Автор: Денис Аветисян
Новое исследование ставит под сомнение надежность популярных методов интерпретации работы больших языковых моделей.
Анализ существующих подходов к интерпретируемости больших языковых моделей выявил критические недостатки и артефакты, приводящие к ложным выводам о семантическом понимании.
Несмотря на широкое распространение больших языковых моделей (LLM) и их впечатляющую производительность, механизмы, лежащие в основе их работы, остаются во многом неясными. В работе ‘LLMs Explain’t: A Post-Mortem on Semantic Interpretability in Transformer Models’ предпринята попытка оценить надежность распространенных методов интерпретации LLM, таких как анализ внимания и вывод свойств на основе векторных представлений. Полученные результаты демонстрируют, что эти методы часто дают ложные результаты из-за методологических ошибок и артефактов в данных, а не благодаря реальному пониманию семантики. Каковы альтернативные подходы к интерпретации LLM, позволяющие получить достоверные и полезные сведения о принципах их работы?
Разоблачение Чёрного Ящика: Вызовы Интерпретируемости БЯМ
Несмотря на впечатляющие успехи в обработке языка и генерации текста, большие языковые модели (БЯМ) остаются своеобразными «черными ящиками». Их внутренняя работа, сложная сеть взаимосвязей между миллиардами параметров, практически непрозрачна для исследователей и пользователей. Эта непрозрачность вызывает серьезные опасения, поскольку затрудняет понимание того, как БЯМ принимают решения и формируют ответы. Отсутствие контроля над процессом генерации может привести к непредсказуемым, а иногда и нежелательным результатам, что особенно критично при использовании БЯМ в ответственных областях, таких как медицина, финансы или право. Повышение прозрачности и объяснимости БЯМ является ключевой задачей, необходимой для укрепления доверия к этим мощным инструментам и обеспечения их безопасного и эффективного использования.
Традиционные методы анализа работы больших языковых моделей (LLM) сталкиваются с серьезными трудностями при попытке связать огромный масштаб этих систем с осмысленностью их решений. Подходы, успешно применявшиеся к более простым алгоритмам, оказываются неэффективными при анализе миллиардов параметров и сложных взаимодействий внутри LLM. Попытки проследить путь принятия решения, например, через анализ активаций нейронов, часто приводят к «черному ящику» — множеству данных, не позволяющих выделить значимые закономерности и понять, какие факторы действительно влияют на результат. Это требует разработки принципиально новых подходов, способных обойти ограничения масштаба и установить связь между внутренней структурой модели и её семантическим поведением, что необходимо для обеспечения надежности и предсказуемости LLM в критически важных областях.
Крайне важно понимать, каким образом большие языковые модели (БЯМ) приходят к тем или иным выводам, особенно при их внедрении в сферы, связанные с высокой ответственностью и чувствительными данными. Непрозрачность процесса принятия решений БЯМ представляет значительный риск в таких областях, как здравоохранение, финансы и правосудие, где ошибки могут иметь серьезные последствия. Невозможность проследить логику рассуждений модели не позволяет оценить надежность и предвзятость её ответов, что ставит под сомнение доверие к ней как к инструменту поддержки принятия решений. Поэтому, разработка методов интерпретации и объяснения работы БЯМ является не просто академической задачей, а необходимостью для обеспечения безопасного и этичного использования этих мощных технологий.
Извлечение Смысла: Вывод Свойств и Векторные Представления
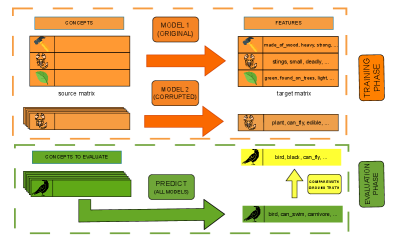
Метод выведения свойств на основе векторных представлений (Embedding-Based Property Inference) представляет собой эффективный подход к интерпретируемости больших языковых моделей (LLM), позволяющий установить связь между внутренними представлениями модели и понятными человеку концепциями. Этот подход позволяет анализировать, как LLM кодирует информацию, сопоставляя векторы, представляющие входные токены, с человеко-понятными атрибутами или свойствами. В отличие от методов “черного ящика”, данный подход стремится сделать внутренние процессы модели более прозрачными, предоставляя возможность понять, какие знания и ассоциации заложены в ее внутренних представлениях. Эффективность метода заключается в возможности количественно оценить, насколько определенное свойство представлено в векторе, что позволяет выявлять и анализировать предвзятости или нежелательные ассоциации в модели.
