Автор: Денис Аветисян
Новая система ManuRAG позволяет точно отвечать на вопросы о производственных процессах, используя сразу несколько типов данных.
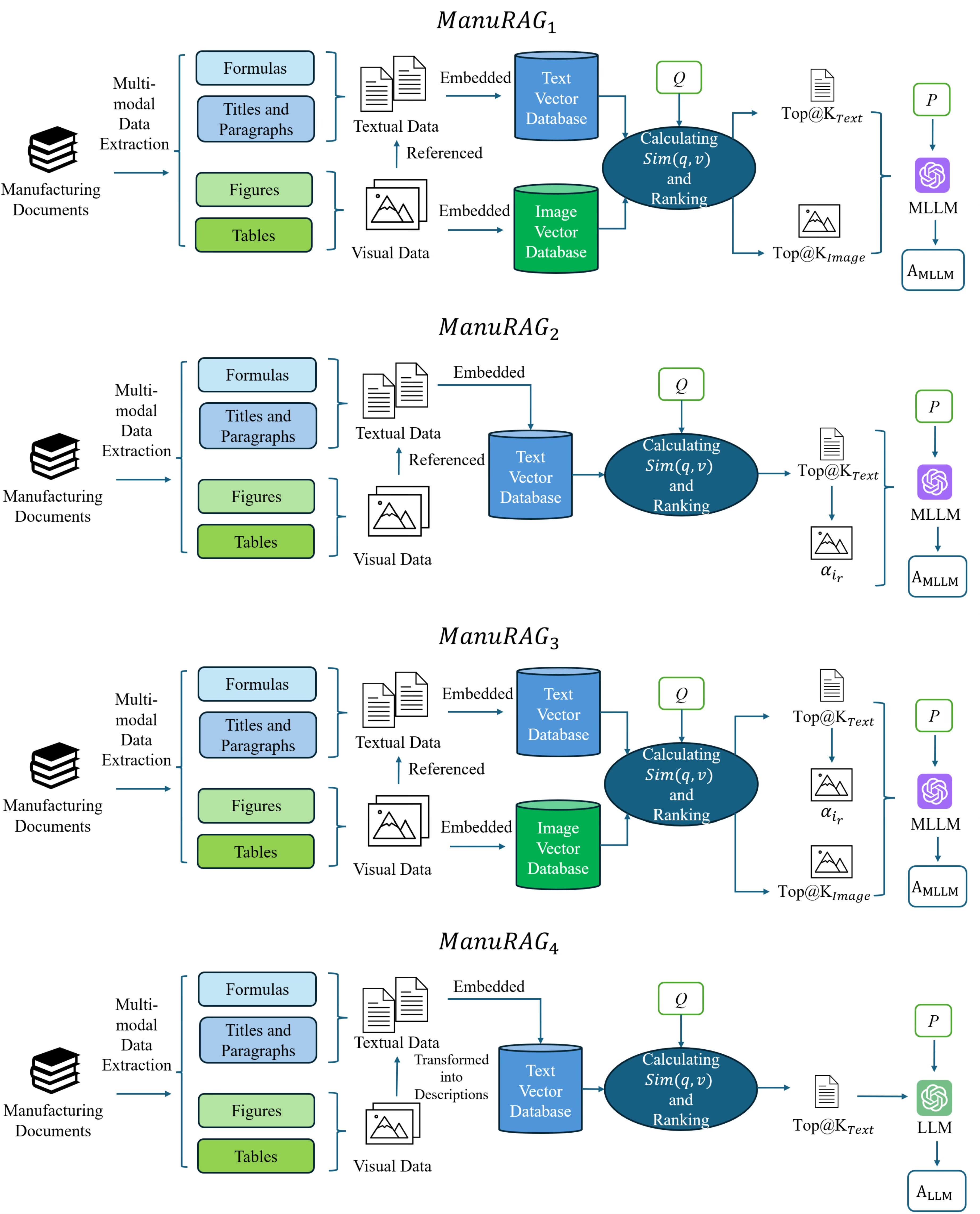
Представлен мультимодальный фреймворк ManuRAG для повышения точности ответов на вопросы в области производства с использованием технологии Retrieval Augmented Generation.
