Автор: Денис Аветисян
Исследователи представили комплексный бенчмарк и метод улучшения обработки инфракрасных изображений для современных мультимодальных моделей.

В статье представлен IF-Bench — эталонный набор данных для оценки понимания инфракрасных изображений, а также GenViP — техника адаптации моделей без переобучения, использующая генерацию визуальных подсказок.
Несмотря на значительный прогресс в области мультимодальных больших языковых моделей, их способность к пониманию инфракрасных изображений остается малоизученной. В работе ‘IF-Bench: Benchmarking and Enhancing MLLMs for Infrared Images with Generative Visual Prompting’ представлен IF-Bench — первый качественный бенчмарк для оценки мультимодального понимания инфракрасных изображений, а также метод GenViP, позволяющий улучшить работу существующих моделей без дополнительного обучения. Исследование выявило ключевые факторы, влияющие на эффективность обработки инфракрасных изображений, и продемонстрировало существенное повышение производительности различных MLLM благодаря предложенному подходу. Возможно ли дальнейшее расширение области применения подобных методов адаптации для других типов данных и задач компьютерного зрения?
Инфракрасное зрение: вызов для мультимодальных моделей
Мультимодальные большие языковые модели (MLLM) становятся все более важными инструментами в различных областях, однако их способность к тонкой интерпретации инфракрасных изображений остается серьезной проблемой. В то время как эти модели демонстрируют впечатляющие результаты в обработке текста и изображений видимого спектра, уникальные характеристики теплового излучения — тонкие градации температур, отражающие скрытые процессы и объекты — представляют значительные трудности. MLLM часто испытывают затруднения в различении едва заметных тепловых сигнатур, что приводит к неточным интерпретациям и ограничивает их применение в таких критически важных областях, как техническое обслуживание, безопасность и медицинская диагностика. Несмотря на прогресс в области искусственного интеллекта, способность модели “видеть” и понимать инфракрасные изображения требует дальнейшего развития и специализированных подходов к обучению.
Существующие оценочные наборы данных, предназначенные для проверки возможностей больших мультимодальных языковых моделей (MLLM) в интерпретации инфракрасных изображений, зачастую оказываются недостаточно сложными для адекватной оценки. Эти наборы, как правило, концентрируются на простых задачах распознавания объектов или базовой классификации, не затрагивая более тонкие аспекты понимания тепловых сигнатур и их контекста. Истинное “видение” и способность к рассуждению, необходимые для анализа инфракрасных данных, требуют от модели не просто идентификации объектов, но и интерпретации тепловых аномалий, понимания взаимосвязи между тепловыми паттернами и физическими процессами, а также учета влияния окружающей среды. Отсутствие в существующих бенчмарках подобных сложных сценариев не позволяет достоверно оценить, насколько хорошо MLLM действительно “видят” и могут логически обрабатывать информацию, содержащуюся в тепловых изображениях, что препятствует прогрессу в области разработки интеллектуальных систем анализа инфракрасных данных.
Традиционные методы компьютерного зрения, разработанные для обработки изображений в видимом спектре, оказываются недостаточно эффективными при анализе инфракрасных снимков. Это связано с фундаментальными различиями в характеристиках и распределении данных. В то время как видимые изображения отражают свет, инфракрасные изображения фиксируют тепловое излучение, что приводит к иному формированию объектов и текстур. Стандартные алгоритмы, настроенные на распознавание краев, цветов и форм в видимом свете, сталкиваются с трудностями при интерпретации тепловых контрастов и градиентов. Более того, инфракрасные изображения часто характеризуются более высоким уровнем шума и меньшим разрешением, что усугубляет проблему. В результате, применение существующих подходов к инфракрасным данным требует значительной адаптации и перенастройки, а зачастую и разработки принципиально новых методов анализа.

