Автор: Денис Аветисян
Новая методика позволяет значительно снизить склонность крупных визуально-языковых моделей к галлюцинациям, то есть к выдумыванию несуществующих объектов на изображениях.

Предложена тренировочная схема NoLan, динамически подавляющая влияние языковых априорных знаний во время работы модели для повышения точности и надежности визуального анализа.
Визуально-языковые модели нового поколения, несмотря на впечатляющие возможности, склонны к «галлюцинациям» — генерации объектов, отсутствующих на входном изображении. В работе ‘NoLan: Mitigating Object Hallucinations in Large Vision-Language Models via Dynamic Suppression of Language Priors’ предложен метод NoLan, направленный на смягчение этой проблемы путем динамического подавления языковых априорных знаний в процессе декодирования. Эксперименты показали, что именно сильные языковые предубеждения являются основной причиной возникновения галлюцинаций, и разработанный фреймворк NoLan позволяет существенно повысить точность моделей, таких как LLaVA-1.5 и Qwen-VL, без дополнительного обучения. Возможно ли дальнейшее улучшение мультимодального рассуждения за счет более тонкой калибровки языковых априорных знаний и адаптации к специфике различных задач?
Иллюзия Реальности: Объективные Галлюцинации в Многомодальных Моделях
Современные многомодальные модели, объединяющие зрение и язык, демонстрируют впечатляющую способность понимать и описывать изображения. Однако, несмотря на значительный прогресс, эти модели подвержены феномену, известному как “объективные галлюцинации” — спонтанному генерированию описаний объектов, которых фактически нет на представленном изображении. Данное явление представляет собой серьезную проблему, поскольку подрывает доверие к результатам работы модели и ограничивает ее применимость в критически важных областях, требующих высокой точности и надежности визуального анализа. Способность модели «видеть» несуществующие объекты ставит под вопрос ее способность к достоверному восприятию реальности и требует дальнейших исследований для разработки методов смягчения или устранения этой проблемы.
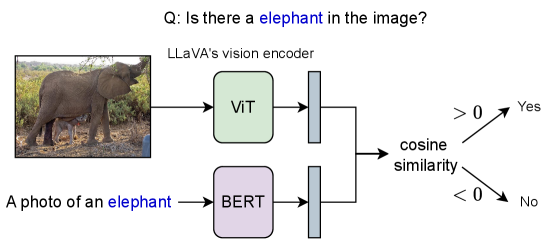
Явление “галлюцинаций” объектов в больших визуально-языковых моделях (LVLM) обусловлено предвзятостями, заложенными в языковой декодер. Эти предвзятости проявляются в виде так называемых “языковых априорных знаний” — склонности модели генерировать описания, основанные не на фактическом визуальном содержании изображения, а на статистических закономерностях, усвоенных из огромных текстовых корпусов. По сути, декодер, стремясь к правдоподобности, может “дорисовать” несуществующие объекты, если их упоминание статистически более вероятно в языке, чем отсутствие таковых. Это означает, что модель, даже располагая корректной информацией от визуального энкодера, может отдавать предпочтение лингвистической вероятности, что приводит к ложным положительным результатам в описаниях изображений и снижает надежность системы.
Несмотря на стремление визуальных энкодеров обеспечить соответствие языка визуальной реальности, предварительные языковые установки могут подавлять точное восприятие, приводя к ложным срабатываниям в описаниях. Визуальный энкодер, предназначенный для «заземления» лингвистической информации в визуальном контексте изображения, оказывается не в силах противостоять предвзятостям, заложенным в языковом декодере. Это означает, что модель может сгенерировать описание объекта, которого фактически нет на изображении, поскольку языковые приоритеты диктуют, что определённые объекты более вероятны, чем другие, даже при отсутствии соответствующих визуальных доказательств. В результате, даже если визуальный энкодер предоставляет точную информацию о содержимом изображения, языковой декодер может «переписать» её, добавив объекты, которые, по его мнению, должны присутствовать, что приводит к появлению галлюцинаций.
Понимание и смягчение феномена галлюцинаций — склонности больших визуально-языковых моделей (LVLM) к описанию отсутствующих объектов — имеет решающее значение для их надежного применения в реальных условиях. Наличие ложных утверждений в описаниях изображений может привести к серьезным последствиям в критически важных областях, таких как автономное вождение, медицинская диагностика и системы безопасности. Поэтому, разработка методов, позволяющих уменьшить влияние “языковых априорных знаний” и обеспечить более точное соответствие между визуальным входом и языковым выходом, является приоритетной задачей для исследователей. Эффективное снижение частоты галлюцинаций не только повысит доверие к LVLM, но и откроет новые возможности для их использования в широком спектре приложений, где точность и надежность являются первостепенными.

