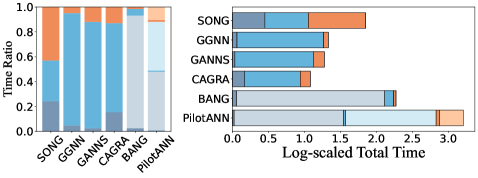
Ускоренные алгоритмы, реализованные на графических процессорах (GPU), такие как CAGRA и GGNN, демонстрируют существенное сокращение времени построения индексов по сравнению с традиционными CPU-методами, что особенно важно при работе с крупномасштабными наборами данных, где часто возникают ошибки нехватки памяти (OOM). Анализ производительности показывает, что до 80% времени выполнения оптимизированных алгоритмов занимает этап вычисления расстояний между векторами — так называемый “bulk distance calculation”. Это указывает на то, что дальнейшая оптимизация именно этого этапа может принести наибольший прирост скорости и эффективности при поиске ближайших соседей в больших пространствах признаков.
Перспективы развития ANNS: инновационные стратегии и аппаратные решения
Дальнейшие исследования направлены на разработку инновационных стратегий построения графов, которые обеспечивают оптимальный баланс между точностью, скоростью обработки и объемом используемой памяти. Существующие методы часто сталкиваются с компромиссами: увеличение точности может приводить к значительному росту вычислительных затрат и потребности в памяти, что ограничивает их применимость к крупномасштабным данным. Перспективные подходы включают в себя адаптивные алгоритмы, способные динамически выбирать оптимальную структуру графа в зависимости от характеристик данных и типа запроса, а также использование методов сжатия и квантования для уменьшения объема памяти, необходимого для хранения графа, без существенной потери точности. Оптимизация процесса построения графа является ключевым фактором для расширения возможностей анализа данных и решения сложных задач в различных областях, включая социальные сети, биологию и машинное обучение.
Для успешного применения графовых алгоритмов в реальных сценариях, особенно при работе с динамически меняющимися данными, необходима разработка адаптивных алгоритмов. Традиционные алгоритмы, оптимизированные для статических графов, часто демонстрируют снижение производительности при изменении структуры графа или характера запросов. Исследования направлены на создание алгоритмов, способных автоматически перестраивать внутренние структуры данных и стратегии обработки запросов в ответ на изменения в распределении данных и паттернах запросов. Это включает в себя методы онлайн-обучения, динамического перераспределения ресурсов и адаптивной выборки, позволяющие алгоритмам поддерживать высокую эффективность даже в условиях нестабильной среды. Способность к адаптации является ключевым фактором для обеспечения масштабируемости и надежности графовых систем в практических приложениях, таких как социальные сети, рекомендательные системы и анализ сетевых данных.
Исследования в области специализированных аппаратных ускорителей для обработки графов открывают перспективы значительного повышения производительности. Традиционные центральные и графические процессоры, хоть и универсальны, не всегда оптимальны для операций, характерных для графовых алгоритмов, таких как обход и поиск. Разработка специализированных устройств, ориентированных на выполнение операций над графами, например, матричных умножений и операций с разреженными матрицами, позволяет существенно снизить задержки и энергопотребление. Эти ускорители, используя параллельную архитектуру и оптимизированные схемы памяти, способны обрабатывать огромные графы, которые ранее были недоступны для анализа в реальном времени. Перспективными направлениями являются разработка ASIC (Application-Specific Integrated Circuit) и FPGA (Field-Programmable Gate Array) решений, адаптированных под конкретные типы графов и алгоритмов, что позволит добиться максимальной эффективности и раскрыть потенциал графовых данных.
Исследования показывают, что комбинирование центральных и графических процессоров (CPU и GPU) представляет собой перспективное направление в развитии технологий обработки графов. CPU эффективно справляются с задачами, требующими сложной логики и последовательного выполнения, в то время как GPU превосходно подходят для параллельных вычислений, необходимых при обработке больших графов. Гибридные подходы позволяют распределить нагрузку между этими архитектурами, используя сильные стороны каждой из них. Например, CPU может отвечать за управление графом и планирование задач, а GPU — за выполнение ресурсоемких операций, таких как поиск пути или анализ связей. Такая стратегия позволяет существенно повысить скорость обработки данных и снизить потребление энергии, открывая возможности для решения более сложных задач в различных областях, включая анализ социальных сетей, биоинформатику и машинное обучение.
Исследование, представленное в данной работе, подчеркивает важность оптимизации алгоритмов поиска ближайших соседей в высокоразмерных пространствах, особенно при использовании GPU-ускорения. Авторы убедительно демонстрируют, что узким местом производительности является не вычислительная мощность, а скорость передачи данных. Это подтверждает фундаментальную истину, которую сформулировал Алан Тьюринг: «Иногда люди, которые кажутся сумасшедшими, просто видят вещи, которые другие не могут». В контексте данного исследования, это означает, что для достижения реального прогресса необходимо взглянуть за рамки традиционных подходов к оптимизации вычислений и сосредоточиться на минимизации накладных расходов, связанных с передачей данных, что, в свою очередь, требует инновационных решений в области построения графов и организации доступа к данным.
Что Дальше?
Без точного определения задачи любое решение — шум. Настоящая работа лишь обнажила глубину проблемы: ускорение поиска ближайших соседей на графах, реализованное на GPU, сталкивается не с вычислительными ограничениями, а с банальным ограничением пропускной способности памяти. Ирония в том, что все усилия по оптимизации алгоритмов графового поиска могут быть сведены на нет, если данные не могут быть достаточно быстро перемещены. Необходимо переосмыслить саму парадигму: вместо того чтобы гнаться за всё более сложными алгоритмами, следует сосредоточиться на минимизации объема передаваемых данных.
Истинная элегантность кода проявляется в его математической чистоте. Будущие исследования должны быть направлены на разработку методов, позволяющих эффективно представлять графы в памяти GPU, возможно, за счет некоторой потери точности. Очевидно, что дальнейшее увеличение вычислительной мощности GPU не решит проблему, если узким местом останется передача данных. Необходимо стремиться к алгоритмической доказуемости, а не просто к эмпирическим улучшениям производительности.
Поиск эффективных методов построения графов, минимизирующих объем передаваемых данных, представляется ключевой задачей. Алгоритм должен быть доказуем, а не просто «работать на тестах». И лишь тогда, когда проблема передачи данных будет решена, можно будет говорить о действительно масштабируемых решениях для поиска ближайших соседей в высокоразмерных данных.
Оригинал статьи: https://arxiv.org/pdf/2602.16719.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Временная запутанность: от хаоса к порядку
- Улучшение точности квантовых сенсоров: новый подход к подавлению шумов
- Квантовое программирование: Карта развивающегося мира
- Предел возможностей: где большие языковые модели теряют разум?
- ЭКГ-анализ будущего: От данных к цифровым биомаркерам
- Резонансы в тандеме: Управление светом в микрорезонаторах
- Сердце музыки: открытые модели для создания композиций
- Квантовые кольца: новые горизонты спиновых токов
- Искусственный разум и квантовые данные: новый подход к синтезу табличных данных
- Моделирование спектроскопии электронного пучка: новый подход
2026-02-20 23:55