Автор: Денис Аветисян
Исследователи предлагают метод использования больших языковых моделей для поиска оптимальных путей химического синтеза на основе графов знаний о реакциях.
Применение больших языковых моделей и графов знаний для эффективного поиска химических реакций и планирования синтеза.
Несмотря на впечатляющие возможности больших языковых моделей (LLM), их применение в планировании химического синтеза часто сталкивается с проблемой генерации недостоверных или устаревших предложений. В работе ‘Grounding Large Language Models in Reaction Knowledge Graphs for Synthesis Retrieval’ исследуется подход, основанный на использовании графов знаний о реакциях для повышения надежности LLM, путем перевода запросов на естественном языке в запросы на языке Cypher. Показано, что одношаговое обучение с использованием релевантных примеров и проверка результатов с помощью самокорректирующего цикла значительно повышают точность поиска химических реакций. Каковы перспективы создания полностью автоматизированных систем планирования синтеза, использующих LLM, интегрированные с графами знаний и механизмами самоконтроля?
Разрушая Барьеры Химического Синтеза: От Интуиции к Автоматизации
Традиционные методы планирования химических синтезов зачастую представляют собой трудоемкий и продолжительный процесс, требующий глубоких знаний и опыта от специалиста. Разработка оптимального пути получения целевого соединения может занять месяцы или даже годы, поскольку химик должен учитывать множество факторов, таких как доступность реагентов, совместимость функциональных групп и потенциальные побочные реакции. Этот процесс сильно зависит от интуиции и экспертных оценок, что делает его подверженным ошибкам и ограничивает возможности масштабирования. Отсутствие систематизированного подхода и эффективных инструментов для анализа огромного химического пространства существенно замедляет темпы открытия новых лекарств и материалов, подчеркивая необходимость разработки автоматизированных систем для планирования синтеза.
Эффективное исследование обширного химического пространства требует системы, способной кодировать и анализировать сложные взаимосвязи между реакциями. Современные подходы к планированию синтеза часто сталкиваются с экспоненциальным ростом возможных путей, что делает поиск оптимального маршрута чрезвычайно сложной задачей. Для преодоления этой трудности разрабатываются системы, представляющие химические реакции и реагенты в виде графов и сетей, что позволяет алгоритмам машинного обучения выявлять закономерности и предсказывать результаты реакций. Такой подход позволяет не только автоматизировать процесс планирования синтеза, но и открывать новые, ранее неизвестные реакции, значительно расширяя возможности химической науки и технологий. Использование баз данных, содержащих информацию о миллионах химических соединений и реакций, в сочетании с алгоритмами искусственного интеллекта, позволяет существенно сократить время и ресурсы, необходимые для разработки новых лекарств, материалов и других важных продуктов.
Реакционный Граф Знаний: Компас в Мире Химии
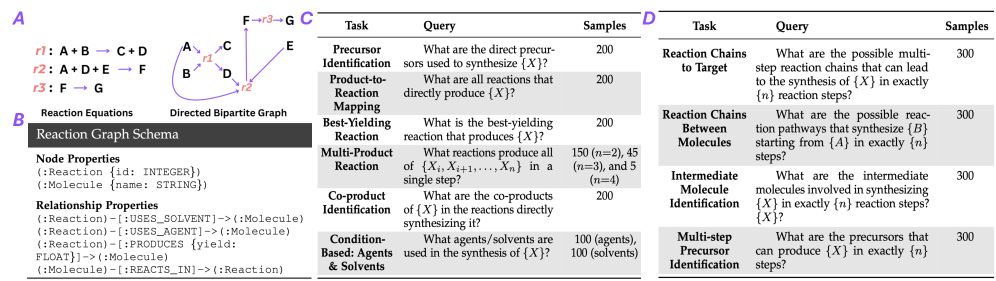
Граф знаний о реакциях представляет собой структурированное представление химических реакций и молекул, в котором взаимосвязи устанавливаются между реагентами, продуктами и катализаторами. Данная структура позволяет явно отобразить химические превращения, идентифицируя исходные вещества, образующиеся соединения и вещества, влияющие на скорость и селективность реакции. Каждый узел графа может представлять собой молекулу, а ребра — химическую реакцию, связывающую эти молекулы. Включение агентов, таких как катализаторы и растворители, в эту структуру обеспечивает более полное описание реакционного процесса и позволяет проводить анализ реакционных путей на основе имеющихся данных.