NoLan: Подавление Приоров для Согласованности Зрения и Языка
NoLan представляет собой фреймворк, не требующий предварительного обучения, разработанный для уменьшения эффекта галлюцинаций объектов в задачах, объединяющих зрение и язык. Основной принцип работы NoLan заключается в прямом подавлении так называемых “языковых априорных знаний” (Language Priors) — предвзятых представлений модели о мире, которые могут приводить к генерации объектов, не соответствующих визуальному входу. Вместо модификации весов модели, NoLan динамически корректирует процесс декодирования, уменьшая вероятность токенов, не подтверждаемых визуальной информацией, и тем самым повышая согласованность между языковым описанием и визуальным контекстом. Это позволяет снизить частоту появления ложных объектов в генерируемых описаниях без необходимости переобучения модели.
NoLan использует стратегию Contrastive Decoding для корректировки вероятностного распределения при генерации текста. Данный подход заключается в динамической настройке вероятностей токенов, отдавая предпочтение тем, которые согласуются с визуальными данными. В процессе декодирования, вероятность токенов, не подтверждаемых визуальным контекстом, снижается, а вероятность токенов, соответствующих визуальной информации, повышается. Это позволяет системе генерировать описания, более тесно связанные с изображением, и минимизировать генерацию галлюцинаций — объектов или атрибутов, не присутствующих на изображении. Фактически, Contrastive Decoding действует как фильтр, отсеивающий нерелевантные или противоречивые токеновые предсказания.
В основе NoLan лежит использование расхождения Кульбака-Лейблера (KL Divergence) D_{KL}(P||Q) для количественной оценки различий между мультимодальным (зрение + язык) и унимодальным языковым распределениями вероятностей. KL Divergence измеряет, насколько одно распределение вероятностей отличается от другого, при этом учитывается информация, теряемая при использовании Q для аппроксимации P. В контексте NoLan, P представляет собой совместное распределение вероятностей, полученное на основе визуального и языкового ввода, а Q — распределение вероятностей, сгенерированное исключительно на основе языкового запроса. Минимизация этого расхождения позволяет количественно оценить и снизить влияние априорных языковых знаний, не подтвержденных визуальными данными, что способствует более точному и обоснованному генерированию текста.
Механизм NoLan снижает влияние не подкрепленных априорных знаний (приоров) в процессе генерации языка путем минимизации расхождения Кульбака-Лейблера (KL Divergence) между мультимодальным (зрение + язык) и унимодальным языковым распределениями. Уменьшение этого расхождения позволяет ‘заземлить’ процесс генерации, то есть сделать его более зависимым от визуального входа и менее подверженным влиянию предвзятых языковых моделей. По сути, минимизация KL Divergence заставляет языковую модель генерировать описания, которые более соответствуют наблюдаемым визуальным данным, тем самым уменьшая вероятность генерации галлюцинаций об объектах, не присутствующих на изображении.

Проверка Реальности: Оценка Эффективности NoLan
Для оценки эффективности NoLan использовался ряд общепринятых бенчмарков, специализирующихся на выявлении и количественной оценке галлюцинаций объектов в задачах визуального вопросно-ответного взаимодействия. В частности, применялись MMHAL-BENCH, MM-Vet, MME и POPE. Эти бенчмарки разработаны для строгого тестирования способности модели корректно идентифицировать объекты на изображениях и избегать генерации неверных или несуществующих объектов в своих ответах, что позволяет получить объективную оценку надежности и точности системы.
В ходе экспериментов с моделями LLaVA, InstructBLIP и Qwen-VL было установлено, что NoLan последовательно снижает частоту галлюцинаций на стандартных бенчмарках. В частности, на бенчмарке POPE, NoLan показал прирост точности до 8.38% по сравнению с базовыми показателями. Данный результат демонстрирует эффективность NoLan в выявлении и подавлении неверных описаний объектов, повышая надежность генерируемых ответов и снижая вероятность ложных утверждений.
В ходе оценки NoLan на бенчмарке POPE было зафиксировано улучшение показателя F1 на 8.78%. Кроме того, при тестировании на модели Qwen2.5-VL 3B NoLan продемонстрировал точность в 90.33%. Эти результаты подтверждают способность NoLan повышать надежность и качество генерируемых описаний, снижая вероятность галлюцинаций и обеспечивая более точное соответствие сгенерированного контента исходным данным.
Эффективность NoLan подтверждена в отношении различных типов галлюцинаций, что способствует повышению надежности и достоверности генерируемых описаний. Система демонстрирует способность снижать частоту возникновения как семантических ошибок, так и фактических неточностей в ответах мультимодальных моделей. Это достигается за счет улучшения способности NoLan различать реальные объекты и артефакты, возникающие в процессе генерации, что в конечном итоге приводит к более корректным и заслуживающим доверия результатам, особенно в задачах, требующих высокой точности и детализации визуального контента.
В ходе сравнительного анализа производительности, NoLan продемонстрировал наиболее высокую скорость инференса, составляя 0.6075 секунды на токен. Этот показатель превосходит результаты, полученные при использовании альтернативных методов, что делает NoLan эффективным решением для приложений, требующих обработки данных в режиме реального времени и снижения задержек при генерации описаний. Высокая скорость инференса достигается за счет оптимизации алгоритмов и архитектуры фреймворка, что позволяет оперативно обрабатывать большие объемы данных и предоставлять быстрый отклик.
