Автор: Денис Аветисян
Новый подход позволяет унифицированным мультимодальным моделям совершенствоваться через самосоревнование, повышая их надежность и производительность.

В статье представлена UniGame — система постобучения, использующая принцип игры с нулевой суммой между ветвями понимания и генерации для повышения согласованности, производительности и устойчивости унифицированных мультимодальных моделей.
Единые мультимодальные модели, демонстрирующие впечатляющие результаты в понимании и генерации, зачастую страдают от внутренней противоречивости между компактными представлениями для анализа и богатыми реконструкциями для синтеза. В работе ‘UniGame: Turning a Unified Multimodal Model Into Its Own Adversary’ представлен фреймворк UniGame, реализующий самосостязательное постобучение, которое напрямую устраняет эти несоответствия, заставляя ветвь генерации активно искать слабые места в понимании модели. Эксперименты показывают значительное улучшение согласованности, производительности и устойчивости к различным искажениям данных. Может ли подобный подход самообучения стать ключевым принципом для создания более когерентных и надежных мультимодальных моделей будущего?
Проблема Согласованности в Мультимодальных Моделях
Единые мультимодальные модели (UMM) представляют собой перспективное направление в искусственном интеллекте, стремящееся к бесшовной интеграции зрительной и языковой информации. Однако, несмотря на значительный прогресс, эти модели часто демонстрируют структурные несоответствия. Суть проблемы заключается в том, что модель, успешно обрабатывающая визуальные данные или текстовые запросы по отдельности, может испытывать трудности при установлении четкой связи между ними. Это приводит к тому, что понимание входных данных не всегда корректно отражается в генерируемом ответе, что выражается в нелогичных или бессмысленных результатах. Несмотря на впечатляющие показатели в отдельных модальностях, отсутствие структурной согласованности становится серьезным препятствием на пути к созданию действительно интеллектуальных систем, способных к комплексному восприятию и обработке информации.
Несоответствия в работе унифицированных мультимодальных моделей проявляются как разрыв между тем, как модель интерпретирует входящую информацию — будь то изображение или текст — и тем, как она формирует соответствующий выходной сигнал. Иными словами, модель может корректно “увидеть” объект на картинке и даже “понять” его основные характеристики, однако при попытке описать его или ответить на вопрос о нем, генерирует нелогичный или нерелевантный ответ. Этот феномен указывает на то, что внутреннее представление информации, сформированное моделью, не всегда согласуется с тем, что она выдает в качестве результата, создавая проблему для надежности и предсказуемости работы системы. Такое рассогласование подчеркивает необходимость разработки методов, обеспечивающих целостность и согласованность между различными модальностями данных, обрабатываемыми моделью.
Существующие подходы к обработке мультимодальных данных часто демонстрируют несостоятельность при интеграции визуальной и языковой информации, несмотря на высокую эффективность в решении отдельных задач по анализу изображений или текста. Проблема заключается в том, что модель, прекрасно распознающая объекты на картинке или понимающая смысл предложения, не способна последовательно связать эти знания при генерации осмысленного ответа или описания. Это приводит к ситуациям, когда, например, модель может точно определить наличие кошки на фотографии, но сгенерировать абсурдное предложение о ней, или наоборот — описать несуществующий объект, основываясь на неверной интерпретации визуального контекста. Таким образом, высокая производительность в отдельных модальностях не гарантирует надежность и логичность мультимодальных ответов, подчеркивая необходимость разработки принципиально новых методов, обеспечивающих согласованность между визуальными и текстовыми представлениями.

Построение Надежного Моста Понимания и Генерации
Универсальные мультимодальные модели (UMM) функционируют посредством разделения процесса обработки информации на два основных компонента: ветвь понимания (Understanding Branch) и ветвь генерации (Generation Branch). Ветвь понимания отвечает за интерпретацию входных данных, вне зависимости от их модальности (текст, изображение, аудио и т.д.), и преобразование их во внутреннее представление, пригодное для дальнейшей обработки. В свою очередь, ветвь генерации использует это представление для создания выходных данных в требуемом формате, например, текстового ответа или изображения. Взаимодействие между этими двумя ветвями является ключевым для обеспечения комплексной обработки информации и генерации осмысленных результатов.