Структура графа химических реакций основана на бипартитном графе, где один набор узлов представляет молекулы (реагенты, продукты и катализаторы), а другой — химические реакции, преобразующие эти молекулы. Такая структура позволяет эффективно моделировать связи между реагентами и продуктами, что критически важно для ретросинтетического анализа — определения предшественников для получения целевой молекулы — и предсказания возможных продуктов реакции на основе известных реагентов и условий. Бипартитность графа упрощает поиск реакций, подходящих для конкретной молекулы-реагента, и наоборот, а также позволяет оценивать вероятные пути синтеза, учитывая множество возможных реакций и промежуточных соединений.
Графовый подход обеспечивает эффективный поиск одношаговых реакций и более сложные многошаговые пути синтеза. Одношаговый поиск (Single-Step Retrieval) позволяет быстро идентифицировать реакции, преобразующие заданный реагент в целевой продукт. Многошаговый поиск (Multi-Step Retrieval) использует граф для определения последовательности реакций, необходимых для синтеза сложной молекулы из доступных исходных материалов. Алгоритмы обхода графа оптимизированы для минимизации вычислительных затрат и предоставления наиболее вероятных и эффективных путей синтеза, учитывая связи между молекулами и реакциями, представленными в графе.
От Естественного Языка к Запросам: Сила Text2Cypher
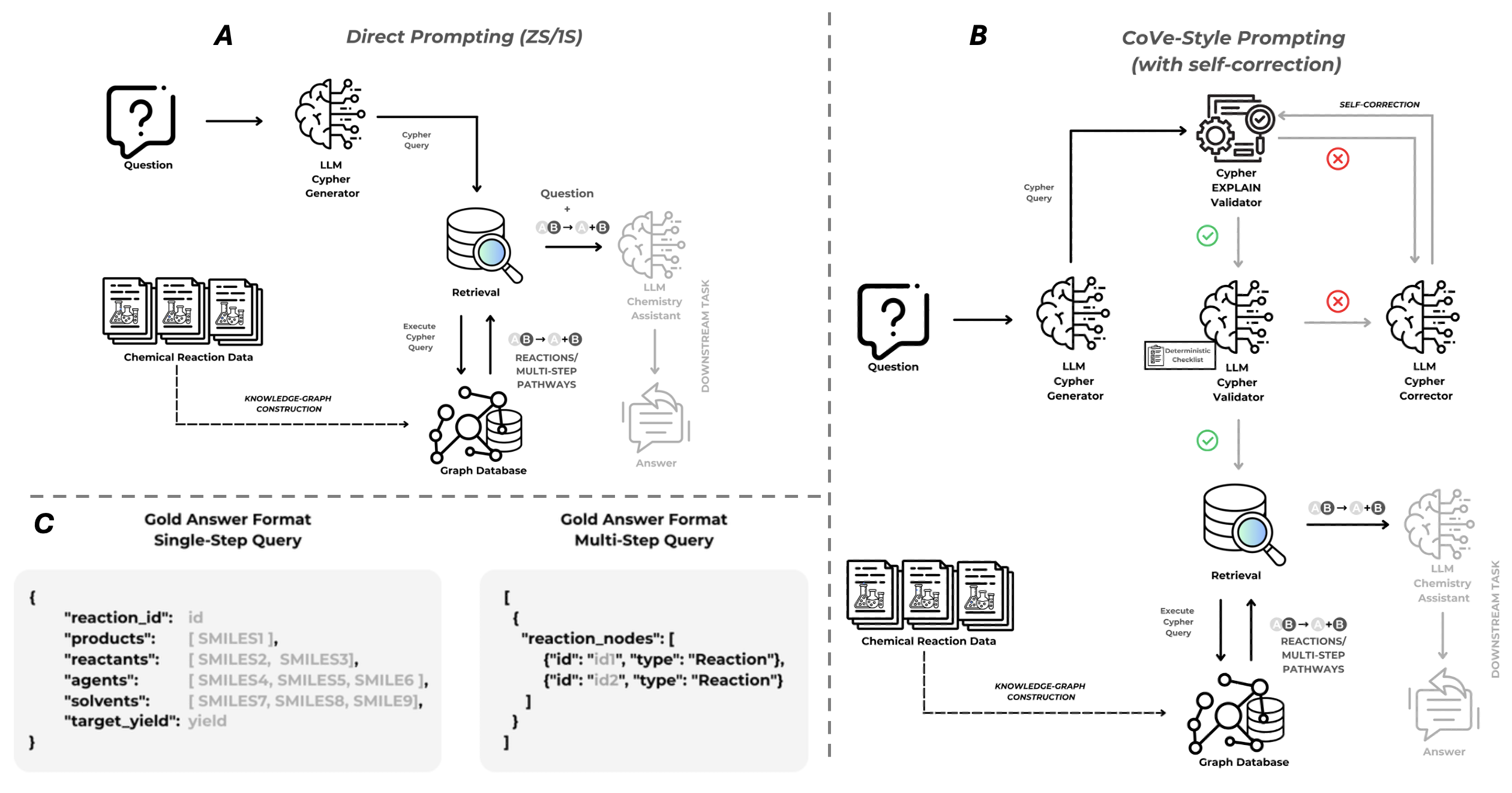
Метод Text2Cypher использует возможности больших языковых моделей (LLM) для преобразования инструкций на естественном языке в запросы на языке Cypher, предназначенные для работы с графом знаний о реакциях. Этот процесс позволяет пользователям взаимодействовать с графом, используя понятные