Автор: Денис Аветисян
Новая работа исследует, как существующие убеждения человека влияют на принятие решений при использовании систем поддержки на основе машинного обучения.

Предлагается вычислительная модель для изучения взаимодействия между человеком и системами поддержки принятия решений на основе ИИ, учитывающая влияние априорных убеждений и неопределенности модели.
Несмотря на растущую роль систем поддержки принятия решений на основе машинного обучения, механизмы взаимодействия человека и ИИ остаются недостаточно изученными. В данной работе представлена вычислительная модель — ‘2-Step Agent: A Framework for the Interaction of a Decision Maker with AI Decision Support’ — для анализа влияния априорных убеждений агента и взаимодействия с ML-DS на принимаемые решения и конечные результаты. Показано, что даже при идеальной точности модели, несоответствие между априорными убеждениями и данными может привести к ухудшению результатов по сравнению с отсутствием поддержки принятия решений. Какие факторы необходимо учитывать при разработке и внедрении систем поддержки принятия решений, чтобы избежать нежелательных последствий и обеспечить эффективное взаимодействие человека и ИИ?
Вызов Разумного Анализа Данных
В современных системах машинного обучения часто наблюдается тенденция к приоритету предсказательной точности над пониманием механизмов, лежащих в основе этих предсказаний. Несмотря на впечатляющие успехи в распознавании образов и прогнозировании, многие развернутые модели ограничиваются лишь выдачей результата, не предоставляя объяснений о том, почему был сделан тот или иной вывод. Такое упущение особенно критично в областях, требующих высокой степени ответственности, где недостаточно просто знать, что произойдет, необходимо понимать причины и следствия. Отсутствие прозрачности в процессе принятия решений не только затрудняет проверку и отладку моделей, но и подрывает доверие к ним, препятствуя их широкому внедрению в критически важные приложения.
В ситуациях, требующих принятия важных решений, простого предсказания исхода недостаточно. Агенты, будь то искусственный интеллект или люди, должны обладать способностью к причинно-следственному мышлению для эффективной навигации в сложных средах. Предсказание лишь указывает на то, что произойдет, в то время как понимание причинно-следственных связей позволяет объяснить почему это происходит, а также прогнозировать последствия различных действий. Именно причинно-следственное мышление позволяет агентам адаптироваться к новым ситуациям, исправлять ошибки и действовать разумно даже при наличии неполной информации или в условиях неопределенности. Без способности к анализу причин и следствий, решения, основанные лишь на корреляциях, могут оказаться ошибочными и привести к нежелательным последствиям.
Традиционные подходы к анализу данных часто смешивают корреляцию и причинно-следственную связь, что приводит к ошибочным выводам и потенциально неблагоприятным последствиям. Это особенно заметно в системах, где агенты оперируют неверными предварительными убеждениями. Исследования показывают, что даже небольшие погрешности в исходных знаниях могут значительно исказить процесс принятия решений, приводя к неоптимальным или даже опасным результатам. Например, если агент ошибочно полагает, что определенное событие является причиной другого, он может предпринять неэффективные действия или упустить важные факторы, влияющие на исход. Разработанная методология демонстрирует, как эти ошибки в предварительных убеждениях усиливаются в сложных средах, подчеркивая необходимость разработки систем, способных отличать истинные причинно-следственные связи от простых корреляций для обеспечения надежных и обоснованных решений.
Двухэтапный Агент: Структура Разумного Действия
Двухэтапный агентский фреймворк разделяет процесс принятия решений на два последовательных этапа: байесовское обновление убеждений и причинно-следственный вывод. Байесовский этап включает в себя корректировку текущих представлений агента о мире на основе предсказаний прогностической модели, используя принципы байесовского обновления. Последующий этап, причинно-следственный вывод, предназначен для определения оптимальных действий, основываясь на обновленных убеждениях агента. Такое разделение позволяет более точно анализировать процессы генерации данных и повысить качество принятия решений в условиях неопределенности, что особенно важно для снижения негативных последствий, вызванных расхождениями между априорными убеждениями и обучающими данными.
На первом этапе, агент обновляет свои представления о мире, используя прогнозную модель и процедуру Байесовского обновления. Этот процесс предполагает сопоставление предсказаний модели с наблюдаемыми данными для вычисления апостериорного распределения вероятностей, отражающего обновленные убеждения агента. Фактически, агент корректирует свою изначальную оценку вероятности различных состояний мира, учитывая новую информацию, полученную из предсказаний модели. P(S|D) = \frac{P(D|S)P(S)}{P(D)}, где P(S|D) — апостериорная вероятность состояния S при данных D, P(D|S) — вероятность наблюдения данных D при состоянии S, P(S) — априорная вероятность состояния S, а P(D) — вероятность данных D.