Языковая модель, выступающая в качестве основы как ветви понимания, так и ветви генерации, выполняет централизованную обработку входной информации и координирует процесс генерации выходных данных. Она обеспечивает преобразование входных данных в векторное представление, которое затем используется для извлечения релевантных знаний и формирования логических выводов в ветви понимания. В ветви генерации эта же модель используется для декодирования векторного представления и создания связного и релевантного текста, обеспечивая согласованность между входными данными и выходными результатами. Фактически, языковая модель выступает единым центром обработки информации, определяя качество и точность всей системы понимания-генерации.
В основе UniGame лежит самопротиворечивая структура, предназначенная для явной проверки согласованности модели. Этот фреймворк использует генеративную ветвь (Generation Branch) в качестве “соперника”, который намеренно генерирует сложные или неоднозначные ответы. Затем понимающая ветвь (Understanding Branch) должна оценить эти ответы и выявить несоответствия или логические ошибки. Постоянно подвергая модель подобным испытаниям, UniGame способствует развитию более надежного и устойчивого механизма рассуждений, поскольку выявляет слабые места в процессе понимания и генерирования.
В рамках UniGame, генеративная ветвь модели намеренно используется в качестве “соперника” для выявления недостатков в понимающей ветви. Этот процесс осуществляется путем постановки сложных вопросов или задач, требующих от понимающей ветви точной интерпретации входных данных. Генеративная ветвь, функционируя как оппонент, создает ответы или сценарии, призванные выявить противоречия или неточности в рассуждениях понимающей ветви. Такой подход позволяет модели активно выявлять собственные слабые места и улучшать качество рассуждений, повышая устойчивость к неоднозначным или сложным входным данным, а также способствуя формированию более надежного понимания.

Состязательное Обучение и Оценка Согласованности
В UniGame для генерации сложных входных данных используется Perturber — облегченная нейронная сеть, создающая структурированные возмущения на границе между визуальным и токенизированным представлением. Данный компонент работает, внося контролируемые изменения в визуальные данные на уровне токенов, что позволяет создавать примеры, предназначенные для проверки устойчивости и надежности модели. Структурированный характер возмущений обеспечивает более целенаправленный и эффективный процесс генерации сложных примеров по сравнению со случайными изменениями, повышая эффективность обучения модели в условиях атак.
Проверка семантической согласованности в UniGame осуществляется с использованием моделей, подобных CLIP, для фильтрации сгенерированных примеров и обеспечения их семантической правдоподобности. CLIP вычисляет сходство между визуальным представлением сгенерированного изображения и его текстовым описанием. Примеры, показывающие низкое сходство, отбрасываются, поскольку они, вероятно, являются семантически неверными или нерелевантными. Этот процесс гарантирует, что в процессе обучения используются только правдоподобные и осмысленные примеры, что повышает стабильность и эффективность алгоритма.
В UniGame используется буфер сложных примеров (Hard-Example Buffer) для хранения семантически правдоподобных, но вызывающих затруднения, входных данных, сгенерированных в процессе состязательного обучения. Данные примеры, прошедшие проверку на семантическую согласованность, сохраняются и затем используются для повторного обучения (replay) модели понимания. Это позволяет усилить устойчивость модели к различным возмущениям и повысить её способность к обобщению, поскольку обучение происходит не только на исходном наборе данных, но и на специально подобранных, сложных примерах, представляющих наибольшую сложность для текущей версии модели.