формулировки, вместо необходимости знания синтаксиса Cypher. LLM анализирует входной текст, определяет намерения пользователя и генерирует соответствующий запрос Cypher, который затем может быть выполнен для извлечения информации или выполнения других операций над графом знаний.
Эффективное проектирование запросов (prompt engineering) играет ключевую роль в получении корректных и исполняемых Cypher-запросов от больших языковых моделей (LLM). Качество и структура исходного запроса, заданного LLM, напрямую влияет на точность сгенерированного кода. В частности, четкое определение требуемого результата, указание формата ответа (например, конкретные узлы и связи, которые необходимо получить) и предоставление контекста для запроса значительно повышают вероятность успешной генерации. Недостаточно четко сформулированные или неоднозначные запросы часто приводят к синтаксическим ошибкам в Cypher или возврату нерелевантных данных, требующих последующей ручной корректировки.
Процесс “Цепочки верификации” (Chain-of-Verification) представляет собой многоэтапную систему, предназначенную для повышения надежности генерируемых Cypher-запросов. Он включает в себя автоматическую проверку синтаксической корректности и возможности выполнения сгенерированного запроса на графе знаний Reaction Knowledge Graph. В случае обнаружения ошибок или неэффективности, система автоматически предлагает альтернативные варианты запроса, направленные на исправление синтаксических неточностей или оптимизацию логики запроса. Данный процесс позволяет минимизировать количество невыполнимых запросов и гарантировать получение корректных результатов, повышая общую устойчивость системы преобразования естественного языка в запросы к графу знаний.
