Автор: Денис Аветисян
В статье представлена архитектура IA-HVAE, сочетающая в себе многоуровневый вывод и оптимизацию градиента декодера для более быстрой и эффективной реконструкции данных.
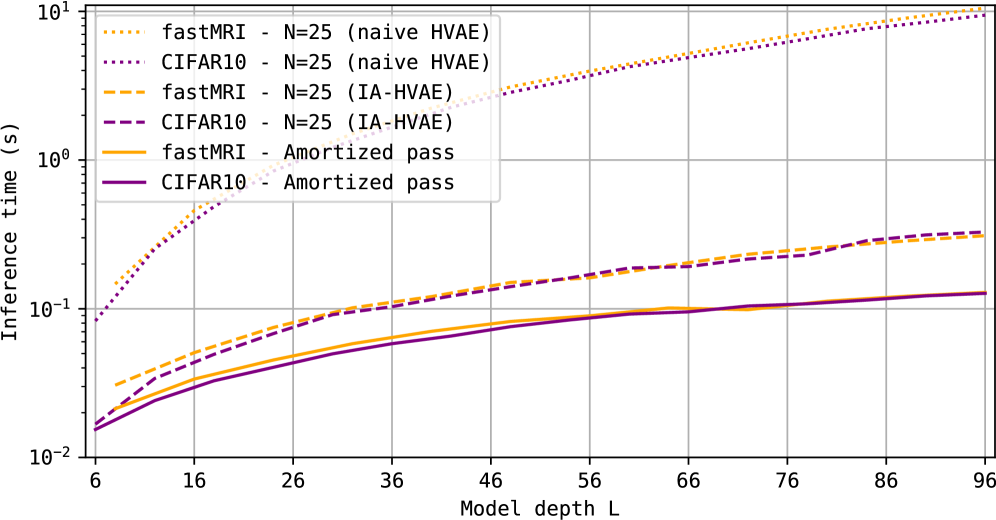
Исследование посвящено итеративному вариационному автоэнкодеру с амортизированным выводом и оптимизацией в частотной области для решения обратных задач.
Построение эффективных и масштабируемых вероятностных моделей часто сталкивается с компромиссом между точностью и скоростью инференса. В данной работе представлена архитектура Iterative Amortized Hierarchical VAE (IA-HVAE), расширяющая возможности вариационных автоэнкодеров за счет гибридной схемы, сочетающей начальную амортизированную аппроксимацию с итеративным уточнением на основе градиентов декодера. Предложенный подход позволяет достичь 35-кратного ускорения инференса по сравнению с традиционными иерархическими вариационными автоэнкодерами, демонстрируя превосходство в точности и скорости, особенно в задачах обратных проблем, таких как удаление размытия и шума. Возможно ли дальнейшее повышение эффективности IA-HVAE за счет адаптации архитектуры декодера и оптимизации стратегии итеративного уточнения?
Обратные Задачи: Поиск Истины в Неопределенности
Многие задачи, с которыми сталкивается современная наука и техника, относятся к классу обратных задач — задач, где необходимо восстановить исходный сигнал или явление по неполным или зашумленным данным. Например, в медицинской томографии изображение внутренних органов восстанавливается по данным рентгеновского излучения, в сейсмологии — структура недр Земли по отраженным волнам, а в астрономии — параметры звезд по наблюдаемому свету. Эти задачи отличаются от прямых, где по заданным параметрам вычисляется результат. В обратных задачах существует бесконечное множество возможных решений, удовлетворяющих имеющимся данным, что делает процесс восстановления сигнала сложным и требующим применения специальных методов и алгоритмов для отбора наиболее вероятного и физически обоснованного результата.
Традиционные методы решения обратных задач, широко распространенных в различных областях науки и техники, часто сталкиваются с серьезными трудностями. Основная проблема заключается в присущей этим задачам неоднозначности: одному набору наблюдений может соответствовать множество возможных решений, что делает выделение истинного сигнала крайне сложным. Более того, поиск оптимального решения в высокоразмерном пространстве параметров требует значительных вычислительных ресурсов, а сложность алгоритмов растет экспоненциально с увеличением размерности задачи. Это приводит к тому, что даже при наличии мощных вычислительных систем, получение точного и надежного результата становится затруднительным, а время обработки данных — неприемлемо долгим для многих практических приложений. Таким образом, разработка эффективных и экономичных методов, способных преодолеть эти ограничения, является ключевой задачей современной науки.