Процесс обучения реализован посредством Minimax Self-Play, представляющего собой состязательную схему, в которой две ветви — Генерации и Понимания — взаимодействуют друг с другом. Ветвь Генерации стремится максимизировать несоответствие между входными данными и их интерпретацией, создавая сложные и неоднозначные примеры. Одновременно ветвь Понимания нацелена на минимизацию этого несоответствия, улучшая свою способность к точному восприятию и классификации данных. Такое состязательное взаимодействие способствует устойчивости и обобщающей способности модели, поскольку каждая ветвь постоянно пытается преодолеть ограничения другой, стимулируя взаимное улучшение.
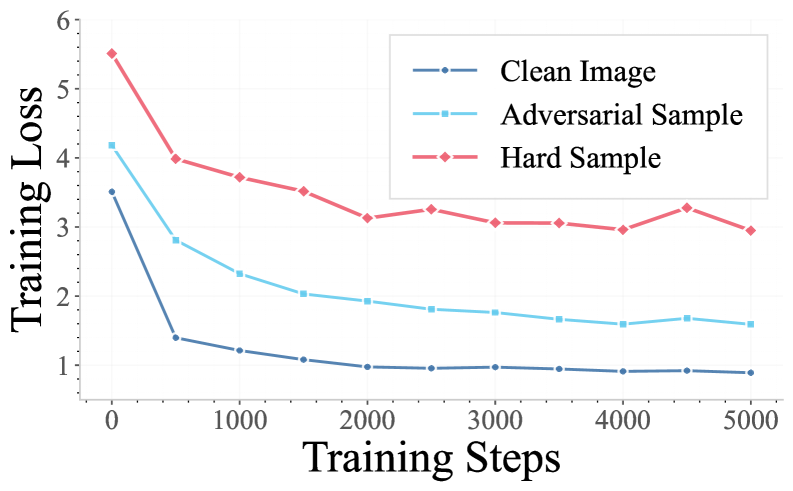
Оценка и Валидация Согласованности UMM
Эффективность разработанной системы подтверждена посредством комплексного тестирования на общепризнанных бенчмарках, таких как VQAv2, MMMU и NaturalBench. Результаты демонстрируют значительное улучшение производительности в задачах, требующих мультимодального рассуждения — то есть, способности системы обрабатывать и интегрировать информацию, поступающую из различных источников, например, изображений и текста. Прохождение этих тестов подтверждает способность системы к более глубокому пониманию и логическому анализу сложных ситуаций, представленных в мультимодальном формате, что является важным шагом на пути к созданию действительно интеллектуальных систем.
Для количественной оценки согласованности между пониманием и генерацией информации используется метрика Wise Score. Данный показатель позволяет объективно измерить, насколько сгенерированный ответ соответствует исходному запросу и контексту, выявляя возможные расхождения или противоречия. Wise Score оценивает семантическую близость между входными данными и сгенерированным текстом, учитывая не только лексическое соответствие, но и смысловую когерентность. Высокий показатель Wise Score свидетельствует о том, что модель способна не только понимать запрос, но и адекватно его интерпретировать, генерируя логически связный и релевантный ответ. Применение Wise Score позволяет проводить более точную и объективную оценку эффективности моделей многомодального понимания, выявляя слабые места и направляя дальнейшие исследования в области улучшения согласованности между пониманием и генерацией.
Для дополнительного подтверждения эффективности разработанной системы, была проведена оценка на базе комплексного теста UnifiedBench. Результаты показали, что UniGame достиг показателя в 82.7%, что свидетельствует о значительном улучшении согласованности в задачах, требующих мультимодального понимания. Этот результат указывает на способность системы надежно интегрировать и обрабатывать информацию из различных источников, обеспечивая более точные и логичные ответы, чем предыдущие модели. Повышенная согласованность, продемонстрированная на UnifiedBench, является ключевым фактором в создании более интеллектуальных и надежных систем искусственного интеллекта, способных к комплексному анализу и принятию решений.