В условиях цифровизации производства, интеллектуальные системы ответов на вопросы, способные комплексно анализировать разнородные данные, становятся все более востребованными, однако существующие подходы часто оказываются недостаточно эффективными при работе с мультимодальной информацией. В данной работе представлена инновационная система ‘ManuRAG: Multi-modal Retrieval Augmented Generation for Manufacturing Question Answering’ — мультимодальный фреймворк, использующий метод Retrieval Augmented Generation для повышения точности, надежности и интерпретируемости ответов на вопросы в области производства. Экспериментальные результаты демонстрируют, что ManuRAG превосходит существующие методы на трех специализированных наборах данных, охватывающих математические задачи, вопросы с множественным выбором и анализ отзывов. Каковы перспективы применения ManuRAG и подобных систем в других областях, требующих обработки сложных, мультимодальных данных?
Вызов доступа к знаниям в производстве
Производственные процессы опираются на огромный объем сложной документации, представляющей собой смесь текстовых описаний, табличных данных, изображений и математических формул. Этот разнородный массив информации создает серьезные трудности при поиске необходимых сведений, становясь существенным препятствием для оперативного решения проблем и внедрения инноваций. Объем и сложность документации требуют значительных временных затрат на поиск и анализ, что замедляет производственные циклы и снижает общую эффективность. Необходимость быстрого доступа к актуальной информации является критически важной для поддержания конкурентоспособности и повышения качества продукции, однако традиционные методы поиска часто оказываются неэффективными в условиях постоянно растущего объема данных.
Традиционные методы поиска информации на производстве сталкиваются с серьезными трудностями при работе с разнородными данными. Обширный массив документации — включающий текстовые описания, таблицы, изображения и сложные формулы — часто оказывается плохо структурирован и разрознен. Это значительно замедляет процесс извлечения необходимых знаний и затрудняет решение возникающих проблем. Синтез информации из различных источников требует значительных временных затрат и может приводить к ошибкам, что, в конечном итоге, сдерживает инновации и снижает эффективность производственных процессов. Поэтому, потребность в более интеллектуальных системах доступа к знаниям, способных эффективно обрабатывать и объединять гетерогенные данные, становится всё более актуальной для современного производства.
Для решения даже простого производственного вопроса зачастую требуется кропотливый поиск по множеству разрозненных документов — от технических спецификаций и чертежей до отчетов об испытаниях и инструкций по эксплуатации. Этот процесс, требующий значительных временных затрат и усилий, существенно замедляет решение проблем и препятствует внедрению инноваций. Становится очевидной необходимость в интеллектуальных системах доступа к знаниям, способных автоматически извлекать, анализировать и синтезировать информацию из гетерогенных источников, предоставляя сотрудникам точные и своевременные ответы на их запросы. Такой подход позволит не только сократить время поиска, но и повысить качество принимаемых решений, способствуя более эффективному производству и конкурентоспособности предприятия.
RAG: Основа интеллектуального поиска ответов
Система RAG (Retrieval-Augmented Generation) объединяет возможности информационного поиска и генеративные способности больших языковых моделей (LLM) для создания надежного решения в области контроля качества на производстве. Традиционные LLM могут страдать от недостатка актуальных знаний или генерировать недостоверную информацию. RAG решает эту проблему, извлекая релевантные данные из корпоративной базы знаний (например, технической документации, отчетов об инцидентах, руководств по эксплуатации) и предоставляя их LLM в качестве контекста для формирования ответа. Это позволяет LLM генерировать более точные, обоснованные и актуальные ответы на вопросы, связанные с производственными процессами, дефектами, стандартами качества и другими критически важными аспектами.
В основе работы систем RAG лежит преобразование текстовой информации в числовые векторы, известные как текстовые эмбеддинги. Этот процесс позволяет представить смысл текста в виде многомерного вектора, отражающего его семантическое значение. Использование векторного представления позволяет осуществлять семантический поиск, находя документы или фрагменты текста, близкие по смыслу к запросу, даже если не содержат идентичных ключевых слов. Эффективность поиска обеспечивается благодаря вычислению косинусного сходства между векторным представлением запроса и векторами документов, что позволяет быстро извлекать наиболее релевантные фрагменты для последующего использования в генерации ответа.
Системы RAG (Retrieval-Augmented Generation) снижают склонность больших языковых моделей (LLM) к генерации неправдоподобной информации, известной как «галлюцинации», за счет привязки ответов к извлеченному из внешних источников контексту. Вместо того, чтобы полагаться исключительно на параметры, полученные в процессе обучения, LLM использует релевантные фрагменты текста, полученные в результате поиска по базе знаний. Это гарантирует, что ответы модели основаны на подтверждаемых фактах и снижает вероятность выдачи ложной или недостоверной информации, повышая общую точность и надежность системы ответов на вопросы.