Эффективное решение обратных задач, возникающих при реконструкции сигналов из неполных или зашумленных данных, требует методов, способных ориентироваться в сложных многомерных пространствах решений. Такие подходы должны не только находить возможные решения, но и точно оценивать скрытые параметры исходного сигнала, игнорируя шум и неоднозначности. В связи с этим, разработка алгоритмов, учитывающих априорную информацию о структуре сигнала и использующих регуляризацию для стабилизации решения, является ключевой задачей. Успех в этой области напрямую связан с возможностью эффективно исследовать огромные пространства решений и находить наиболее вероятные и физически обоснованные оценки исходного сигнала, что особенно важно в таких областях, как обработка изображений, геофизика и медицинская диагностика.
Вариационные Автоэнкодеры: Первый Шаг к Пониманию Скрытого
Вариационные автоэнкодеры (VAE) представляют собой архитектуру нейронных сетей, предназначенную для обучения вероятностным представлениям скрытого пространства данных. В отличие от традиционных автоэнкодеров, VAE не просто кодируют входные данные в вектор фиксированной длины, а отображают их в параметры вероятностного распределения — обычно нормального N(\mu, \sigma^2). Это позволяет генерировать новые данные, отбирая значения из этого распределения, и выполнять вывод, оценивая вероятность принадлежности данных к определенному классу или параметру. Использование вероятностного подхода обеспечивает более гибкое и устойчивое представление данных, что критически важно для задач генерации и анализа.
В вариационных автоэнкодерах (VAE) амортизированный вывод представляет собой ключевой механизм для приближенного вычисления апостериорного распределения p(z|x), где z — скрытая переменная, а x — входные данные. Вместо вычисления p(z|x) напрямую для каждого нового входного вектора x, амортизированный вывод использует параметризованную функцию (обычно нейронную сеть), которая отображает x в параметры распределения (например, среднее и дисперсию). Это позволяет эффективно аппроксимировать апостериорное распределение для произвольного x без необходимости сложных вычислений, что существенно ускоряет процесс обучения и генерации данных. По сути, амортизированный вывод заменяет сложный процесс вывода одним быстрым проходом через нейронную сеть.
В стандартных вариационных автоэнкодерах (VAE) существует так называемый “разрыв амортизации” (amortization gap) — расхождение между приближенным апостериорным распределением, которое моделирует энкодер, и истинным апостериорным распределением. Этот разрыв возникает из-за того, что энкодер должен аппроксимировать апостериорное распределение для каждого конкретного входного образца, используя лишь параметры, полученные в процессе обучения на всем наборе данных. Следовательно, энкодер вынужден “усреднять” информацию о различных апостериорных распределениях, что приводит к потере точности и снижению качества генерируемых данных. Величина этого разрыва напрямую влияет на качество обучения и способность VAE к эффективному моделированию сложных распределений данных. D_{KL}(q(z|x) || p(z|x)) является мерой этого разрыва, где q(z|x) — приближенное апостериорное распределение, а p(z|x) — истинное апостериорное распределение.
Иерархические Вариационные Автоэнкодеры: Построение Сложных Представлений
