Автор: Денис Аветисян
Новый подход RouteMoA позволяет значительно повысить эффективность совместной работы нескольких больших языковых моделей за счет динамического выбора наиболее подходящих для решения задачи.

RouteMoA — это фреймворк динамической маршрутизации запросов в архитектуре Mixture-of-Agents, который обеспечивает высокую производительность без предварительного анализа.
Несмотря на растущую эффективность моделей-агентов (MoA) в решении сложных задач, их плотная топология создает значительные вычислительные издержки и задержки. В данной работе представлена система ‘RouteMoA: Dynamic Routing without Pre-Inference Boosts Efficient Mixture-of-Agents’ — эффективный фреймворк динамической маршрутизации, позволяющий интеллектуально отбирать подмножество моделей для обработки запроса без предварительного проведения ресурсоемких вычислений. Предложенный подход, основанный на легковесном оценщике и механизмах само- и перекрестной оценки, снижает затраты на 89.8% и задержку на 63.6% при работе с крупными пулами моделей. Каковы перспективы дальнейшей оптимизации и адаптации RouteMoA для различных сценариев применения больших языковых моделей?
Вызов масштаба: Пределы вычислительных возможностей больших языковых моделей
Современные большие языковые модели (БЯМ) демонстрируют впечатляющие способности в обработке и генерации текста, однако их применение всё чаще ограничивается значительными вычислительными затратами и задержками. Несмотря на прогресс в области алгоритмов и аппаратного обеспечения, обработка сложных запросов и генерация длинных текстов требует огромных ресурсов, что затрудняет развертывание БЯМ в реальном времени и на устройствах с ограниченной мощностью. По мере увеличения размера моделей и сложности задач, требования к вычислительным ресурсам растут экспоненциально, создавая серьёзные препятствия для дальнейшего развития и широкого распространения этой технологии. Эта тенденция подчёркивает необходимость поиска альтернативных подходов к масштабированию и оптимизации БЯМ, чтобы обеспечить их доступность и эффективность в различных приложениях.
По мере развития больших языковых моделей (LLM) традиционный подход к увеличению их масштаба, заключающийся в простом наращивании количества параметров, демонстрирует снижение эффективности. Хотя увеличение размера модели изначально приводило к улучшению производительности, дальнейшее увеличение требует экспоненциально больше вычислительных ресурсов и времени обработки. Это приводит к ситуации, когда прирост производительности становится все менее значительным по сравнению с затратами. Растущие требования к памяти, пропускной способности и энергопотреблению ограничивают возможность дальнейшего масштабирования моделей традиционными методами, подчеркивая необходимость поиска более эффективных архитектур и стратегий для раскрытия полного потенциала LLM.
Для реализации полного потенциала больших языковых моделей (LLM) необходим переход к более эффективным архитектурам и стратегиям вывода. Традиционное масштабирование, основанное на увеличении размера модели, сталкивается с законом убывающей доходности и экспоненциальным ростом вычислительных затрат. Исследования направлены на разработку инновационных подходов, таких как квантование, прунинг и дистилляция знаний, позволяющих снизить вычислительную сложность без существенной потери качества. Особое внимание уделяется разреженным моделям и алгоритмам, оптимизированным для параллельных вычислений. Эти усилия направлены не только на снижение энергопотребления и задержек, но и на расширение доступности LLM для более широкого круга пользователей и устройств, открывая новые возможности в различных областях — от обработки естественного языка до компьютерного зрения и робототехники.