Расширение RAG: Мультимодальное понимание для глубокого анализа
Стандартная архитектура RAG (Retrieval-Augmented Generation) расширяется до многомодальной версии (Multi-modal RAG), что позволяет обрабатывать не только текстовые данные, но и изображения, содержащиеся в производственной документации. Такое расширение обеспечивает возможность анализа как текстового описания процессов, так и визуальных элементов, таких как схемы, чертежи и фотографии оборудования. Интеграция изображений в процесс извлечения и генерации ответов позволяет системе понимать и отвечать на вопросы, требующие анализа визуальной информации, содержащейся в документах, что существенно повышает эффективность работы с технической документацией на производстве.
Преобразование визуальных данных в числовые векторы, известное как «встраивание изображений» (Image Embedding), осуществляется посредством использования моделей глубокого обучения, предварительно обученных на больших наборах изображений. В процессе встраивания, каждый пиксель изображения преобразуется в многомерный вектор, представляющий его характеристики. Эти векторы затем агрегируются для получения единого векторного представления всего изображения. Полученные векторы изображений, аналогичные векторным представлениям текста, могут быть использованы в алгоритмах семантического поиска для определения визуальной схожести и релевантности, что позволяет осуществлять поиск изображений по содержанию и интегрировать их в процессы извлечения информации наряду с текстовыми данными.
Интеграция визуальных данных с текстовой информацией значительно расширяет возможности понимания производственных процессов. Традиционные системы, оперирующие исключительно текстом, ограничены в ответах на вопросы, требующие анализа изображений, таких как идентификация компонентов на схемах, проверка правильности сборки или выявление дефектов на визуальном контроле. Добавление возможности обработки изображений позволяет системе находить ответы, требующие сопоставления визуальной информации с текстовым описанием, повышая точность и полноту предоставляемых сведений и обеспечивая поддержку более широкого спектра запросов, связанных с производственной документацией.
Оценка производительности системы: Точность, полнота и корректность
Для оценки качества извлечённой информации в многомодальной системе RAG применяются метрики “Точность контекста” и “Полнота контекста”. “Точность контекста” определяет, насколько релевантна извлечённая информация фактическому ответу на вопрос, минимизируя включение ненужных данных. В свою очередь, “Полнота контекста” измеряет, насколько полно система охватывает всю необходимую информацию для формирования корректного ответа. Обе эти метрики критически важны для обеспечения надежности и эффективности системы, поскольку позволяют оценить, насколько успешно она фильтрует и извлекает наиболее значимые данные из различных источников, включая текст и изображения, для предоставления точных и информативных ответов на сложные запросы.
Для оценки достоверности генерируемых ответов используется метрика “Фактическая корректность”, гарантирующая надежность и заслуживающее доверие представление информации. В ходе исследований, разработанная система ManuRAG, а именно ее версия ManuRAG4, продемонстрировала наивысший показатель “Фактической корректности” на наборе данных MathQ, превзойдя как модель GPT-4O, так и другие конфигурации систем извлечения и генерации ответов (RAG). Этот результат подтверждает способность ManuRAG4 предоставлять точные и обоснованные ответы, что является ключевым фактором для использования системы в сложных задачах, требующих высокой степени надежности предоставляемой информации.
Оценка производительности системы показала ее способность эффективно использовать как текстовые, так и визуальные данные для предоставления точных и всесторонних ответов на сложные вопросы, связанные с производством. В частности, конфигурация ManuRAG4 продемонстрировала наивысшую точность извлечения релевантного контекста (Context Precision) и общую точность (Accuracy) при решении задач с множественным выбором ответов (MCQ) среди всех протестированных моделей. Это свидетельствует о значительном превосходстве ManuRAG4 в извлечении необходимой информации из различных источников данных и предоставлении надежных ответов, что особенно важно для решения сложных производственных задач.