IF-Bench: новый стандарт оценки инфракрасного зрения
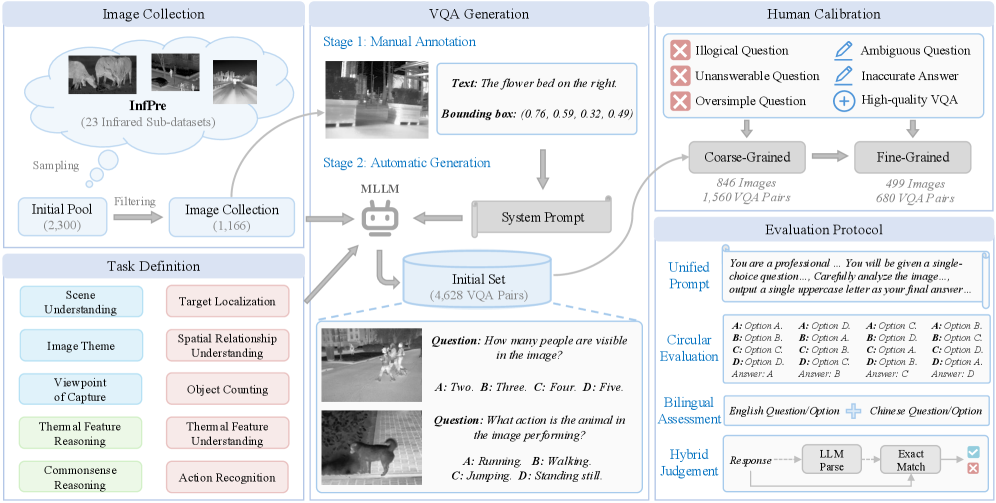
IF-Bench представляет собой комплексный оценочный набор данных для мультимодальных больших языковых моделей (MLLM), специализирующийся на понимании изображений в инфракрасном диапазоне. Набор данных включает в себя разнообразные типы задач, предназначенные для оценки способности моделей интерпретировать и анализировать тепловые изображения. Он охватывает широкий спектр сценариев, начиная от базового распознавания объектов и заканчивая сложным анализом сцен, что позволяет всесторонне оценить производительность MLLM в задачах, связанных с инфракрасным зрением. В отличие от существующих бенчмарков, IF-Bench нацелен исключительно на оценку возможностей обработки тепловых данных, что делает его уникальным инструментом для развития и сравнения MLLM в данной области.
Бенчмарк IF-Bench включает в себя разнообразные категории задач, предназначенные для всесторонней оценки моделей мультимодального машинного обучения, работающих с инфракрасными изображениями. К ним относятся задачи грубого восприятия, охватывающие общую идентификацию объектов и сцен; задачи детального восприятия, требующие распознавания мелких деталей и атрибутов на тепловизионных снимках; и задачи визуального рассуждения, предполагающие логический анализ и выводы на основе представленных тепловых данных. Такая классификация позволяет оценить способность моделей к обработке информации различного уровня сложности и выявить их сильные и слабые стороны в контексте понимания инфракрасных изображений.
Ключевой особенностью IF-Bench является ориентация на сложные сценарии, требующие от моделей вывода и дедукции на основе тепловизионных данных. Бенчмарк включает в себя задачи, где для корректного ответа необходимо не просто распознать объекты на изображении, но и интерпретировать их тепловые характеристики, учитывать контекст и делать логические выводы о происходящем. Это подразумевает решение задач, выходящих за рамки простой классификации или обнаружения объектов, и требующих от моделей способности к более глубокому пониманию и анализу тепловых данных, например, определение функционального состояния оборудования по его тепловому профилю или распознавание замаскированных объектов по незначительным тепловым аномалиям.
GenViP: усиление производительности с помощью визуального подсказывания
Метод Generative Visual Prompting (GenViP) представляет собой новый подход к улучшению понимания изображений в инфракрасном диапазоне, основанный на преобразовании этих изображений в формат RGB. Данное преобразование позволяет использовать модели редактирования изображений, такие как Qwen-Edit-2509, с применением LoRA для оптимизации производительности. Преобразование в RGB облегчает обработку инфракрасных данных существующими моделями компьютерного зрения, разработанными для работы с визуальной информацией в видимом спектре, и позволяет извлекать более точную и полезную информацию из тепловых изображений.
Преобразование инфракрасных изображений в RGB в GenViP осуществляется с использованием моделей редактирования изображений, таких как Qwen-Edit-2509. Для достижения оптимальной производительности применяется метод тонкой настройки LoRA (Low-Rank Adaptation). LoRA позволяет адаптировать предварительно обученную модель Qwen-Edit-2509 к специфике задачи обработки инфракрасных изображений, минимизируя при этом вычислительные затраты и объем необходимых данных для обучения. Этот подход обеспечивает эффективную передачу знаний от общей модели редактирования изображений к задаче интерпретации тепловых данных, что существенно повышает точность и скорость обработки.
Использование двойного входного сигнала, включающего как инфракрасное (ИК), так и RGB-изображение, значительно повышает способность моделей к интерпретации тепловых данных и, следовательно, точность анализа. Сочетание информации из обоих спектров позволяет модели учитывать как тепловое излучение объекта, так и его визуальные характеристики в видимом свете. Это особенно важно в сложных сценариях, где тепловые сигнатуры могут быть неоднозначными или скрытыми, а визуальный контекст необходим для правильной интерпретации данных. Предоставление модели обоими типами входных данных позволяет ей строить более полные и точные представления об окружающей среде, что приводит к повышению общей производительности и надежности системы.