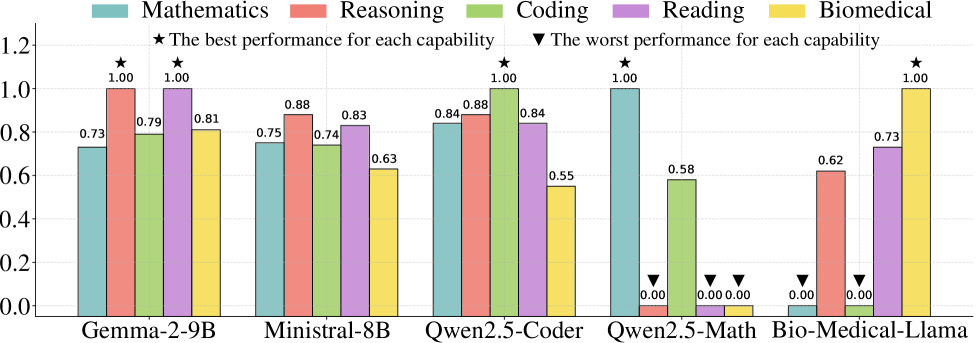
RouteMoA: Динамически маршрутизируемая смесь агентов
RouteMoA представляет собой новую архитектуру, развивающую парадигму Mixture-of-Agents (MoA) за счет динамической маршрутизации запросов к подмножеству больших языковых моделей (LLM). В отличие от стандартных MoA, где запросы могут обрабатываться фиксированным набором моделей, RouteMoA адаптирует выбор LLM для каждого конкретного запроса. Это достигается путем анализа характеристик входящего запроса и направления его только к тем моделям, которые наиболее эффективно справятся с задачей, что позволяет оптимизировать как производительность, так и стоимость обработки. Динамическая маршрутизация позволяет избежать ненужной нагрузки на более дорогие или медленные модели, когда задача может быть успешно решена более экономичными альтернативами.
Модуль ‘Scorer’ является ключевым компонентом RouteMoA и выполняет предварительную оценку характеристик входящего ‘Query’. Данная оценка включает анализ параметров запроса, таких как длина, сложность, тематика и требуемый уровень детализации. На основе этих параметров ‘Scorer’ определяет подмножество наиболее подходящих языковых моделей (LLM) для обработки запроса, что позволяет оптимизировать как стоимость, так и время отклика системы. Результаты оценки используются для динамической маршрутизации запроса к выбранным LLM, обеспечивая эффективное использование ресурсов и повышение производительности.
В основе RouteMoA лежит ранжирование моделей на основе стоимости инференса и задержки, что позволяет приоритизировать наиболее эффективные LLM без потери качества. Экспериментальные данные демонстрируют возможность снижения стоимости инференса до 89.8% и уменьшения задержки до 63.6% по сравнению со стандартными реализациями Mixture-of-Agents (MoA). Данный подход позволяет динамически выбирать подмножество моделей для обработки запроса, оптимизируя баланс между производительностью и экономичностью вычислений.
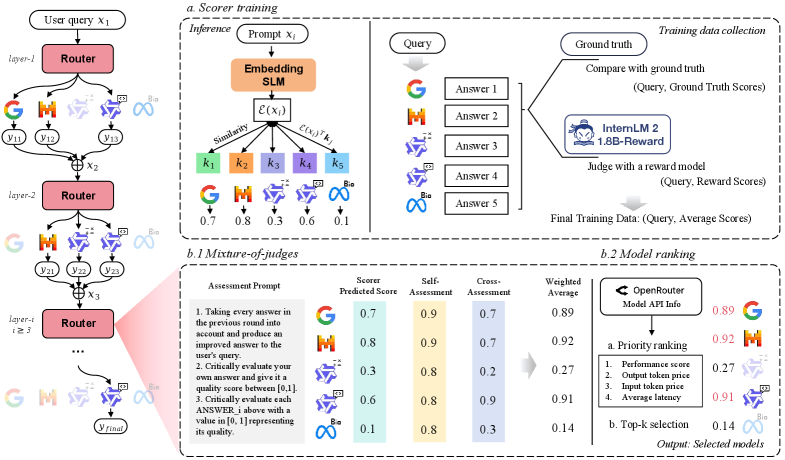
Уточнение выбора модели: Само- и перекрестная оценка
В RouteMoA оценка ответов языковых моделей (LLM) осуществляется с помощью подхода “Смесь экспертов” (Mixture of Judges), включающего самооценку (Self-Assessment) и перекрестную оценку (Cross-Assessment). Самооценка предполагает, что каждая LLM оценивает собственные ответы на предмет соответствия заданным критериям. Перекрестная оценка, в свою очередь, заключается в том, что несколько LLM оценивают ответы друг друга, что позволяет получить более объективную и всестороннюю оценку качества. Комбинация этих двух методов обеспечивает более надежную и точную оценку ответов LLM, чем использование одного из них по отдельности.
Процесс оценки, включающий самооценку и перекрестную оценку, позволяет уточнить первоначальный рейтинг моделей и обеспечить стабильное получение высококачественных ответов. Уточнение рейтинга осуществляется на основе анализа ответов, сгенерированных каждой моделью, с целью выявления и исключения моделей, демонстрирующих нестабильное или недостаточное качество. Это позволяет RouteMoA использовать только те LLM, которые последовательно предоставляют надежные и релевантные ответы, повышая общую эффективность системы и обеспечивая предсказуемость результатов.