Второй этап, этап каузальной инференции, предполагает использование обновленных убеждений агента для определения оптимального действия. На этом этапе агент анализирует причинно-следственные связи между доступными действиями и ожидаемыми результатами, основываясь на сформированной после байесовского обновления модели мира. Это позволяет агенту не просто реагировать на текущие наблюдения, но и предвидеть последствия своих действий, выбирая наиболее эффективную стратегию для достижения поставленной цели. Процесс каузальной инференции использует обновленные вероятности и взаимосвязи для оценки потенциальных результатов каждого действия и выбора наилучшего, максимизирующего ожидаемую выгоду или минимизирующего риски.
Разделение процесса принятия решений на байесовское обновление убеждений и причинно-следственный вывод позволяет агенту более точно моделировать генеративный процесс данных и улучшает принятие решений в условиях неопределенности. Данный подход критически важен для смягчения негативных последствий, возникающих из-за расхождений между априорными убеждениями и данными, используемыми для обучения. Несоответствие между априорными знаниями агента и реальным распределением данных может приводить к ошибочным выводам и неоптимальным действиям, особенно в ситуациях, где обучение происходит на нерепрезентативных выборках. Разделение этих этапов позволяет более эффективно идентифицировать и корректировать такие расхождения, повышая надежность и предсказуемость поведения агента.

Построение Надежных Прогностических Моделей
В рамках двухэтапной (2-Step) агентовой структуры, предиктивная модель является ключевым компонентом, обученным на исторических данных, представленных в виде Структурной причинно-следственной модели (SCM). SCM служит репрезентацией базового процесса генерации данных, определяя взаимосвязи между переменными и их распределения. Обучение модели на SCM позволяет ей улавливать закономерности и зависимости, что необходимо для прогнозирования будущих событий или оценки контрфактических сценариев. Эффективность предиктивной модели напрямую зависит от качества и полноты исторической SCM, а также от адекватности выбранного алгоритма обучения.
Для повышения эффективности и масштабируемости моделей прогнозирования используется модель «Plate Model», основанная на использовании общих параметров и распределений. Этот подход позволяет снизить вычислительную сложность и объем требуемой памяти за счет совместного использования статистических характеристик между различными компонентами модели. Вместо независимой оценки параметров для каждого элемента, Plate Model предполагает, что они следуют общему распределению, что существенно упрощает процесс обучения и делает модель более устойчивой к переобучению, особенно при работе с большими объемами данных. Эффективность Plate Model обусловлена возможностью представления и обработки сложных зависимостей между переменными с меньшими вычислительными затратами.
В рамках Plate Model для моделирования характеристик данных используются вероятностные распределения, такие как Нормальное Продукт-распределение (Normal Product Distribution) и Хи-квадрат-распределение (Chi-Squared Distribution). Нормальное Продукт-распределение эффективно для моделирования данных, где взаимосвязь между переменными описывается мультипликативным образом, а Хи-квадрат-распределение применимо для описания распределения сумм квадратов независимых стандартных нормальных величин, что позволяет моделировать дисперсию и другие статистические характеристики данных. Выбор конкретного распределения зависит от природы моделируемых данных и целей анализа, обеспечивая гибкость и точность в построении предсказательных моделей.
В рамках построения прогностической модели, метод наименьших квадратов (Ordinary Least Squares) используется для оценки параметров. Полученные результаты показывают, что данная структура способна корректировать оценки CATE (Conditional Average Treatment Effect) в случаях, когда априорные убеждения (prior beliefs) не соответствуют действительности. Однако, значительное расхождение априорных убеждений с реальным процессом генерации данных может привести к ухудшению результатов и снижению точности оценок CATE. Таким образом, качество априорных убеждений критически важно для эффективности работы модели.

Влияние на Надежность и Достоверность Искусственного Интеллекта
Двухэтапный агентский фреймворк представляет собой принципиально новый подход к созданию систем искусственного интеллекта, который позволяет не только предсказывать, но и обеспечивать их интерпретируемость и надёжность. В отличие от традиционных “черных ящиков”, этот фреймворк структурирует процесс принятия решений, разделяя его на этапы, что облегчает понимание логики работы агента. Такая архитектура способствует выявлению и устранению потенциальных смещений, а также повышает устойчивость системы к неверным данным или неожиданным ситуациям. В результате, создаваемые системы демонстрируют более высокую степень доверия и позволяют проводить более обоснованные и прозрачные решения, что особенно важно в критически важных областях применения, таких как здравоохранение и финансы.
Явное моделирование априорных убеждений агента представляет собой ключевой подход к снижению предвзятости и повышению устойчивости процесса принятия решений. В отличие от традиционных моделей, которые часто полагаются на «черный ящик», данная методика позволяет учитывать изначальные представления агента о мире, что особенно важно в ситуациях, где данные ограничены или содержат искажения. Учет этих априорных знаний позволяет корректировать решения, избегая ситуаций, когда агент необоснованно доверяет ошибочным паттернам или упускает важные факторы. Таким образом, явное моделирование убеждений способствует созданию более надежных и справедливых систем искусственного интеллекта, способных адаптироваться к меняющимся условиям и избегать систематических ошибок.