В основе декодирования рассуждений больших языковых моделей (LLM) лежат векторные представления входных токенов, известные как токеновые эмбеддинги. Каждый токен, будь то слово или часть слова, преобразуется в многомерный вектор, отражающий его семантические и синтаксические характеристики в контексте модели. Эти эмбеддинги служат основой для анализа, позволяя исследователям количественно оценить, как LLM представляет и обрабатывает информацию. Использование токеновых эмбеддингов позволяет сопоставить внутренние представления модели с внешними понятиями и свойствами, предоставляя инструмент для интерпретации ее поведения и выявления скрытых закономерностей в процессе обработки языка.
Сопоставление векторных представлений токенов (Token Embeddings) с нормами признаков — списками психологических характеристик — позволяет исследовать представления, которыми обладает языковая модель о конкретных словах или понятиях. Этот подход заключается в определении степени соответствия между вектором, представляющим токен, и векторами, представляющими различные психологические атрибуты, такие как размер, подвижность, эмоциональная валентность или конкретные действия, связанные с этим токеном. Анализ проекций векторных представлений токенов на векторы признаков позволяет выявить, какие характеристики наиболее сильно связаны с данным словом в контексте знаний языковой модели, что дает возможность понять, как модель ‘понимает’ и категоризирует различные концепции.
Методы Декодирования: От Линейной Регрессии к Нейронным Сетям
Метод частных наименьших квадратов (PLS-регрессия) представляет собой вычислительно эффективный подход к аппроксимации отображения между векторными представлениями (embeddings) и интерпретируемыми признаками. В отличие от более сложных методов, PLS-регрессия снижает вычислительные затраты за счет поиска линейных комбинаций признаков, которые наилучшим образом объясняют дисперсию в данных embeddings. Этот подход особенно полезен на начальных этапах исследования, когда требуется быстро оценить потенциальную связь между векторными представлениями и целевыми признаками, прежде чем переходить к более ресурсоемким алгоритмам. Эффективность PLS-регрессии обусловлена её способностью обрабатывать данные с высокой размерностью и коррелированными признаками, что часто встречается в задачах анализа embeddings.
В отличие от методов, основанных на линейной регрессии, многослойные нейронные сети (Feedforward Neural Networks) предоставляют повышенную гибкость в моделировании взаимосвязей между входными представлениями и интерпретируемыми признаками. Это достигается за счет использования нелинейных функций активации в каждом слое сети, что позволяет моделировать сложные, нелинейные зависимости, которые не могут быть адекватно представлены линейными моделями. Способность к моделированию нелинейных отношений позволяет нейронным сетям потенциально достигать более высокой точности в задачах декодирования, особенно в случаях, когда взаимосвязи между представлениями и признаками не являются линейными. Архитектура нейронных сетей, включающая несколько слоев и нелинейные активации, позволяет им аппроксимировать практически любую функцию, при условии достаточного количества параметров и данных для обучения.
Наши результаты показывают, что методы декодирования, такие как линейная регрессия и нейронные сети, часто демонстрируют высокую производительность даже при случайном перемешивании признаков. Это указывает на то, что модели опираются скорее на структурные свойства входных данных, а не на семантическое значение признаков. В частности, метрика F1@10 остается конкурентоспособной даже при случайном назначении признаков, что подтверждает преобладание структурного анализа над пониманием семантики при декодировании эмбеддингов.
Эрозия Идентичности Токенов: Фундаментальное Ограничение
Представление о непрерывности токенов — концепция, согласно которой скрытые представления в трансформерах всё ещё отражают исходный входной токен — подвергается всё большему сомнению в свете архитектурных особенностей современных моделей. Традиционно предполагалось, что каждый токен сохраняет свою идентичность на протяжении всех слоёв обработки, однако исследования показывают, что механизмы, такие как многоголовое смешивание и использование остаточных связей, способствуют растворению токено-специфической информации. В результате, связь между исходным токеном и его представлением в скрытых слоях становится всё более размытой, что ставит под вопрос возможность прямого декодирования семантического содержания из этих представлений. Этот феномен указывает на то, что трансформеры, возможно, не столько “понимают” значение отдельных токенов, сколько оперируют с более абстрактными геометрическими паттернами в пространстве представлений.