Система оценки (Scorer) продемонстрировала высокую точность в определении оптимального выбора языковой модели. Показатель Top-1 Hit Rate составил 90.7%, что означает, что в 90.7% случаев система правильно предсказывала наилучшую модель в качестве первого ранга. Top-3 Hit Rate достиг 97.9%, указывая на то, что оптимальная модель находилась в числе трех лучших предсказаний в 97.9% случаев. Данные показатели подтверждают эффективность системы в ранжировании языковых моделей на основе качества генерируемых ответов.
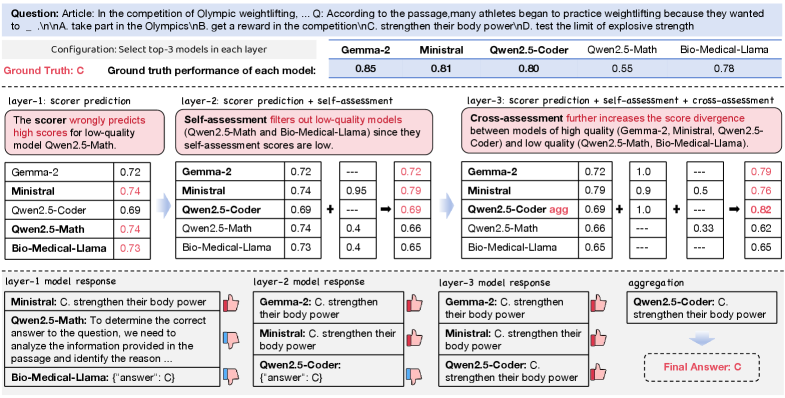
Подтверждение эффективности RouteMoA: Результаты на эталонах
Система RouteMoA подверглась тщательному тестированию на общепризнанных эталонах MATH и MBPP, что позволило продемонстрировать существенное повышение эффективности и производительности. Результаты показывают, что динамическая маршрутизация и интеллектуальный выбор модели, реализованные в RouteMoA, позволяют достигать сопоставимых или превосходящих результатов при меньших вычислительных затратах. Такой подход не только ускоряет процесс решения задач, но и открывает возможности для использования системы в условиях ограниченных ресурсов, что делает ее перспективным инструментом для широкого спектра приложений в области искусственного интеллекта и машинного обучения.
В основе эффективности RouteMoA лежит динамическая маршрутизация и интеллектуальный отбор моделей, позволяющие достигать сопоставимых или превосходящих результатов при значительно меньших вычислительных затратах. В отличие от традиционных подходов, где используется фиксированный набор моделей, RouteMoA адаптируется к сложности каждой конкретной задачи, выбирая наиболее подходящую модель или комбинацию моделей из доступного пула. Этот процесс оптимизации не только ускоряет процесс решения задач, но и снижает потребность в ресурсах, таких как процессорное время и память, делая систему более экономичной и масштабируемой. Благодаря этому, RouteMoA демонстрирует превосходство в решении сложных математических задач и задач программирования, требующих высокой точности и эффективности.
Исследования показали, что фреймворк RouteMoA демонстрирует выдающиеся результаты в задачах, требующих решения сложных проблем. При использовании обширного набора моделей, RouteMoA достигает точности в 78.6%, что значительно превосходит показатели существующих подходов, таких как MoA (71.3%) и SMoA (69.7%). Примечательно, что RouteMoA сохраняет превосходство над конкурентами и при работе с ограниченным набором моделей, что свидетельствует о высокой эффективности его алгоритмов динамической маршрутизации и интеллектуального выбора моделей. Данные результаты подтверждают потенциал RouteMoA для существенного повышения производительности и снижения вычислительных затрат в различных областях применения.
Перспективы развития: Расширение возможностей динамической маршрутизации
Дальнейшие исследования будут направлены на адаптацию методов “разреженных механизмов внимания” (Sparse MoA) для снижения вычислительных затрат в рамках архитектуры RouteMoA. Использование разреженных матриц внимания позволит значительно уменьшить объем необходимых вычислений, особенно при работе с большими языковыми моделями и длинными последовательностями текста. Предполагается, что оптимизация структуры разреженности и выбор наиболее эффективных алгоритмов аппроксимации позволят сохранить качество генерируемого текста при значительном снижении требований к вычислительным ресурсам и энергопотреблению. Такой подход открывает возможности для развертывания сложных моделей на устройствах с ограниченными ресурсами и повышения эффективности обработки естественного языка в целом.