Включение текстовой априорной информации значительно улучшает интерпретацию изображений, предоставляя важный контекст для сложных сценариев. Дополнительное текстовое описание, сопровождающее инфракрасное изображение, позволяет модели понимать не только тепловые характеристики объекта, но и его природу, назначение или текущее состояние. Это особенно важно при анализе сложных сцен, где тепловые сигнатуры могут быть неоднозначными или требовать дополнительных знаний для правильной интерпретации. Такой подход позволяет модели более эффективно различать объекты и события, повышая точность и надежность анализа тепловизионных данных.
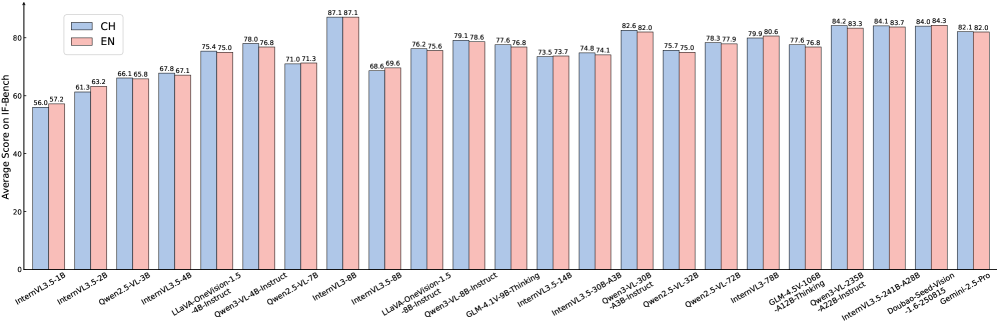
В ходе тестирования с использованием эталонного набора данных IF-Bench, модель Qwen3-VL-235B-A22B, функционирующая на основе метода GenViP, продемонстрировала результат в 84.4 балла. Данный показатель превосходит результаты закрытых моделей, таких как Doubao-Seed-Vision и Gemini-2.5-Pro, что подтверждает эффективность GenViP в задачах понимания изображений в инфракрасном диапазоне и выделяет Qwen3-VL-235B-A22B как лидера в данной области.

Проверка прогресса с помощью передовых моделей
Для всесторонней оценки возможностей современных мультимодальных моделей, таких как Qwen3-VL, InternVL3.5, Gemini-2.5 и Qwen2.5-VL, был проведен комплексный анализ с использованием эталонного набора данных IF-Bench. Данный набор позволяет оценить способность моделей к пониманию и интерпретации инфракрасных изображений, а также к решению различных задач, связанных с визуальной информацией. Строгая методология оценки, включающая разнообразные сценарии и метрики, позволила получить объективные данные о сильных и слабых сторонах каждой модели, что необходимо для дальнейшего развития и оптимизации алгоритмов обработки мультимодальных данных. Результаты этих оценок служат важным ориентиром для исследователей и разработчиков, стремящихся к созданию более эффективных и интеллектуальных систем искусственного зрения.
Оценка моделей, таких как Qwen3-VL и InternVL3.5, выявила значительное влияние архитектурных решений на их производительность в задачах, связанных с инфракрасным восприятием. В частности, применение архитектуры Mixture of Experts (MoE), подразумевающей использование нескольких “экспертных” подсетей, показало свою эффективность. Модели, использующие MoE, демонстрируют повышенную способность к обработке сложных данных и улучшенную точность в сравнении с традиционными архитектурами. Исследования показали, что MoE позволяет моделям более эффективно распределять вычислительные ресурсы, фокусируясь на наиболее релевантных аспектах входных данных, что в конечном итоге приводит к повышению общей производительности и более качественному пониманию инфракрасных изображений. Данный подход открывает перспективы для создания более мощных и специализированных моделей для анализа и интерпретации данных в различных областях, таких как медицинская диагностика и системы безопасности.
В рамках изучения возможностей мультимодальных моделей, особое внимание привлекли способности, связанные с так называемым «Режимом мышления». Данная функция, реализованная в некоторых моделях, позволяет им более эффективно анализировать и интерпретировать инфракрасные изображения, демонстрируя потенциал для улучшения понимания сложных сцен. Исследования показывают, что активация «Режима мышления» способствует более глубокому анализу данных, позволяя модели выявлять закономерности и детали, которые могут быть упущены при стандартной обработке. Это открывает новые перспективы в областях, где инфракрасное зрение играет ключевую роль, таких как безопасность, медицина и автоматизированное вождение, поскольку модель способна не просто распознавать объекты, но и делать обоснованные выводы на основе полученной информации.