Архитектура современных трансформаторов, включающая многоголовое смешивание (Multi-Head Mixing) и использование остаточных связей (Residual Connections), оказывает существенное влияние на сохранение информации об исходных токенах. Эти процессы, предназначенные для повышения эффективности обучения и обогащения представлений, приводят к рассеиванию и смешению токено-специфических признаков в скрытых слоях нейронной сети. В результате, первоначальная связь между входным токеном и его представлением в скрытом пространстве постепенно ослабевает, что затрудняет однозначную интерпретацию и извлечение семантической информации, изначально закодированной в каждом токене. Фактически, это означает, что нейронная сеть всё больше опирается на сложные взаимодействия между признаками, а не на прямое кодирование исходного значения токена, что ставит под сомнение традиционные подходы к анализу и интерпретации внутренних представлений.
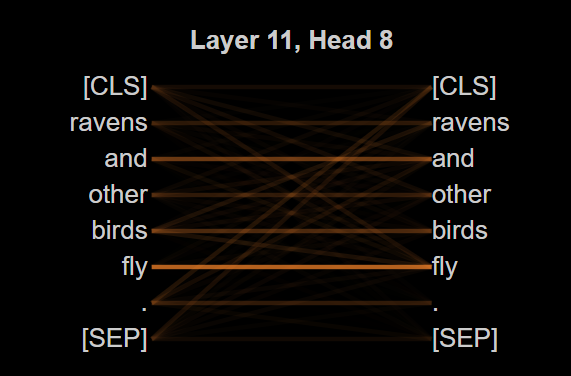
Анализ на основе механизмов внимания, хотя и является ценным инструментом, опирается на предположение о прямой связи весов внимания с важностью отношений между элементами. Однако, проведенные исследования показали, что даже при намеренной порче входных данных, коэффициент корреляции Спирмена ρ остается высоким. Это указывает на то, что предсказательная способность моделей не зависит напрямую от семантического содержания информации, а скорее от других факторов, таких как геометрическое расположение данных в пространстве признаков. Полученные результаты ставят под сомнение интерпретацию весов внимания как однозначного индикатора семантической релевантности и требуют более глубокого понимания механизмов, определяющих производительность современных моделей обработки естественного языка.
Исследования показали, что точность определения ближайших соседей (Neighborhood Accuracy@10) остаётся на конкурентном уровне даже при случайном перемешивании признаков входных данных. Этот неожиданный результат указывает на то, что модели, в особенности трансформеры, в значительной степени полагаются на геометрическое кластерирование векторов признаков, а не на семантическое понимание исходного текста. Иными словами, модель успешно идентифицирует похожие элементы, основываясь на их расположении в многомерном пространстве, даже если сами признаки, несущие семантическую информацию, были дезориентированы. Данный факт ставит под сомнение распространенное представление о том, что модели глубокого обучения «понимают» смысл текста, и подчеркивает важность изучения механизмов, лежащих в основе их способности к обобщению и классификации.
За Пределами Интерпретируемости: БЯМ и Будущее Вездесущего Искусственного Интеллекта
Все большее распространение больших языковых моделей (БЯМ) в системах периферийного искусственного интеллекта и повсеместных вычислений требует разработки эффективных и надежных стратегий развертывания. В отличие от традиционных моделей, БЯМ характеризуются значительными вычислительными затратами и потребностью в памяти, что создает серьезные проблемы для устройств с ограниченными ресурсами. В связи с этим, исследователи активно изучают методы квантования, дистилляции знаний и обрезки моделей, направленные на снижение их размера и повышение скорости работы без существенной потери точности. Разработка специализированного аппаратного обеспечения, оптимизированного для выполнения операций, характерных для БЯМ, также является ключевым направлением исследований. Успешное решение этих задач позволит интегрировать БЯМ в широкий спектр устройств, от носимой электроники до автономных транспортных средств, открывая новые возможности для интеллектуальных сервисов и приложений.