За Гранью Смягчения: К Надежному Искусственному Интеллекту Зрения и Языка
Подавление объектных галлюцинаций является критически важным фактором для внедрения визуально-языковых моделей (LVLM) в приложениях, связанных с безопасностью, таких как робототехника, автономная навигация и медицинский анализ изображений. В этих областях даже незначительные ошибки в распознавании объектов могут привести к серьезным последствиям. Например, в робототехнике неверная идентификация препятствия может привести к столкновению, а в медицинской диагностике — к ошибочному постановке диагноза. Поэтому, разработка методов, позволяющих минимизировать и устранять ложные распознавания, является необходимым условием для обеспечения надежности и безопасности этих систем, открывая путь к более ответственному и эффективному использованию искусственного интеллекта в критически важных сферах.
Особенностью NoLan является его способность к адаптации к существующим моделям без необходимости дополнительного обучения. Это значительно упрощает процесс внедрения и снижает вычислительные затраты, что особенно важно для широкого применения в различных областях. В отличие от традиционных подходов, требующих трудоемкой перенастройки, NoLan позволяет оперативно повысить надежность систем, работающих с визуальной и языковой информацией, без значительных инвестиций в ресурсы. Такая гибкость способствует ускорению разработки более устойчивых и заслуживающих доверия моделей искусственного интеллекта, делая их доступными для большего числа исследователей и разработчиков.
Повышение надежности мультимодальных моделей «зрение-язык» открывает новые перспективы для продуктивного взаимодействия человека и искусственного интеллекта, а также для оптимизации процессов принятия решений. Устранение галлюцинаций и повышение точности ответов моделей NoLan позволяет создавать системы, которым можно доверять в критически важных сферах, таких как совместная робототехника и анализ медицинских изображений. Более надежные модели способны предоставлять более релевантную и обоснованную информацию, что, в свою очередь, позволяет людям принимать более взвешенные и эффективные решения, опираясь на проверенные данные и экспертные оценки, дополненные возможностями искусственного интеллекта. Это способствует созданию более безопасных, эффективных и удобных систем, адаптированных к потребностям человека.
Перспективы развития NoLan направлены на расширение спектра устраняемых галлюцинаций в моделях, работающих с визуальной и языковой информацией. Исследователи планируют не ограничиваться подавлением лишь отдельных видов «видений», но и разработать методы борьбы с более сложными и труднообнаружимыми искажениями. Параллельно ведется работа над углублением согласованности между визуальным восприятием и генерируемым текстом, что позволит моделям не только избегать выдумывания несуществующих объектов, но и более точно описывать реальные сцены. Улучшение этой взаимосвязи является ключевым шагом к созданию действительно надежных и предсказуемых систем искусственного интеллекта, способных эффективно взаимодействовать с человеком и принимать обоснованные решения.

Исследование представляет собой элегантное решение проблемы галлюцинаций объектов в больших визуально-языковых моделях. Авторы предлагают NoLan — framework, который, не требуя дополнительного обучения, подавляет языковые априорные знания во время вывода, тем самым повышая точность генерируемого визуального контента. В этой работе наблюдается гармония между эффективностью и надежностью, что делает её значимым вкладом в область мультимодального рассуждения. Как однажды заметил Ян Лекун: «Машинное обучение — это программирование, в котором вы не программируете, а обучаете». Данное исследование демонстрирует, что даже без явного программирования, можно достичь впечатляющих результатов, обучая модели эффективно подавлять нежелательные предубеждения и генерировать более реалистичные и правдивые изображения.
Куда Далее?
Представленная работа, безусловно, вносит ясность в проблему иллюзорных объектов, возникающих в больших визуально-языковых моделях. Однако, элегантность решения не должна заслонять глубину нерешенных вопросов. Подавление языковых априорных знаний — эффективный, но не панацеальный подход. Остается открытым вопрос о том, как добиться истинной гармонии между визуальным восприятием и лингвистическим описанием, не прибегая к грубому подавлению одного ради другого. Плохой дизайн кричит, а хорошее решение шепчет — в данном случае, шепот нуждается в усилении.
Будущие исследования должны сосредоточиться не только на устранении галлюцинаций, но и на понимании их природы. Почему модель склонна к «выдумыванию»? Является ли это следствием неполноты данных, недостаточной сложности архитектуры или фундаментальным ограничением самого подхода к мультимодальному обучению? Поиск ответа на эти вопросы потребует смелых экспериментов и, возможно, переосмысления базовых принципов моделирования.
Наконец, нельзя забывать об эффективности. Подавление языковых априорных знаний — это компромисс между точностью и вычислительными затратами. Поиск более изящных решений, позволяющих достичь высокой точности без существенной потери производительности, представляется важной задачей для дальнейших исследований. Ведь каждое решение должно звучать, если настроено с вниманием.
Оригинал статьи: https://arxiv.org/pdf/2602.22144.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Квантовая самовнимательность на службе у поиска оптимальных схем
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
- Квантовый скачок: от лаборатории к рынку
- Виртуальная примерка без границ: EVTAR учится у образов
2026-02-26 22:37