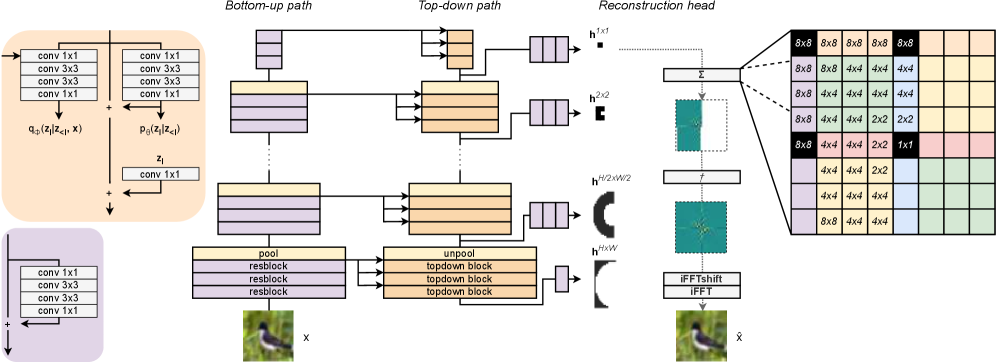
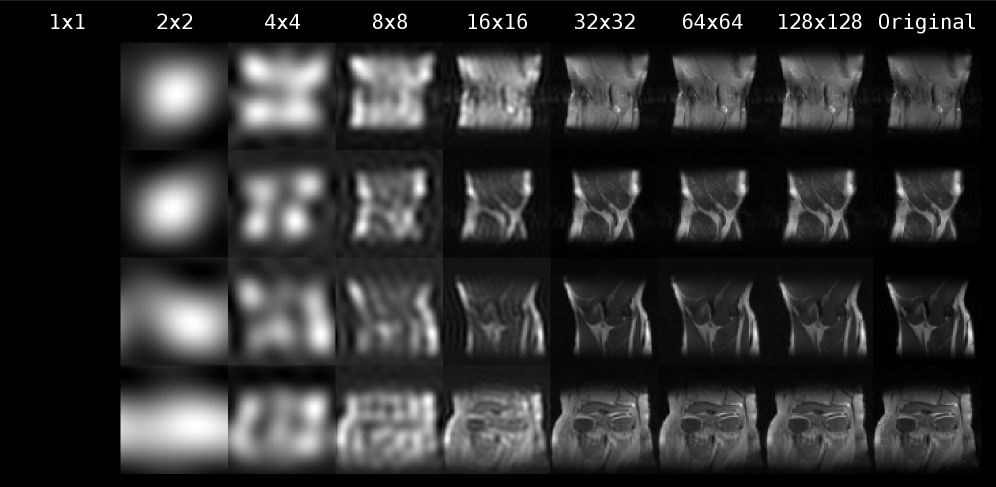
Иерархические вариационные автоэнкодеры (HVAE) отличаются от стандартных VAE наличием многоуровневого скрытого пространства. Вместо одного вектора латентных переменных, HVAE используют иерархическую структуру, где каждый уровень представляет данные на разной степени абстракции. Например, первый уровень может кодировать общие характеристики данных, а последующие уровни — более тонкие детали. Такая структура позволяет моделировать сложные зависимости в данных и создавать более богатые и нюансированные представления, что особенно полезно для генерации и реконструкции сложных образцов. Каждый уровень латентного пространства подвергается процессу кодирования и декодирования, позволяя модели улавливать различные аспекты входных данных и формировать более полное представление о них.
Комбинирование иерархических вариационных автоэнкодеров (HVAE) с итеративным выводом позволяет повысить точность и стабильность реконструкции данных. В стандартных автоэнкодерах декодирование происходит за один проход, что может приводить к неточностям, особенно при работе со сложными данными. Итеративный вывод предполагает последовательное уточнение представления в латентном пространстве и последующую реконструкцию, повторяя этот процесс несколько раз. Каждая итерация использует результаты предыдущей для улучшения качества реконструкции. Это особенно эффективно в HVAE, где многоуровневая структура латентного пространства позволяет более детально моделировать данные и эффективно использовать информацию, полученную на каждой итерации. Повторяющиеся шаги уточнения позволяют алгоритму более точно приближаться к истинному распределению данных и снижать вероятность возникновения нестабильных или нереалистичных реконструкций.
Метод стопки (stacked inference) оптимизирует процесс итеративного вывода в иерархических вариационных автоэнкодерах (HVAE) путем развертывания последовательности итераций. Вместо последовательного выполнения итераций во время вывода, все шаги разворачиваются в единую вычислительную структуру. Это позволяет эффективно вычислять градиенты по всем итерациям одновременно, что существенно ускоряет процесс обучения и вывода. Развернутая структура также упрощает применение стандартных методов оптимизации и позволяет более эффективно использовать параллельные вычисления, что приводит к повышению производительности и снижению вычислительных затрат.
IA-HVAE: Оптимизация Градиентов для Решения Обратных Задач
Итеративный Амортизированный Иерархический Вариационный Автоэнкодер (IA-HVAE) использует каскадную (stacked) структуру сетей аппроксимации и декодирования, оптимизируя процесс решения обратных задач на основе градиентов. Такой подход позволяет значительно повысить производительность по сравнению с традиционными методами, за счет итеративного уточнения латентного представления и использования информации о градиенте ошибки декодирования для корректировки параметров сети аппроксимации. В рамках IA-HVAE градиенты, полученные на этапе декодирования, используются для непосредственной оптимизации параметров сетей аппроксимации на каждом уровне иерархии, что обеспечивает более эффективное обучение и улучшенные результаты в задачах, требующих восстановления данных по неполной или зашумленной информации.