В то время как понимание принципов работы больших языковых моделей (БЯМ) остается важной задачей, их ключевой силой является способность к абстракции — применению полученных знаний к новым, ранее не встречавшимся ситуациям. БЯМ не просто запоминают данные, но и выявляют общие закономерности, позволяя им успешно решать задачи, которые явно не были предусмотрены в процессе обучения. Этот процесс абстракции позволяет моделям обобщать информацию и адаптироваться к различным контекстам, что особенно важно в задачах, связанных с обработкой естественного языка и искусственным интеллектом, где разнообразие входных данных может быть чрезвычайно велико. Способность к абстракции открывает новые возможности для применения БЯМ в областях, требующих гибкости и адаптивности, таких как автоматизация процессов, анализ данных и создание интеллектуальных систем.
Продолжающиеся исследования в области интерпретируемости и совершенствования архитектур больших языковых моделей (БЯМ) представляют собой ключевой фактор для раскрытия их полного потенциала в разнообразных практических приложениях. Усилия, направленные на понимание процессов принятия решений внутри БЯМ, позволят не только повысить доверие к ним, но и выявить и устранить предвзятости. Параллельно, разработка более эффективных и специализированных архитектур, таких как модели с разреженными связями или адаптивными механизмами внимания, позволит снизить вычислительные затраты и повысить скорость работы, делая БЯМ доступными для развертывания на периферийных устройствах и в системах с ограниченными ресурсами. Сочетание этих двух направлений — повышение прозрачности и оптимизация производительности — откроет путь к созданию интеллектуальных систем, способных решать сложные задачи в медицине, образовании, робототехнике и других областях, существенно расширяя границы возможностей искусственного интеллекта.
Исследование показывает, что общепринятые методы интерпретации больших языковых моделей часто оказываются ненадежными, что подтверждает идею о том, что архитектура — это способ откладывать хаос. Анализ внимания и вывод свойств на основе векторных представлений могут приводить к ошибочным результатам из-за артефактов в данных и методологических недостатков. Как однажды заметил Джон Маккарти: «Всякий, кто пытается предсказать будущее, обречен на провал, но это не должно мешать нам пробовать». Эта фраза отражает суть проблемы: стремление понять внутреннюю работу сложных систем неизбежно сопряжено с неопределенностью, но отказ от попыток анализа не приведет к лучшему результату. Порядок, как кеш между двумя сбоями, не гарантирует стабильности, а лишь откладывает неизбежное.
Что дальше?
Представленная работа демонстрирует, что привычные инструменты «интерпретируемости» больших языковых моделей — анализ внимания, изучение векторных представлений — часто оказываются лишь иллюзией понимания. Это не ошибка в реализации конкретных методов, а закономерность, присущая любой попытке «разобрать» сложную систему на части. Система — это не машина, которую можно починить, а сад: чем больше копаешься в корнях, тем меньше понимаешь, как он растёт.
Предлагать новые методы интерпретации — всё равно что пытаться построить более точную карту лабиринта, не понимая, что лабиринт постоянно меняется. Более продуктивным представляется отказ от поиска «объяснений» и переход к изучению поведения модели как целостной системы. Важнее не то, как модель пришла к ответу, а то, какие ответы она даёт в различных ситуациях, и как эти ответы влияют на окружающий мир.
Устойчивость системы не в изоляции компонентов, а в их способности прощать ошибки друг друга. Вместо того чтобы стремиться к идеальной интерпретируемости, необходимо научиться создавать модели, которые способны самодиагностироваться, адаптироваться к меняющимся условиям и, главное, нести ответственность за свои действия. Попытки «понять» их — это лишь отсрочка неизбежного.
Оригинал статьи: https://arxiv.org/pdf/2601.22928.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовый оптимизатор: Новый подход к сложным задачам
- Кванты в Финансах: Не Шутка!
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Разделяй и властвуй: Новый подход к классификации текстов
- Ветропарки и квантовые вычисления: оптимизация без лишних кубитов
- Многокритериальная оптимизация: взгляд на народные методы
- Как нейросеть предсказывает форму белка: взгляд под капот ESMFold
2026-02-03 06:00