Оценка Качества Запросов: Метрики и Валидация
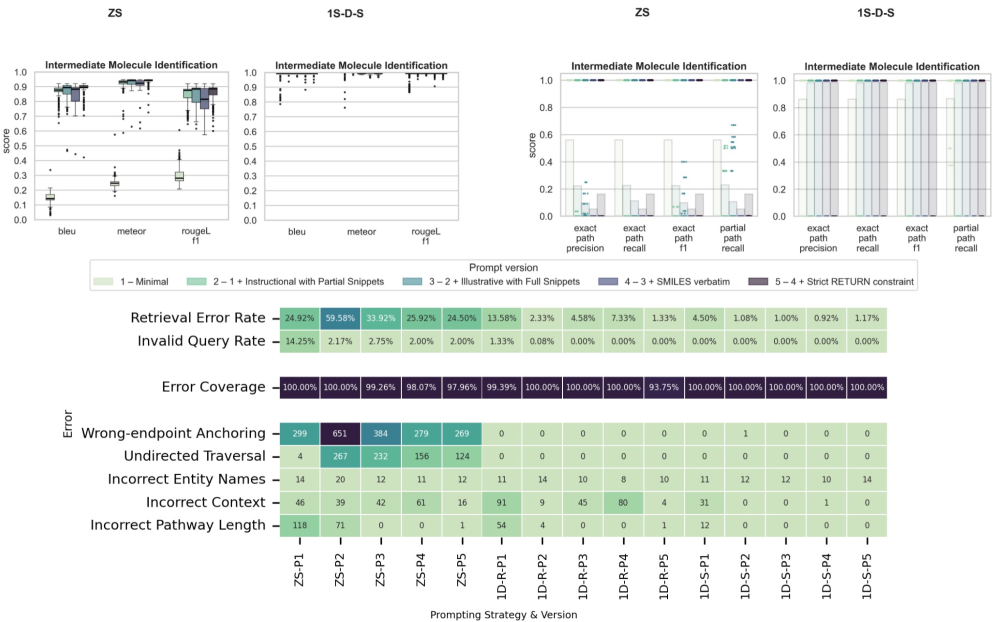
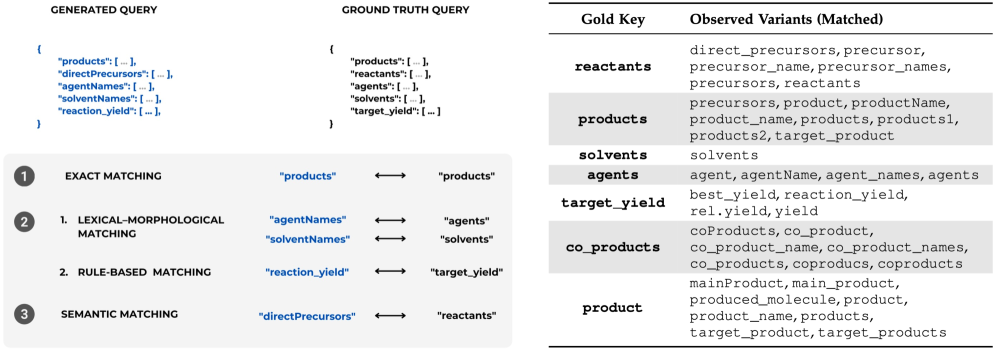
Для оценки качества генерируемых запросов на языке Cypher, используемых в задачах планирования химического синтеза, применяются стандартные метрики, такие как BLEU, ROUGE-L и METEOR. Эти метрики позволяют количественно оценить степень соответствия между сгенерированным запросом и эталонным, измеряя схожесть в лексическом составе и структуре. Основываясь на принципе n-грамм, BLEU оценивает точность, в то время как ROUGE-L фокусируется на самой длинной общей подпоследовательности, обеспечивая оценку полноты. METEOR, в свою очередь, учитывает синонимы и морфологические варианты, что делает оценку более гибкой и приближенной к человеческому восприятию корректности запроса. Использование этих метрик позволяет автоматизировать процесс оценки и сравнения различных подходов к генерации запросов, способствуя повышению эффективности и надежности систем ретросинтетического анализа.
Для оценки качества генерируемых запросов используются стандартные метрики, такие как BLEU, ROUGE-L и METEOR. Эти показатели позволяют количественно оценить как точность соответствия с эталонными запросами, так и беглость, или естественность, сформированного синтаксиса. Высокие значения метрик свидетельствуют о том, что система способна генерировать запросы, близкие по смыслу и структуре к тем, которые были бы составлены экспертом, что критически важно для обеспечения корректности и эффективности планирования химического синтеза и предсказания ретросинтетических путей. По сути, эти метрики выступают в роли объективных критериев, позволяющих измерить прогресс в разработке систем автоматической генерации запросов и оценить их пригодность для практического применения.