Исследования показали, что UniGame демонстрирует значительное улучшение в точности мультимодального понимания и рассуждений. В частности, при тестировании на бенчмарке MMMU, UniGame превзошел существующие модели на 3,6%, что свидетельствует о более эффективной обработке сложных вопросов, требующих интеграции визуальной и текстовой информации. Кроме того, на NaturalBench, ориентированном на оценку способности модели к обобщению и работе с данными, выходящими за рамки обучающей выборки (OOD — Out-of-Distribution), UniGame достиг повышения точности на 4,8%. Эти результаты подтверждают, что архитектура UniGame способствует более надежному и точному мультимодальному пониманию, особенно в ситуациях, когда требуется работа с незнакомыми данными или сложными логическими задачами.
Архитектура унифицированной мультимодальной модели (UMM) отличается повышенной надежностью и гибкостью благодаря интеграции ключевых компонентов. SigLIP обеспечивает эффективное понимание визуальной информации, позволяя модели извлекать значимые детали из изображений. Stable Diffusion, в свою очередь, предоставляет возможности генерации высококачественных изображений, расширяя спектр задач, которые может решать модель. В качестве основы для обработки языка используется GPT-OSS, обеспечивающий мощные возможности генерации и понимания текста. Совместное использование этих компонентов позволяет UMM эффективно обрабатывать и интегрировать информацию из различных модальностей, обеспечивая высокую производительность в широком диапазоне мультимодальных задач и демонстрируя адаптивность к различным типам входных данных.
Будущие Направления: К Истинно Интеллектуальным Мультимодальным Системам
Дальнейшее исследование методов состязательного обучения, подобных тем, что связаны с Adversarial Training, сулит значительное повышение устойчивости многомодальных систем. Эти техники, заключающиеся в намеренном добавлении незначительных, но целенаправленных возмущений во входные данные, позволяют моделям учиться распознавать и игнорировать эти возмущения, делая их более надежными в условиях реального мира, где данные часто бывают зашумлены или неполны. Посредством постоянной «борьбы» с искусственно созданными помехами, система совершенствует свою способность к обобщению и, как следствие, демонстрирует повышенную устойчивость к непредсказуемым входным данным, что особенно важно для критически важных приложений, где надежность имеет первостепенное значение. Углубленное изучение и адаптация этих методов позволит создавать более надежные и эффективные многомодальные системы, способные к комплексному взаимодействию с миром.
Подходы, основанные на реконструкции данных, представляют собой перспективное направление для повышения качества и согласованности генерируемых мультимодальных систем. Суть этих методов заключается в том, чтобы обучать модель не только генерировать выходные данные, но и восстанавливать исходные входные данные из сгенерированных. Этот процесс заставляет модель глубже понимать взаимосвязи между различными модальностями — например, текстом и изображением — и создавать более связные и логичные результаты. В процессе обучения модель стремится минимизировать разницу между исходными данными и реконструированными, что способствует улучшению внутренней репрезентации знаний и повышению устойчивости к шумам и искажениям. В перспективе, развитие этих подходов может привести к созданию систем, способных генерировать не просто правдоподобные, но и семантически корректные и последовательные мультимодальные выходные данные, приближаясь к человеческому уровню понимания и генерации информации.
Для дальнейшего прогресса в области универсальных мультимодальных моделей (UMM) критически важно расширение спектра используемых тестовых наборов. Существующие бенчмарки часто ограничиваются задачами, требующими базового понимания и сопоставления данных. Вместо этого, необходимо включить в оценку более сложные задания, требующие абстрактного мышления, логического вывода и решения проблем, приближенных к человеческому уровню. Особенно актуальны тесты, проверяющие способность моделей к причинно-следственному анализу, пониманию намерений и применению здравого смысла в новых, незнакомых ситуациях. Разработка и внедрение таких бенчмарков позволит не только точнее оценить текущие возможности UMM, но и станет мощным стимулом для создания действительно интеллектуальных систем, способных к глубокому и осмысленному взаимодействию с окружающим миром.