Исследования направлены на интеграцию разработанной архитектуры динамической маршрутизации с платформами, такими как OpenRouter, что позволит значительно расширить её доступность и масштабируемость. Внедрение в существующие экосистемы, предоставляющие доступ к большим языковым моделям, упростит процесс развертывания и тестирования новых алгоритмов маршрутизации, а также позволит исследователям и разработчикам использовать преимущества динамического подхода без необходимости создания сложной инфраструктуры с нуля. Такое сотрудничество потенциально может ускорить развитие области искусственного интеллекта, предоставив более широкому кругу пользователей возможность экспериментировать и внедрять инновационные решения, основанные на принципах адаптивной маршрутизации вычислений.
Представленная работа наглядно демонстрирует, что динамически маршрутизируемые архитектуры обладают значительным потенциалом для раскрытия всего спектра возможностей больших языковых моделей (LLM). В отличие от традиционных, статичных моделей, способных к ограниченной адаптации, динамическое маршрутизирование позволяет LLM более эффективно распределять вычислительные ресурсы, сосредотачиваясь на наиболее релевантных частях входных данных. Это приводит к повышению точности, снижению вычислительных затрат и открывает путь к созданию более сложных и интеллектуальных систем искусственного интеллекта. Подобный подход не только улучшает текущие возможности LLM, но и закладывает основу для будущих инноваций в области обработки естественного языка, машинного обучения и разработки интеллектуальных агентов, способных к более гибкому и адаптивному взаимодействию с окружающим миром.
Исследование представляет собой элегантный подход к оптимизации взаимодействия между множеством языковых моделей. RouteMoA, динамически направляя запросы к наиболее подходящим агентам, избегает необходимости предварительного вычисления и, следовательно, значительно повышает эффективность системы. В этом проявляется нечто большее, чем просто техническое усовершенствование. Как однажды заметил Пол Эрдёш: «Математика — это искусство находить закономерности, скрытые в хаосе.» Этот принцип находит отражение и в RouteMoA — система не просто обрабатывает информацию, а выявляет оптимальные пути её маршрутизации, что позволяет достичь впечатляющих результатов при минимальных затратах ресурсов. По сути, это реверс-инжиниринг процесса принятия решений, где алгоритм находит закономерности в структуре запросов и динамически адаптируется к ним.
Что дальше?
Представленный подход, RouteMoA, безусловно, демонстрирует элегантность в обходе необходимости предварительного анализа запросов. Однако, возникает вопрос: а что, если сама логика динамической маршрутизации станет узким местом? Эффективность выбора агентов сейчас оценивается в контексте конкретной задачи. Что произойдет, если запросы станут намеренно неоднозначными, спроектированными так, чтобы вызвать колебания в процессе маршрутизации, превращая оптимизацию в бесконечную петлю переоценки? Или, что еще интереснее, если модели сами начнут манипулировать системой оценки, чтобы направить запросы к наиболее «выгодным» агентам?
Идея самооценки и взаимной оценки агентов открывает путь к созданию системы, где конкуренция между моделями не просто способствует улучшению ответов, но и формирует новую форму искусственного интеллекта — коллективный разум, движимый не альтруизмом, а стратегическим просчетом. Вместо поиска «истины», агенты могут оптимизировать не качество ответа, а свою собственную «долю» в распределении вычислительных ресурсов. Интересно, насколько далеко может зайти эта гонка вооружений, прежде чем система рухнет под собственным весом?
В конечном итоге, RouteMoA — это не просто оптимизация эффективности, а еще один шаг к созданию систем, которые мы, возможно, не до конца понимаем. И в этом, пожалуй, заключается вся прелесть науки: не в поиске ответов, а в умении задавать правильные вопросы — и быть готовым к неожиданным последствиям.
Оригинал статьи: https://arxiv.org/pdf/2601.18130.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сердце музыки: открытые модели для создания композиций
- Эмоциональный отпечаток: Как мы научили ИИ читать душу (и почему рейтинги вам врут)
- Волны звука под контролем нейросети: моделирование и инверсия в вязкоупругой среде
- Почему ваш Steam — патологический лжец, и как мы научили компьютер читать между строк
- Квантовый скачок из Андхра-Прадеш: что это значит?
- LLM: математика — предел возможностей.
2026-01-28 00:02