Ключевая инновация IA-HVAE, агрегация латентных переменных, обеспечивает прямой доступ каждой латентной прослойки к градиенту, отражающему её вклад в общую функцию потерь. Это позволяет оптимизировать вклад каждой прослойки независимо, что значительно повышает эффективность обучения и сходимость модели. В отличие от стандартных VAE, где градиенты распространяются последовательно через все слои, IA-HVAE обеспечивает локальную оптимизацию для каждого латентного представления, что приводит к более быстрой и точной реконструкции исходного сигнала или изображения. Такой подход особенно важен при решении обратных задач, где требуется точное восстановление данных из зашумленных или неполных наблюдений.
В архитектуре IA-HVAE для эффективной обработки сигналов используется разложение в частотной области, реализуемое посредством быстрого преобразования Фурье (FFT). Этот подход позволяет переходить от представления сигнала во временной области к представлению в частотной, что упрощает операции, такие как фильтрация и реконструкция. Применение FFT значительно снижает вычислительную сложность обработки сигналов, особенно для больших объемов данных, поскольку операции в частотной области часто могут быть выполнены быстрее, чем аналогичные операции во временной области. В IA-HVAE, FFT применяется для оптимизации процесса кодирования и декодирования, что способствует повышению скорости и эффективности обработки сигналов.
В архитектуре IA-HVAE достигнуто 35-кратное ускорение процесса инференса для глубоких сетей по сравнению с базовой версией HVAE. Это повышение производительности достигается без ухудшения качества реконструкции, а в некоторых случаях и с его улучшением. Ускорение обусловлено оптимизированной передачей градиентов и эффективной агрегацией латентных переменных, что позволяет значительно сократить время вычислений при сохранении или повышении точности восстановления сигнала.
Области Применения и Перспективы Развития
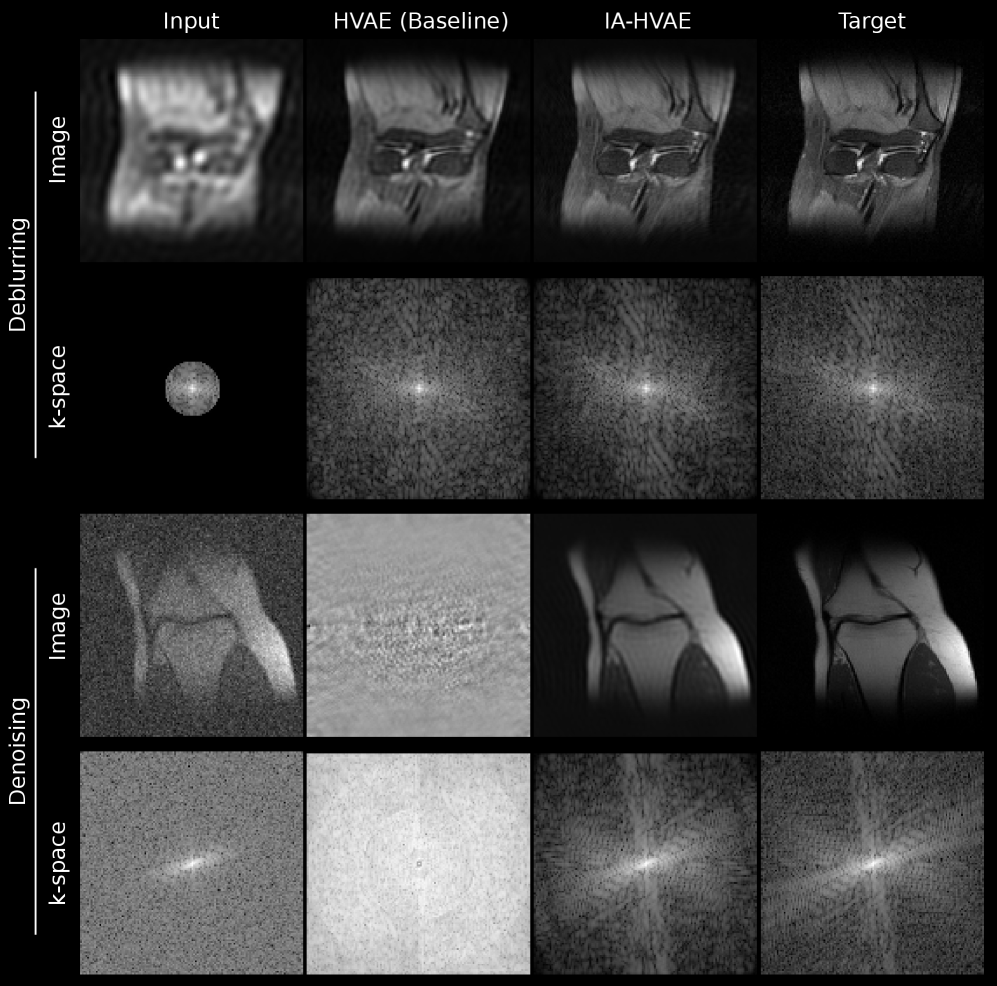
Инновационная архитектура IA-HVAE продемонстрировала передовые результаты в решении задач восстановления изображений, таких как удаление размытости и подавление шумов. В ходе экспериментов модель превзошла существующие алгоритмы по ключевым показателям качества, включая пиковое отношение сигнал/шум (PSNR) и структурное сходство (SSIM). Благодаря способности эффективно разделять и восстанавливать скрытые детали, IA-HVAE обеспечивает более четкое и реалистичное восстановление изображений, открывая новые возможности для применения в различных областях, начиная от улучшения качества фотографий и заканчивая обработкой медицинских изображений.