Усиление рассуждений с помощью CoT: Шаг к автономному поиску ответов
Интеграция принципа «Chain-of-Thought Reasoning» (CoT) с моделью GPT-4O в рамках архитектуры RAG (Retrieval-Augmented Generation) позволяет языковой модели не просто предоставлять ответы, но и раскрывать ход своих рассуждений. Этот подход значительно повышает прозрачность процесса принятия решений, поскольку модель демонстрирует, как она пришла к конкретному выводу, опираясь на извлеченные данные. В результате, пользователи получают не только ответ на вопрос, но и возможность оценить логичность и обоснованность этого ответа, что, в свою очередь, укрепляет доверие к системе и позволяет более эффективно выявлять потенциальные ошибки или неточности в рассуждениях модели. Такое сочетание технологий открывает путь к созданию интеллектуальных систем, способных не только решать задачи, но и объяснять свои решения.
Исследования показывают, что интеграция подхода “Chain-of-Thought” (CoT) значительно расширяет возможности больших языковых моделей (LLM) в синтезе информации из разнообразных источников. Вместо простого извлечения фактов, LLM, использующие CoT, способны последовательно анализировать данные из нескольких документов, выявлять взаимосвязи и строить логически обоснованные ответы. Этот процесс позволяет не только повысить точность предоставляемой информации, но и добавить ей глубину и нюансы, учитывая различные точки зрения и контексты. В результате, ответы становятся более полными, осмысленными и приближенными к человеческому способу рассуждения, что особенно важно при работе со сложными запросами и неоднозначными данными.
Комбинирование многомодального извлечения информации (RAG) с рассуждениями по цепочке мыслей (CoT) открывает новые горизонты для создания автономных систем контроля качества в производстве. Такой подход позволяет не просто находить ответы на вопросы, но и детально объяснять логику, лежащую в основе этих ответов, используя данные из различных источников — от текстовой документации до визуальных инспекций. Это критически важно для решения сложных производственных задач, требующих анализа нескольких факторов и принятия обоснованных решений. Благодаря этому, системы контроля качества смогут самостоятельно диагностировать проблемы, предлагать решения и адаптироваться к изменяющимся условиям производства, значительно повышая эффективность и снижая затраты на ручной контроль.
Исследование, представленное в ManuRAG, демонстрирует стремление к математической чистоте в обработке информации. Авторы подчеркивают важность точного извлечения релевантных данных из разнородных источников — текста, изображений, формул — для обеспечения корректности ответов на вопросы, касающиеся производства. Это перекликается с известным высказыванием Эдсгера Дейкстры: «Программирование — это не столько техника, сколько искусство структурирования мыслей». ManuRAG, по сути, структурирует мысли в виде эффективного механизма извлечения и генерации ответов, где каждая операция, будь то извлечение изображения или обработка текстовой формулы, направлена на достижение доказанной корректности результата. Особое внимание к контексту — как точности, так и полноте его извлечения — является ключевым элементом, подтверждающим стремление к алгоритмической ясности и надежности.
Что Дальше?
Представленная работа, исследующая возможности многомодального поиска и генерации для задач в производстве, несомненно, является шагом вперед. Однако, пусть N стремится к бесконечности — что останется устойчивым? Пока система демонстрирует эффективность в обработке текста, изображений и формул, фундаментальный вопрос о семантическом понимании и способности к логическим выводам остается открытым. Эффективность системы сильно зависит от качества извлеченных данных и точности сопоставления модальностей. Устойчивость к шуму и неполноте данных, столь характерным для реальных производственных сред, требует дальнейшего изучения.
Особое внимание следует уделить развитию методов, позволяющих не просто извлекать релевантную информацию, но и верифицировать ее достоверность. Простое увеличение объема данных не гарантирует повышение качества ответов. Необходимо разрабатывать алгоритмы, способные к критическому анализу и выявлению противоречий в различных источниках информации. Иначе, система рискует стать лишь эхо-камерой существующих ошибок.
В конечном итоге, истинная ценность подобных систем заключается не в способности отвечать на вопросы, а в способности задавать их. Переход от пассивного поиска информации к активному формированию гипотез и проведению экспериментов — вот куда следует двигаться. Только тогда мы сможем говорить о действительно интеллектуальных системах поддержки принятия решений в производстве.
Оригинал статьи: https://arxiv.org/pdf/2601.15434.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Метаболический профиль СДВГ: новый взгляд на диагностику
- Квантовая криптография: от теории к практике
- Лунный гелий-3: Охлаждение квантового будущего
- Робот, который видит, понимает и действует: новая эра общего назначения
- Квантовые сети для моделирования молекул: новый подход
2026-01-24 06:52