Высококачественная генерация запросов, подтвержденная соответствующими метриками, оказывает непосредственное влияние на эффективность и надежность планирования химического синтеза и ретросинтетического предсказания. Переход от запросов, задаваемых без предварительных примеров (zero-shot), к запросам с одним примером (one-shot) значительно снижает количество ошибок, связанных с привязкой к конечным точкам и направлением обхода графа. В свою очередь, использование цикла CoVe (Confirmation, Validation, and Enhancement) позволило добиться приблизительно 80%-ного снижения ошибок при поиске информации в условиях zero-shot подхода, что свидетельствует о значительном повышении точности и скорости определения оптимальных путей синтеза.
Несмотря на общую эффективность предложенного цикла CoVe в улучшении качества генерируемых запросов, компонент валидации на данный момент существенно ограничивает его производительность. Исследования показывают, что в ходе тестирования данный компонент обнаруживает лишь незначительную часть — от 5 до 14% — специфических ошибок, возникающих в процессе решения задач. Это означает, что подавляющее большинство (от 86 до 95%) ошибок, связанных с некорректностью или неоптимальностью генерируемых запросов, остаются незамеченными системой валидации, что потенциально снижает надежность и точность планирования химического синтеза и предсказания ретросинтеза. Необходима дальнейшая работа над совершенствованием алгоритмов валидации для повышения общей эффективности цикла CoVe.

Исследование демонстрирует, что эффективное использование больших языковых моделей требует не просто обработки информации, но и её структурирования в понятные системы. Авторы предлагают способ трансляции запросов на естественном языке в запросы Cypher для извлечения химических реакций из графа знаний. Этот подход подчеркивает необходимость «заземления» моделей в конкретных данных и проверке их работы на реальных задачах. Как однажды заметил Роберт Тарьян: «Любая достаточно сложная система неизбежно содержит ошибки, и их обнаружение — это ключ к пониманию». Действительно, успешное применение RAG (Retrieval Augmented Generation) в данной работе подтверждает, что даже самые передовые модели нуждаются в надёжной базе знаний и точной оценке результатов, а каждый «патч» — это признание несовершенства системы.
Куда же дальше?
Представленная работа, по сути, демонстрирует, что даже самые сложные языковые модели нуждаются в надежном фундаменте — в данном случае, в структурированном графе знаний о химических реакциях. Однако, подобно алхимику, стремящемуся к философскому камню, исследователи сталкиваются с тем, что само построение этого фундамента — задача нетривиальная. Перевод естественного языка в запросы Cypher — лишь первый шаг; истинный вызов заключается в обеспечении полноты и непротиворечивости самого графа. Неточность данных — это не просто ошибка, а потенциальный сбой в системе, маскирующийся под успех.
Очевидно, что дальнейшее развитие требует не только совершенствования алгоритмов перевода, но и новых подходов к автоматическому заполнению и верификации графов знаний. Можно предположить, что модели, способные к самообучению на неполных или противоречивых данных, окажутся более устойчивыми и адаптивными. Иными словами, система должна уметь находить ошибки в себе самой — признавать собственные грехи, если угодно.
Наконец, стоит задуматься о границах применимости данного подхода. Химические реакции — лишь один пример предметной области. Сможет ли подобная архитектура быть успешно применена к более сложным и абстрактным задачам, где знание менее формализовано и более подвержено интерпретациям? Этот вопрос, вероятно, станет ключевым в определении будущего направления исследований.
Оригинал статьи: https://arxiv.org/pdf/2601.16038.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Метаболический профиль СДВГ: новый взгляд на диагностику
- Квантовая криптография: от теории к практике
- Лунный гелий-3: Охлаждение квантового будущего
- Робот, который видит, понимает и действует: новая эра общего назначения
- Квантовые сети для моделирования молекул: новый подход
2026-01-23 22:24