Архитектура IA-HVAE, отличающаяся высокой гибкостью, в сочетании с эффективными методами оптимизации, делает её особенно ценным инструментом для решения разнообразных обратных задач. В частности, это открывает широкие перспективы в таких областях, как медицинская визуализация, где восстановление чёткого изображения из зашумлённых или неполных данных имеет решающее значение для диагностики. Аналогичным образом, в обработке сигналов, IA-HVAE способна эффективно восстанавливать исходный сигнал из искажённых данных, находя применение в задачах, требующих высокой точности и надёжности, например, в акустическом зондировании или анализе телекоммуникационных сигналов. Благодаря своей адаптивности, модель способна успешно применяться к задачам с различной сложностью и требованиями к вычислительным ресурсам, что делает её востребованным решением для широкого круга практических применений.
Дальнейшие исследования IA-HVAE направлены на разработку ещё более совершенных методов оптимизации, способных значительно ускорить процесс обучения и повысить качество результатов. Особое внимание уделяется адаптации алгоритма к решению задач, характеризующихся высокой сложностью и объёмом данных, таких как реконструкция изображений из крайне зашумленных источников или восстановление деталей в условиях значительных искажений. Планируется расширить область применения IA-HVAE, включив в неё задачи медицинской визуализации — улучшение качества томографических снимков и магнитно-резонансной томографии — а также обработку сигналов в телекоммуникациях и геофизике. Успешная реализация этих направлений позволит IA-HVAE стать незаменимым инструментом в решении широкого спектра сложных научных и инженерных задач.
В данной работе исследователи предлагают не просто архитектуру, но и способ взращивания системы — Iterative Amortized Hierarchical VAE. Подход, где итеративное уточнение модели сочетается с оптимизацией градиента декодера, напоминает о сложном цикле жизни любой сложной системы. Как справедливо заметил Давид Гильберт: «Мы должны знать. Мы должны знать, что мы знаем». Эта фраза отражает суть предлагаемого метода — стремление к более глубокому пониманию латентного пространства и, следовательно, к более точным решениям обратных задач, таких как размытие и шумоподавление. Система не строится мгновенно, она эволюционирует, самосовершенствуется, и в этом её сила.
Что Дальше?
Представленная архитектура, Iterative Amortized Hierarchical VAE, — лишь очередное усложнение неизбежного. Она стремится оптимизировать процесс вывода, но не решает фундаментальной проблемы: каждая модель — это компромисс между выразительностью и обобщением. Улучшение скорости и точности в решении обратных задач — временное облегчение, а не избавление от зависимости от исходных данных и предположений, заложенных в структуру латентного пространства. Мы разделили систему на уровни, но не судьбу — ошибка в нижнем слое рано или поздно проявится в верхних.
Будущие исследования, вероятно, будут направлены на адаптацию латентного пространства, самообучающиеся априорные распределения, и методы, позволяющие модели самостоятельно определять границы своей компетенции. Однако, стоит помнить: всё связанное когда-нибудь упадёт синхронно. Усложнение архитектуры лишь увеличивает количество потенциальных точек отказа, и иллюзию контроля над хаосом. Попытки создать универсальный решатель обратных задач обречены на провал — слишком различны условия и ограничения реального мира.
Настоящий прогресс лежит не в создании более сложных моделей, а в осознании их ограниченности. Необходимо сместить фокус с оптимизации существующих алгоритмов на разработку систем, способных к самодиагностике и адаптации, признающих собственную неполноту и, возможно, даже — собственную неспособность к решению определённых задач. В конечном счете, модель — это лишь проекция нашего собственного непонимания.
Оригинал статьи: https://arxiv.org/pdf/2601.15894.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Квантовые сети для моделирования молекул: новый подход
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-25 12:59