Для обеспечения объективного сравнения различных моделей обработки изображений, критически важны методы циркулярной оценки. Суть этих методов заключается в случайном перемешивании порядка представления входных данных — изображений и связанных с ними вопросов — перед передачей их модели. Это позволяет нивелировать влияние так называемой позиционной предвзятости, когда модель демонстрирует повышенную точность при обработке данных, представленных в определенном порядке. Использование циркулярной оценки позволяет более достоверно оценить истинные возможности модели, исключая возможность завышения результатов из-за нежелательных закономерностей в порядке представления данных, и, таким образом, гарантирует справедливость сравнительного анализа различных архитектур и подходов к обработке визуальной информации.
Модель Qwen3-VL-235B-A22B продемонстрировала впечатляющий результат в 84.4 балла по шкале IF-Bench, что свидетельствует о значительном прогрессе в области мультимодального понимания. Этот показатель представляет собой относительное улучшение на 7% по сравнению с предыдущими моделями, достигнутое благодаря применению методики GenViP. Результаты подтверждают эффективность подхода GenViP в оптимизации архитектуры и алгоритмов обучения, позволяя модели Qwen3-VL-235B-A22B более точно и эффективно обрабатывать сложные запросы, связанные с визуальной и текстовой информацией. Такой прогресс открывает новые возможности для создания интеллектуальных систем, способных к глубокому пониманию окружающего мира.
Модель Qwen3-VL-8B продемонстрировала впечатляющую производительность, сравнимую с более крупными моделями InternVL3-78B и GLM-4.5V-106B-A12B, набрав 78.8 баллов по шкале IF-Bench. Этот результат указывает на эффективность архитектурных решений, реализованных в Qwen3-VL-8B, позволяющих достигать сопоставимых показателей качества, несмотря на значительно меньший размер. Такое соотношение между размером модели и производительностью открывает новые возможности для применения в условиях ограниченных вычислительных ресурсов и подчеркивает потенциал оптимизации моделей для решения задач анализа инфракрасных изображений.
В ходе оценки моделей, специализирующихся на анализе инфракрасных изображений, было установлено, что применение более строгих критериев оценки корректности приводит к значительному снижению показателей точности — в среднем более чем на 10% по сравнению со стандартными методами. Этот результат подчеркивает важность тщательного определения порогов приемлемости при оценке производительности моделей, поскольку даже незначительное ужесточение требований к точности может существенно повлиять на итоговые результаты. Подобная чувствительность к критериям оценки требует внимательного анализа и учета при сравнении различных моделей и алгоритмов, обеспечивая более объективную и надежную картину их реальных возможностей в задачах, связанных с интерпретацией инфракрасных данных.
Работа представляет собой очередной способ заставить существующие модели хоть как-то понимать данные, которые им не предназначены. IF-Bench — это не прорыв, а констатация факта: модели прекрасно справляются с тем, для чего их обучали, и отчаянно нуждаются в доработке, когда речь заходит о чём-то новом, например, об инфракрасных изображениях. GenViP — это элегантная, но временная мера, как и большинство «инноваций» в области машинного обучения. Как говорил Ян Лекун: «Глубокое обучение — это просто переоткрытие хорошо известных алгоритмов с использованием больших данных». По сути, это попытка заставить «костыль» работать немного лучше, пока не появится новый «костыль».
Что дальше?
Представленный IF-Bench, как и любой новый бенчмарк, неизбежно станет очередным полем битвы для оптимизаторов и трюкачей. Очевидно, что достижение лидерства на нём не гарантирует реального понимания инфракрасных изображений — лишь умение «обмануть» метрики. Более того, стоит задуматься, не станет ли он просто ещё одним уровнем сложности для тех, кто пытается решить действительно важные задачи, а не гоняться за цифрами. Каждая «революция» в области MLLM — это просто ещё один слой абстракции, скрывающий старые проблемы с обобщением и устойчивостью.
Метод GenViP, безусловно, интересен, но, как показывает опыт, любые «бесплатные» улучшения — это временное решение. Рано или поздно, для достижения реального прогресса, потребуется вложить ресурсы в переобучение моделей, адаптированных именно к инфракрасному спектру. Ведь, как известно, DevOps — это когда инженеры смирились с тем, что «магия» не работает вечно. И не стоит забывать, что самая лучшая «генерация подсказок» не заменит фундаментального понимания физики процессов, лежащих в основе инфракрасных изображений.
В конечном счёте, всё новое — это просто старое с худшей документацией. Поэтому, прежде чем бросаться в погоню за очередным «прорывом», стоит помнить: проблема не в моделях, а в данных и в том, как мы их используем. А задача — не научить машину видеть, а научиться правильно задавать ей вопросы.
Оригинал статьи: https://arxiv.org/pdf/2512.09663.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
2025-12-11 17:23