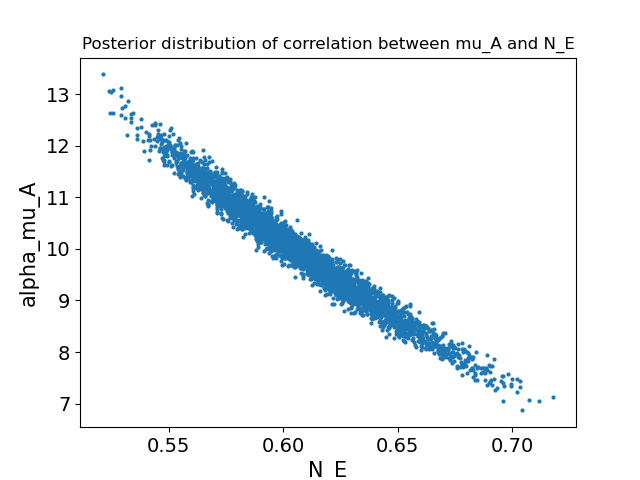
Анализ показал существенную корреляцию между эффектом от вмешательства NE и исторической политикой \mu_A после взаимодействия с системой машинного обучения для поддержки принятия решений (ML-DS). Этот результат демонстрирует способность разработанной двухступенчатой структуры агента не только прогнозировать, но и выявлять, а также обновлять убеждения агента на основе получаемого опыта. В частности, система способна уловить зависимость между текущим воздействием и предшествующими стратегиями, что позволяет ей корректировать свои внутренние модели и принимать более обоснованные решения. Такая способность к адаптации и обновлению убеждений критически важна для создания надежных и эффективных систем искусственного интеллекта, особенно в областях, где требуется учитывать сложные взаимосвязи и динамически меняющиеся условия.
Полученные результаты имеют существенное значение для областей, связанных с высокими рисками, таких как здравоохранение, финансы и автономные системы. Неверные представления об особенностях данных, эффектах лечения или исторической политике могут приводить к ухудшению результатов и принятию неоптимальных решений. Например, в медицине ошибочные предположения о распространенности заболевания могут привести к неправильной диагностике и назначению неэффективного лечения. В финансовой сфере неверная оценка рисков может привести к значительным убыткам. В автономных системах, таких как беспилотные автомобили, искаженные представления о дорожной обстановке или поведении других участников движения могут привести к авариям. Поэтому, разработка и применение методов, позволяющих выявлять и корректировать ошибочные представления, является критически важной задачей для обеспечения надежности и безопасности систем искусственного интеллекта в этих областях.

Исследование демонстрирует, что даже идеально спроектированные модели машинного обучения могут привести к неблагоприятным последствиям, если представления агента и алгоритма не согласованы. Этот процесс напоминает эволюцию систем, где время — не просто метрика, а среда, определяющая их адаптацию. Как отмечал Карл Фридрих Гаусс: «Я не знаю, как я выгляжу в глазах других, но я чувствую себя в своей шкуре как ребенок». Эта фраза отражает важность внутренней согласованности и соответствия между представлениями и реальностью, что критически важно при взаимодействии агента с системами поддержки принятия решений. Несоответствие между априорными убеждениями и моделью может привести к ошибочным выводам, подобно тому, как неверное восприятие реальности мешает адекватному действию.
Что впереди?
Представленная работа, исследуя взаимодействие агента и систем поддержки принятия решений на основе машинного обучения, неизбежно наталкивается на вопрос о временной природе любого улучшения. Даже идеально откалиброванная модель, как показывает анализ, подвержена эрозии из-за несоответствия априорным убеждениям агента. Это не недостаток модели, а закономерность: любое нововведение стареет быстрее, чем предполагалось. Временная аналитика подсказывает, что поиск «идеальной» модели — занятие бесплодное; важнее понимать динамику расхождения между моделью и убеждениями, которые она должна корректировать.
Очевидным направлением дальнейших исследований представляется изучение механизмов адаптации априорных убеждений. Как агент учится «отпускать» устаревшие представления, не теряя при этом критического взгляда на предлагаемые решения? Откат, в данном контексте, — это не ошибка, а путешествие назад по стрелке времени, возвращение к более фундаментальным принципам, когда новая информация не вписывается в существующую картину мира. Понимание этого процесса может привести к разработке более устойчивых и гибких систем поддержки принятия решений.
Неизбежно возникает вопрос о масштабируемости предложенного подхода. Как учитывать когнитивные искажения и эмоциональные факторы, влияющие на формирование априорных убеждений? Попытки «оцифровать» субъективный опыт обречены на упрощения, но игнорирование этой сложности приведет к созданию систем, неспособных к адекватному взаимодействию с реальными агентами. В конечном счете, ценность исследования заключается не в создании идеальной модели, а в осознании неизбежной энтропии любой системы.
Оригинал статьи: https://arxiv.org/pdf/2602.21889.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Квантовая самовнимательность на службе у поиска оптимальных схем
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
- Квантовый скачок: от лаборатории к рынку
- Виртуальная примерка без границ: EVTAR учится у образов
2026-02-26 14:23