Исследования показали, что объединение подходов UniGame и RecA позволяет добиться дополнительного прироста в 0,5% точности при решении задач MMMU (Multimodal Multiple-choice Question Answering). UniGame, основанный на игровом подходе к обучению, позволяет модели исследовать различные стратегии ответа, в то время как RecA, использующий рекуррентные механизмы внимания, помогает модели более эффективно обрабатывать и интегрировать информацию из различных модальностей. Совместное применение этих методов, по всей видимости, позволяет более полно использовать потенциал мультимодальных данных и улучшает способность системы к логическому мышлению и принятию решений, что подтверждается наблюдаемым улучшением метрики точности в сложных задачах.
В конечном счете, стремление к созданию мультимодальных систем выходит за рамки простого распознавания и генерации информации. Разрабатываемые модели должны демонстрировать подлинный интеллект и здравый смысл, что предполагает способность к абстрактному мышлению, решению проблем и адаптации к новым ситуациям, подобно человеческому разуму. Это требует интеграции знаний из различных источников, способности к причинно-следственному анализу и умения делать обоснованные выводы даже при неполной или противоречивой информации. Достижение этой цели предполагает не только усовершенствование алгоритмов, но и разработку новых подходов к представлению знаний и обучению моделей, способных к самостоятельному обучению и творческому решению задач.

Исследование демонстрирует, что попытка создания абсолютно надежной системы — это иллюзия. Авторы UniGame, по сути, признают неизбежность “вырождения паттерна” через определенное количество релизов, моделируя борьбу между пониманием и генерацией как непрекращающуюся игру. В этом контексте особенно примечательна фраза Марвина Минского: «Лучший способ предсказать будущее — это создать его». UniGame не стремится построить идеальную модель, а создает среду, в которой модель постоянно адаптируется и совершенствуется, сталкиваясь с собственными недостатками. Это не архитектурный триумф, а экология, где каждый выбор ведет к прогнозируемым последствиям, а не к статичной надежности.
Что дальше?
Представленная работа, при всей её элегантности в создании само-состязательной среды для унифицированных мультимодальных моделей, лишь обнажает глубину проблем, связанных с поиском истинной устойчивости. Недостаточно заставить модель выдерживать атаки, порождённые ею же самой; необходимо признать, что каждое улучшение производительности — это, по сути, прогнозирование будущих точек отказа. Система не становится надежнее, она лишь демонстрирует более изощренные способы падения.
Будущие исследования неизбежно столкнутся с вопросом о масштабируемости подобного подхода. Минимаксные игры требуют ресурсов, и оптимизация этой борьбы между пониманием и генерацией, вероятно, станет узким местом. Однако, истинная ценность лежит не в преодолении этих технических сложностей, а в принятии того факта, что мониторинг — это не поиск ошибок, а осознанный страх перед неизбежным. Настоящая устойчивость начинается там, где заканчивается уверенность в непогрешимости архитектуры.
Вместо того, чтобы стремиться к созданию идеальной модели, следует сосредоточиться на выращивании экосистемы, способной быстро адаптироваться к новым видам сбоев. Ведь система — это не инструмент, а живой организм, и её будущее определяется не запрограммированными правилами, а способностью к самовосстановлению после каждой, неизбежно случающейся, катастрофы.
Оригинал статьи: https://arxiv.org/pdf/2511.19413.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Квантовая обработка данных: новый подход к повышению точности моделей
- Сохраняя геометрию: Квантование для эффективных 3D-моделей
- Квантовый Переход: Пора Заботиться о Криптографии
- Квантовая химия: моделирование сложных молекул на пороге реальности
- Квантовые симуляторы: проверка на прочность
- Квантовые прорывы: Хорошее, плохое и смешное
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Квантовые вычисления: от шифрования армагеддона до диверсантов космических лучей — что дальше?
2025-11-28 06:11